学习笔记----Python高级语法
GIL(全局解释器锁)
GIL面试题如下
描述Python GIL的概念,以及它对Python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因。
1.Python语言和GIL没有关系。仅仅是由于历史原因在Cpython解释器,难以移除GIL。
2. GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程在执行代码。
3. 这就导致Python多线程实现并发或者并行时,发挥不了CPU多核的运行效率,只有一个线程在执行。(其他线程因堵塞,排队)
4. Python使用多进程是可以利用多核的CPU资源的。
5. 多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁。(类比gevent概念)即线程释放GIL锁的情况:在IO操作等可能会引起堵塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL。
深拷贝、浅拷贝
- 浅拷贝是对于一个对象的顶层拷贝
通俗理解是:拷贝了引用,并没有拷贝内容。


深拷贝
- 深拷贝是对于一个对象所有层次的拷贝(递归)
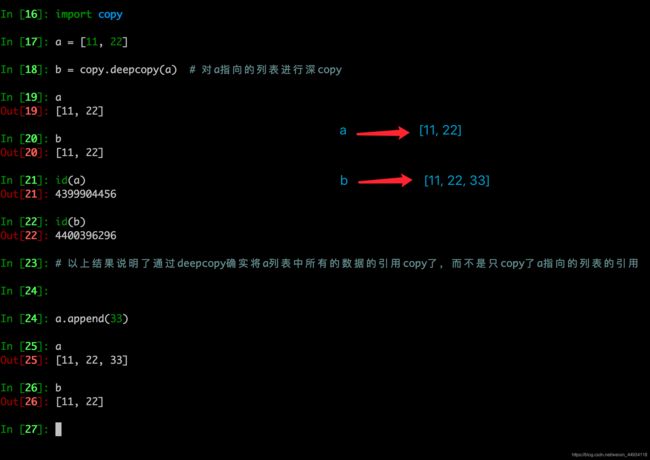
进一步理解深拷贝


拷贝的其他方式
- 切片
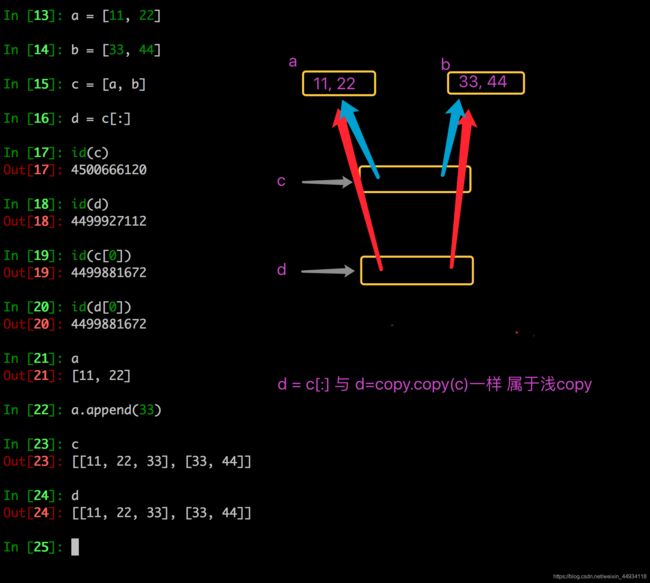
- 字典的copy方法可以拷贝一个字典
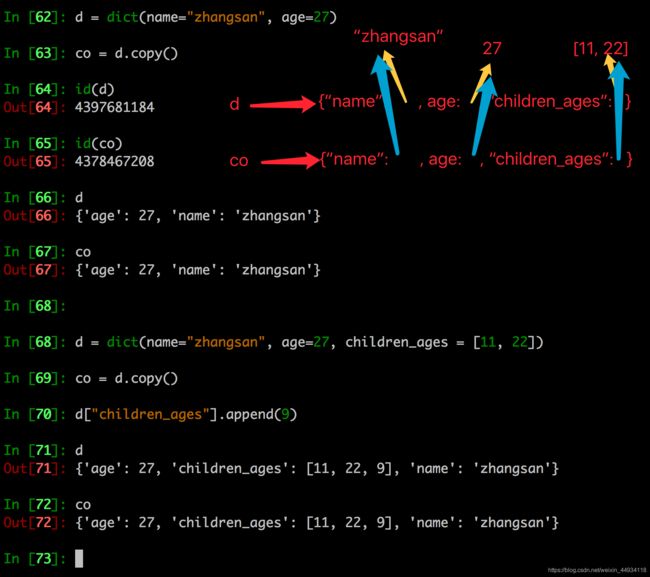
注意点
1.copy.copy对于可变类型,会进行浅拷贝
1.copy.copy对于不可变类型,不会拷贝,仅仅是指向
In [88]: a = [11,22,33]
In [89]: b = copy.copy(a)
In [90]: id(a)
Out[90]: 59275144
In [91]: id(b)
Out[91]: 59525600
In [92]: a.append(44)
In [93]: a
Out[93]: [11, 22, 33, 44]
In [94]: b
Out[94]: [11, 22, 33]
In [95]: a = (11,22,33)
In [96]: b = copy.copy(a)
In [97]: id(a)
Out[97]: 58890680
In [98]: id(b)
Out[98]: 58890680

