天融信AlphaFuzzer测试工具 使用教程
原文:http://blog.topsec.com.cn/ad_lab/alphafuzzer/
更新记录:
2015年7月30日 1.2
2015年7月23日 1.1
2015年7月13日 1.0
软件简介:
AlphaFuzzer是一款多功能的漏洞挖掘工具,到现在为止,该程序以文件格式为主。
1.0版本主要包含了:一个智能文件格式的漏洞挖掘框架。一个通用文件格式的fuzz模块。此外,他还包含了一个ftp服务器程序的fuzz模块。一个程序参数的fuzz模块。一些shellcode处理的小工具。
FileFuzz模块
功能简介:
FileFuzz模块即文件格式通用Fuzz模块。该模块可简单快速对文件格式处理类程序进行Fuzz。这类程序很多,包括各种播放器,阅读器,图片文档处理工具等等。首先,介绍一下程序简单功能。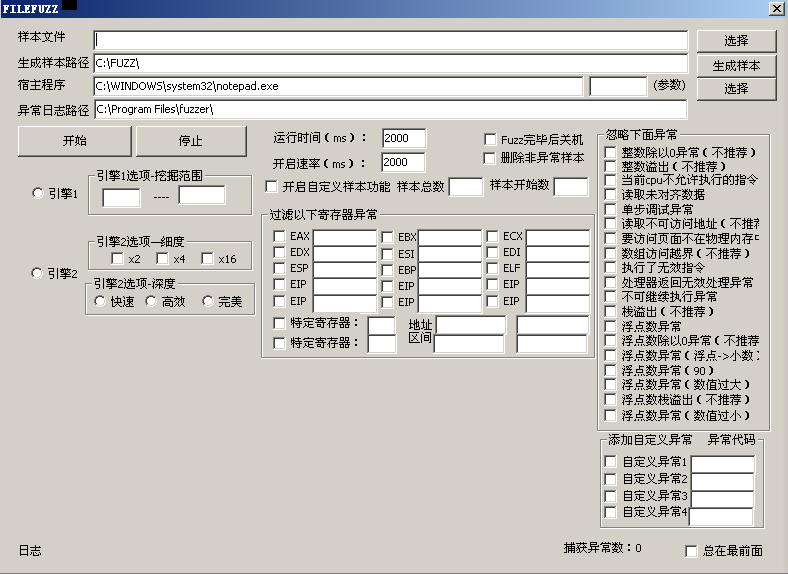
程序工作流程:
程序通过用户传给一个标准的样本文件,通过样本生成引擎对样本进行畸形变异。变异成大量畸形样本后再依次传给宿主程序来运行。运行时候监控程序运行状态,一旦程序运行发生异常我们就吧该样本和异常的简要信息放在我们的日志中,从而方便研究人员的后续研究与分析。下面解释一下各功能的细节。
样本文件:
既添加样本文件所在的路径,通过右面的“选择”按钮进行添加。
生成文件路径:
选择样本的生成文件路径,手动添加。注意所选磁盘空间的大小。
宿主程序:
要处理样本程序的所在路径,通过右面的“选择”按钮进行添加。右面的小编辑框内填写运行时候的参数(大部分情况下空着即可)。
异常日志路径:
存放异常日志以及异常文件的路径。
生成样本:
配置好后点击它即可生成样本。
引擎1:
对局部进行深入Fuzz的引擎,需要给一定的范围。该引擎一般用来处理文件头的某结构。范围不宜太大,否则会浪费很多时间。该引擎要求样本大小为16B-4MB.