copy.copy和copy.deepcopy的区别
copy.copy

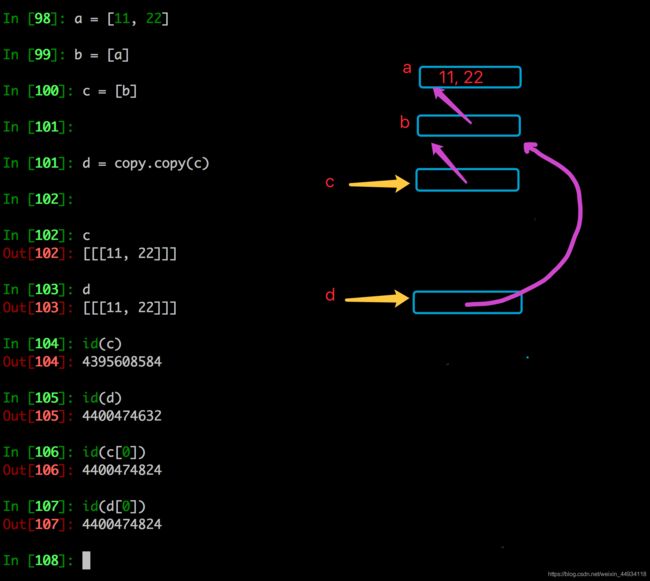
copy.deepcopy



私有化
- xx: 公有变量
- _x: 单前置下划线,私有化属性或方法,from somemodule import *禁止导入,类对象和子类可以访问
- __xx:双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到)
- xx:双前后下划线,用户名字空间的魔法对象或属性。例如:init , __ 不要自己发明这样的名字
- xx_:单后置下划线,用于避免与Python关键词的冲突
import导入模块
import 搜索路径

路径搜索
- 从上面列出的目录里依次查找要导入的模块文件
- ‘’ 表示当前路径
- 列表中的路径的先后顺序代表了python解释器在搜索模块时的先后顺序
程序执行时添加新的模块路径
sys.path.append('/home/itcast/xxx')
sys.path.insert(0, '/home/itcast/xxx') # 可以确保先搜索这个路径
In [37]: sys.path.insert(0,"/home/python/xxxx")
In [38]: sys.path
Out[38]:
['/home/python/xxxx',
'',
'/usr/bin',
'/usr/lib/python35.zip',
'/usr/lib/python3.5',
'/usr/lib/python3.5/plat-x86_64-linux-gnu',
'/usr/lib/python3.5/lib-dynload',
'/usr/local/lib/python3.5/dist-packages',
'/usr/lib/python3/dist-packages',
'/usr/lib/python3/dist-packages/IPython/extensions',
'/home/python/.ipython']
重新导入模块
模块被导入后,import module不能重新导入模块,重新导入需用reload
![]()

![]()

多模块开发时的注意点
import common 与 from common import HANDLE_FLAG 的坑
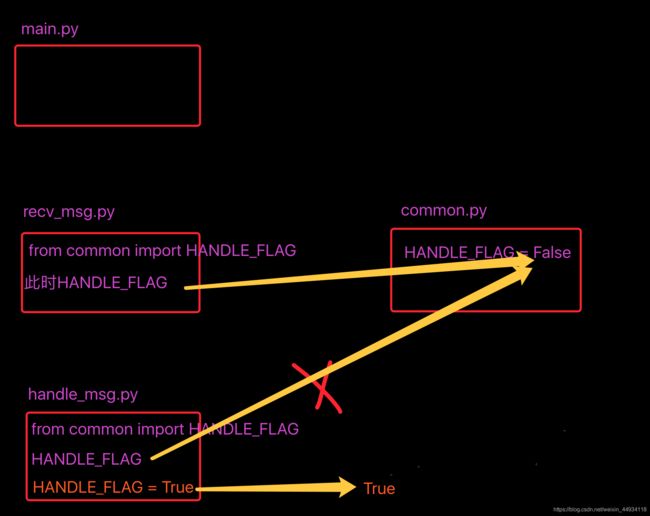