引擎2:
对文件的整体部分进行Fuzz的引擎。这里有2个选项,一个是细度,一个是深度。
细度有3个按钮,分别是x2,x4,x16。通过多选可以满足1倍到128倍的选择。深度有3个按钮,分别是快速,高效,完美。不可以多选。完美效果最好,但是需要大量的时间,快速所需时间最少。通过选择我们可以把生成样本数量大致定位到500个到250万个区间。
该引擎要求样本大小为512B-4MB。
运行时间:
每一个样本开启后的运行时间,如果样本在这个时间内没有发现异常。那么样本将会被强迫关闭。
开启速率:
程序的开启速率。就是说程序每次经过这么多时间开启一个新样本。如果要程序单线程允许,开启速率=允许时间即可。但是由于现在的cpu都是多核心多线程的,所以在程序允许多线程的情况下,单线程运行是一种很浪费能源和浪费时间的工作,通过这个功能我们可以多线程运行,提高工作效率。
Fuzz完毕后关机:
工作完成后自动关机,节省能源。
删除非异常样本:
对没有问题的样本及时删除。
开启自定义样本功能:
通过这个功能我们可以让我们的程序处理别的程序生成的样本,也可以处理我们程序上次未处理完毕的样本,也可以用于多台pc机同时处理样本。
忽略以下异常:
忽略我们不关注的异常。
过滤以下寄存器异常:
程序在运行时候由于设计问题会报一些异常,对于一些异常我们对他并没有兴趣,可以选择忽略,从而关注我们有兴趣的异常。
总在最前面:
选择后程序就在最前面了,方便随时对程序进行操作。(尤其适用于高速多线程Fuzz)。
FTPFuzz模块
功能简介:
针对FTP服务器程序开发的一款Fuzz工具。可以简单方便快速的对FTP服务器进行Fuzz测试。
演示例子:
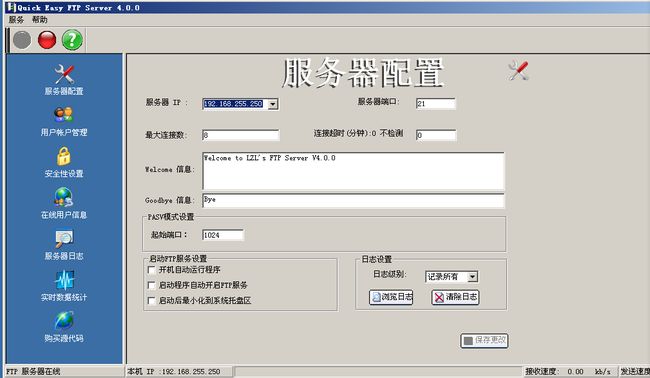
1首先,安装这个FTP服务器,配置好了并开启。
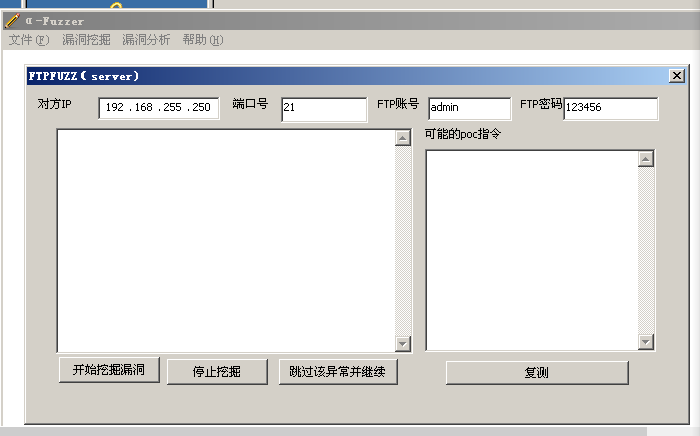
2 开启我们的Fuzzer,并设置。 配置好了点击开始挖掘漏洞
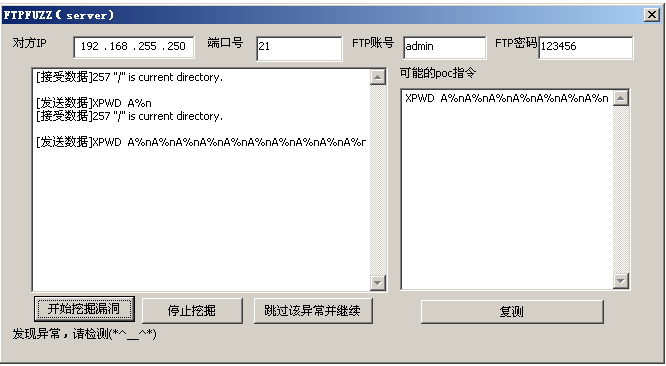
很快,程序就崩溃了。

程序退出后,FuzzER显示出了让程序崩溃的poc指令。
AgruFuzz模块
针对运行参数进行模糊测试的模块。选好程序路径和日志路径,即可对程序的运行参数进行模糊测试了。

智能Fuzz模块
代码规范:
函数类似于c语言的样子,每一个参数间用逗号相隔,函数末尾用分号表示。如果为空,则表示为0。一共支持4096行代码,每一行代码最长支持4096字节。字符串支持最长128字节。如果你要自行编辑代码,强烈建议使用一种可用于显示代码行数的编辑器。如010editor。并且要多添加注释信息。
函数定义:
_num:
用于表示一个数值,共有四个参数。 如_num,888,0,0,32;
参数1:表示这个数值的数。比如例子里面表示888.