再议 封装、继承、多态
封装的好处
- 在使用面向过程编程时,当需要对数据处理时,需要考虑用哪个模板中哪个函数来进行操作,但是当用面向对象编程时,因为已经将数据存储到了这个独立的空间中,这个独立的空间(即对象)中通过一个特殊的变量(class)能够获取到类(模板),而且这个类中的方法是有一定数量的,与此类无关的将不会出现在本类中,因此需要对数据处理时,可以很快速的定位到需要的方法是谁
这样更方便 - 全局变量是只能有1份的,多很多个函数需要多个备份时,往往需要利用其它的变量来进行储存;而通过封装 会将用来存储数据的这个变量
变为了对象中的一个“全局”变量,只要对象不一样那么这个变量就可以再有1份,所以这样更方便 - 代码划分更清晰
面向过程
全局变量1
全局变量2
全局变量3
...
def 函数1():
pass
def 函数2():
pass
def 函数3():
pass
def 函数4():
pass
def 函数5():
pass
工程大的话,容易混淆全局变量的使用,面向对象则避免这个问题
面向对象
class 类(object):
属性1
属性2
def 方法1(self):
pass
def 方法2(self):
pass
class 类2(object):
属性3
def 方法3(self):
pass
def 方法4(self):
pass
def 方法5(self):
pass
继承
- 能够提升代码的重用率,即开发一个类,可以在多个子功能中直接使用
- 继承能够有效的进行代码的管理,当某个类有问题只要修改这个类就行,而其继承这个类的子类往往不需要就修改
多态
class MiniOS(object):
"""MiniOS 操作系统类 """
def __init__(self, name):
self.name = name
self.apps = [] # 安装的应用程序名称列表
def __str__(self):
return "%s 安装的软件列表为 %s" % (self.name, str(self.apps))
def install_app(self, app):
# 判断是否已经安装了软件
if app.name in self.apps:
print("已经安装了 %s,无需再次安装" % app.name)
else:
app.install()
self.apps.append(app.name)
class App(object):
def __init__(self, name, version, desc):
self.name = name
self.version = version
self.desc = desc
def __str__(self):
return "%s 的当前版本是 %s - %s" % (self.name, self.version, self.desc)
def install(self):
print("将 %s [%s] 的执行程序复制到程序目录..." % (self.name, self.version))
class PyCharm(App):
pass
class Chrome(App):
def install(self):
print("正在解压缩安装程序...")
super().install()
linux = MiniOS("Linux")
print(linux)
pycharm = PyCharm("PyCharm", "1.0", "python 开发的 IDE 环境")
chrome = Chrome("Chrome", "2.0", "谷歌浏览器")
linux.install_app(pycharm)
linux.install_app(chrome)
linux.install_app(chrome)
print(linux)
运行结果
Linux 安装的软件列表为 []
将 PyCharm [1.0] 的执行程序复制到程序目录...
正在解压缩安装程序...
将 Chrome [2.0] 的执行程序复制到程序目录...
已经安装了 Chrome,无需再次安装
Linux 安装的软件列表为 ['PyCharm', 'Chrome']
简单理解:
如代码中 Chrome(App)方法中,继承App的函数后,对install()方法进行重定义;当安装非Chrome软件时,遵循父类的install()方法,当安装Chrome时,则遵循子类中install()方法;这个过程变称为多态。
多继承以及MRO顺序
1.单独调用父类的方法
# coding=utf-8
print("******多继承使用类名.__init__ 发生的状态******")
class Parent(object):
def __init__(self, name):
print('parent的init开始被调用')
self.name = name
print('parent的init结束被调用')
class Son1(Parent):
def __init__(self, name, age):
print('Son1的init开始被调用')
self.age = age
Parent.__init__(self, name)
print('Son1的init结束被调用')
class Son2(Parent):
def __init__(self, name, gender):
print('Son2的init开始被调用')
self.gender = gender
Parent.__init__(self, name)
print('Son2的init结束被调用')
class Grandson(Son1, Son2):
def __init__(self, name, age, gender):
print('Grandson的init开始被调用')
Son1.__init__(self, name, age) # 单独调用父类的初始化方法
Son2.__init__(self, name, gender)
print('Grandson的init结束被调用')
gs = Grandson('grandson', 12, '男')