参数2:表示该数值是否可变,0为不可变,1为可变。如果是可变,那么参数1则不进行解析。
参数3:表示大小尾。0表示小尾,1表示大尾。(小尾指低位数据存放在低位地址上,大尾则表示低位数据存放在高位地址上)。
参数4:数值的大小,支持8位,16位,32位3种类型。也就是1字节,2字节,4字节。
表示形式:
_num,1234567,0,0,32; 表示一个小尾,4字节的数值,值为1234567.
_num,1234567,,,32; 同上
_num,,1,,16; 表示一个2字节的可变数值。
_str:
用于表示一个字符串,共有3个参数。如_str,hello,1,0;
参数1:字符串数值。直接填写字符串即可。
参数2:字符串是否可变,0为不可以变化,1为长度不变,内容会变化,2为长度内容都会变化。
参数3:字符串的长度,如果是0,则是输入字符串的实际长度。
参数4:字符串前缀,前缀用来表示字符串的长度。如果不需要前缀,设置为0.如果需要前缀,可以设置成8,16,32.分别表示前缀大小为1,2,4字节。
参数5:前缀的大小尾。0表示小尾,1表示大尾。
_cal,addr:
用于计算一些数据的偏移。共有3个参数。如_cal,addr,32,0,3;
参数1:表示计算结果的位数,可选值为8,16,32.分别表示1,2,4字节。
参数2:表示计算结果的大小尾。0为小尾,1为大尾。
参数3:要计算的目标的函数序列号。上面的参数3是3,代表计算第三个函数的偏移。
_cal,size:
用于计算一些数据的大小,共有4个参数,如_cal,size,32,0,4,6;
参数1:表示计算结果的位数,可选值为8,16,32。分别代表1,2,4字节。
参数2:表示计算结果的大小尾,0为小尾,1为大尾。
参数3:要计算的开始函数(函数序列号)
参数4:要计算的结束函数(函数序列号)
如上面的例子,开始是4,结束为6,则表示计算函数序列号为4 5 6 三条指令生成数据的总大小。
_cal,f+:
用于对_num类型输出的数据作计算。共有4个参数。 如_cal,f+,32,0,3,5;
参数1:计算结果的大小,分别为6,16,32.分别表示计算结果是1,2,4字节。
参数2:计算结果的大小尾,0表示小尾,1表示大尾。
参数3:用于计算的第一个函数的参数ID。
参数4:用于计算的第二个函数的参数ID。
该函数所表示的值=第三个函数的数值+第四个函数的数值。
该类函数共用5种,分别为
_cal,f+ 结果=参数3指向函数数值+参数4指向函数数值
_cal,f- 结果=参数3指向函数数值-参数4指向函数数值
_cal,f* 结果=参数3指向函数数值*参数4指向函数数值
_cal,f/ 结果=参数3指向函数数值/参数4指向函数数值
_cal,f% 结果=参数3指向函数数值%参数4指向函数数值
_cal,n+:
用于计算一些数据的大小,共有4个参数,
如_cal,n+,32,0,3,200。
参数1:计算结果的大小,分别为6,16,32.分别表示计算结果是1,2,4字节。
参数2:计算结果的大小尾,0表示小尾,1表示大尾。
参数3:用于计算的第一个函数的参数ID。
参数4:用于计算的第二个参数,该数是数值。
该函数所表示的值=第三个函数的数值+第四个参数值200.
该类函数共用5种,分别为
_cal,n+ 结果=参数3指向函数数值+参数4
_cal,n- 结果=参数3指向函数数值-参数4
_cal,n* 结果=参数3指向函数数值*参数4
_cal,n/ 结果=参数3指向函数数值/参数4
_cal,n% 结果=参数3指向函数数值%参数4
_cal,-n:
用于计算一些数据的大小,共有4个参数,如_cal,0-n,32,0,200,3。
参数1:计算结果的大小,分别为6,16,32.分别表示计算结果是1,2,4字节。
参数2:计算结果的大小尾,0表示小尾,1表示大尾。
参数3:用于计算的第一个参数,该数是数值。
参数4:用于计算的第二个函数的参数ID。
该函数所表示的值=第三个参数200-第四个函数的值.
该类函数共用3种,分别为
_cal,-n 结果=参数3-参数4指向函数数值
_cal,/n 结果=参数3/参数4指向函数数值
_cal,&n 结果=参数3%参数4指向函数数值
_copy:
用于对一段指令生成的数据进行复制,该函数公用三个参数 如_copy,1,3,100;
参数1 要复制的开始ID值。
参数2,要复制的结束ID值。
参数3,要复制的份数。
如上面指令 表示要把1-3条指令的数据,复制100次。
该函数要求:如果参数3为0,则表示0-100的随机数。
注释信息:
用于表示注释代码的信息。用[<>]来表示。填写在每一条函数的末尾(不得填写在最后一条函数的末尾)。
_crc32:
用于计算一段数据的CRC32值,数据可以为num类型 也可以为长度不会变化的STR类型。
该函数一共有3个参数 如_crc32,1,2,5;
参数1:大小尾 0表示大尾,1表示小尾。
参数2:数据开始的ID
参数3:数据结束的ID
如上面指令表示第二条数据到第五条数据的CRC32值。占用空间4字节。
_crc16:
用于计算一段数据的CRC16值,用法和_CRC32一样,只是占用空间为2字节。
_hex:
用于定义一段HEX数值,最多64字节。一个参数。 如_hex,004010cc;
_choice:
选择语句,用来对一段指令序列随机选择。该函数一共有2个参数,如_choice,3,5;
表示在3-5条语句中随机选择一条语句作为输出。
可用于指向语句的类型有:
_num
_str
_hex
_DelToEnd:
删除语句,可以根据情况来选择是否删除该指令后续的全部代码。
该函数有1个参数,如_DelToEnd,1;
如果该参数为0,表示无条件删除后面的指令。
如果该参数非0,则表示参数语句的ID,如果指向ID参数语句值为0.则删除_DelToEnd语句后面的全部语句,否则不删除。
可用于指向语句的类型有:
_CountOfCopy
_num
cal,addr
cal,size
_cal,f+
_cal,n+
_cal,n-
注意:
1不要用于指向无值意义的指令,如_str类型。
2 被删除的语句参与计算,但是不参与输出。所以请小心使用该语句。
3 该语句可用于删除最后几条用于计算的零时语句。
_when:
有条件选择语句,该语句一共有5个参数。如_when,32,0,3,4,5;
参数1:计算结果的大小,分别为6,16,32.分别表示计算结果是1,2,4字节。
参数2:大小尾。0大尾1为小尾。
参数3:判断语句的ID。如果该ID值为0,则输出参数4.否则输出参数5.
参数4:语句ID
参数5:语句ID
例子表示判断第三条指令的值是否为0.如果为0输出参数4的值,否则输出参数5个值。输出结果为4字节,大尾格式。
代码编写:
例1 :MIDI格式
了解MIDI文件格式:
下面用来编写一个mid的文件格式的脚本。
mid文件格式简介:
一个MIDI文件基本上由2部分组成,头块和轨道块。
头块:
头块出现在文件的开头,头块看起来一般是这样的:
4D5468640000 0006 FFFF NNNN DDDD
4D5468640000 表示头块的表示值
FFFF是文件格式,有三种格式。
NNNN是MIDI文件中的轨道数。
DDDD是每个四分音符节奏数
轨道块:
4D54726B XXXXXXXX AAAAAAAAAAAAAAAAAAAAAAA
4D54726B 表示轨道块的标识值
AAAAAAAAAAAAAAAAAAAAAA表示轨道块
XXXXXXXX 表示轨道快的大小。
对文件格式建模,编写解析代码 下面是我编写的解析代码
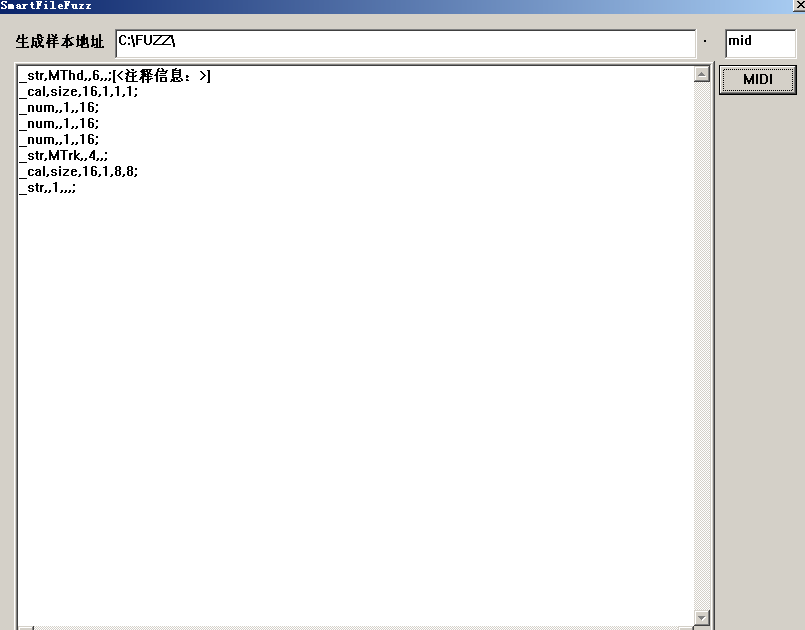
_str,MThd,,6,,;[<头信息为MThd,长度为6的字符串类型>]
_cal,size,16,1,1,1;[<第一行代码解析字符串的长度,大尾,16位>]
_num,,1,,16;[<一个16位的可变数据>]
_num,,1,,16;[<如上>]
_num,,1,,16;[<如上>]
_str,MTrk,,4,,;[<类似第一行>]
_cal,size,16,1,8,8;[<取缔把行代码生成数据的大小>]
_str,,1,,,;
根据我们的脚本进行漏洞挖掘
编写脚本后点击确定,如果脚本没有错误,系统则会根据脚本来生成畸形样本。

生成完毕后,我们进行通用Fuzz模块来进行漏洞挖掘。
因为漏洞挖掘模块写在了通用Fuzz模块里面。智能Fuzz模块只是一个生成畸形样本的模块。

如果你在此之前从来没有用过windows播放器,请先配置一下,才可以正常挖掘漏洞.Windows播放器是不支持多线程运行的,因此,您需要把开启速率这个值设置比允许时间稍微大一些。然后,程序就开始Fuzz了。这需要大量的时间。
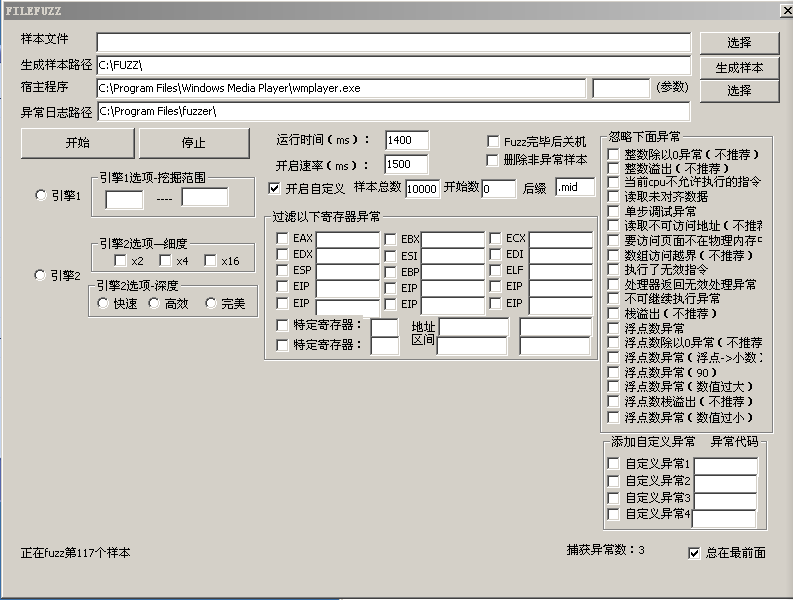
时间问题,我们提前结束了Fuzz。此时程序已经将会出现异常的样本和日志保存起来。
如图: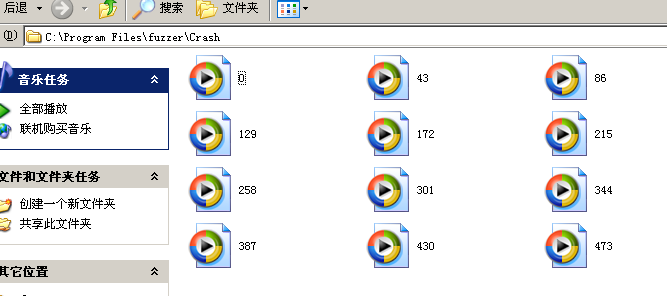
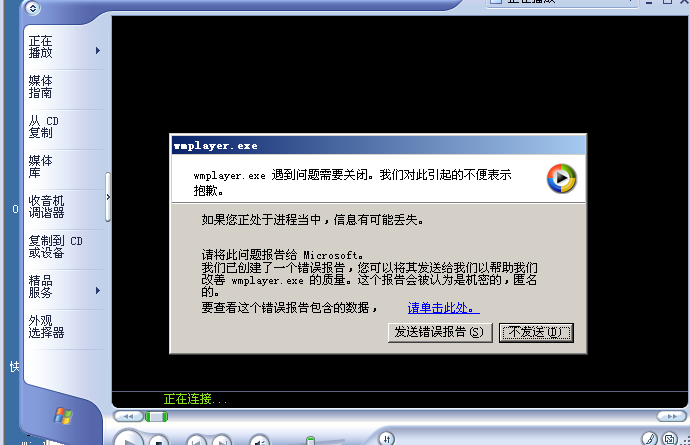
我们随便点击一个样本做测试,发现程序崩溃可以成功复现。
例2:BMP格式
和midi格式相比,BMP格式较为复杂,具体文件格式请自行学习,下面是一段BMP格式的解析脚本:
_str,BM,,,,;
_cal,size,32,,1,20;[
_num,,1,,32;
_cal,addr,32,,18;
_cal,size,32,,1,4;
_num,8,,,32;[
_num,8,,,32;[
_num,,1,,16;
_num,,1,,16;
_num,,1,,32;
_cal,size,32,,18,20;
_num,,1,,32;
_num,,1,,32;
_num,,1,,32;
_num,,1,,32;
_num,,1,,32;
_copy,16,16,31;
_num,,1,,16;[<18>]
_str,,1,2,,;[<19>]
_copy,18,19,63;
该段脚本一共有20行。
第1-4行为一个结构,我们定义为结构A
第18-20行表示一个结构。我们定义为结构B
第1行为一段固定的字符串,BM。
第2行表示文件的总大小。
第4行则表示结构B的偏移
第5行可以表示该结构的偏移,也就是结构A的大小
第11行表示结构B的大小.

常见错误:
1 第xx行代码错误(最后一行)
检查最后是否多了空格,回车符等符号。
检查代码最后是否有注释信息。
1 第xx行代码错误(非最后一行)
检查参数个数是否匹配。
检查每一个参数是否在有效值内。
检查参数的长度是否过长。
漏洞分析模块
Shellcode工具
ShellcodeToBin模块
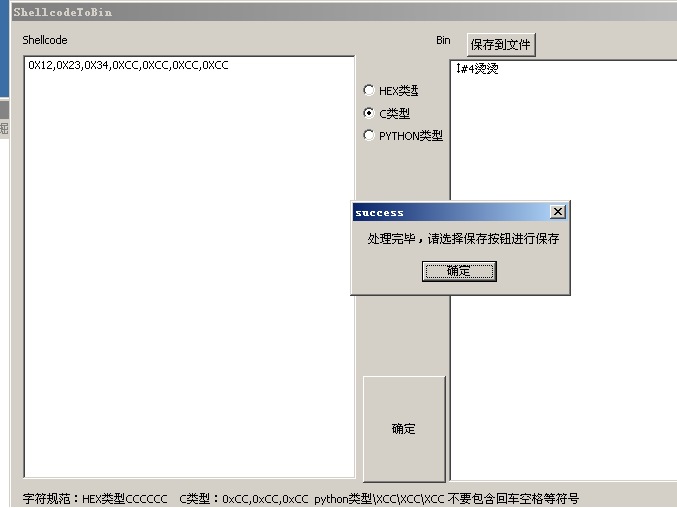
到1.0为止Shellcode支持hex,c,python3种类型。
该模块可用于对shellcode的编辑处理。
ShellcodeToExe模块

该模块可用于对shellcode的调试。
BinToShellcode模块

该模块可用于对shellcode的编辑。格式处理。