print('姓名:', gs.name)
print('年龄:', gs.age)
print('性别:', gs.gender)
print("******多继承使用类名.__init__ 发生的状态******\n\n")
运行结果:
******多继承使用类名.__init__ 发生的状态******
Grandson的init开始被调用
Son1的init开始被调用
parent的init开始被调用
parent的init结束被调用
Son1的init结束被调用
Son2的init开始被调用
parent的init开始被调用
parent的init结束被调用
Son2的init结束被调用
Grandson的init结束被调用
姓名: grandson
年龄: 12
性别: 男
******多继承使用类名.__init__ 发生的状态******
2.多继承中super调用有所父类的被重写的方法
print("******多继承使用super().__init__ 发生的状态******")
class Parent(object):
def __init__(self, name, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数
print('parent的init开始被调用')
self.name = name
print('parent的init结束被调用')
class Son1(Parent):
def __init__(self, name, age, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数
print('Son1的init开始被调用')
self.age = age
super().__init__(name, *args, **kwargs) # 为避免多继承报错,使用不定长参数,接受参数
print('Son1的init结束被调用')
class Son2(Parent):
def __init__(self, name, gender, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数
print('Son2的init开始被调用')
self.gender = gender
super().__init__(name, *args, **kwargs) # 为避免多继承报错,使用不定长参数,接受参数
print('Son2的init结束被调用')
class Grandson(Son1, Son2):
def __init__(self, name, age, gender):
print('Grandson的init开始被调用')
# 多继承时,相对于使用类名.__init__方法,要把每个父类全部写一遍
# 而super只用一句话,执行了全部父类的方法,这也是为何多继承需要全部传参的一个原因
# super(Grandson, self).__init__(name, age, gender)
super().__init__(name, age, gender)
print('Grandson的init结束被调用')
print(Grandson.__mro__)
gs = Grandson('grandson', 12, '男')
print('姓名:', gs.name)
print('年龄:', gs.age)
print('性别:', gs.gender)
print("******多继承使用super().__init__ 发生的状态******\n\n")
运行结果:
******多继承使用super().__init__ 发生的状态******
(, , , , )
Grandson的init开始被调用
Son1的init开始被调用
Son2的init开始被调用
parent的init开始被调用
parent的init结束被调用
Son2的init结束被调用
Son1的init结束被调用
Grandson的init结束被调用
姓名: grandson
年龄: 12
性别: 男
******多继承使用super().__init__ 发生的状态******
注意:
- 以上2个代码执行的结果不同
- 如果2个子类中都继承了父类,当在子类中通过父类名调用时,parent被执行了2次
- 如果2个子类中都继承了父类,当在子类中通过super调用时,parent被执行了1次。原因在于:
1.在多继承时,使用super方法,对父类的传参数,由于Python3中super的C3算法(处理多继承调用的先后顺序,保证每一个类只调一次)导致的原因,必须把参数全部传递,否则会报错;
- C3算法的体现:当在打印最底层类的__mro__方法(eg:print(Grandson.mro)),可以得出C3算法的结论,以一个元祖的形式表示。这个元祖里面是很多类的名字,类的先后顺序决定了调用super()的先后顺序。
- 当super()括号无参数时,则当前的类是哪个就拿它对应元祖中相同项,相同项的下一个则为继承的类。而当super()括号有参数时,则拿括号里面的参数查询元祖中对应项,对应项的下一个为继承项。
3 单继承中super
print("******单继承使用super().__init__ 发生的状态******")
class Parent(object):
def __init__(self, name):
print('parent的init开始被调用')
self.name = name
print('parent的init结束被调用')
class Son1(Parent):
def __init__(self, name, age):
print('Son1的init开始被调用')
self.age = age
super().__init__(name) # 单继承不能提供全部参数
print('Son1的init结束被调用')
class Grandson(Son1):
def __init__(self, name, age, gender):
print('Grandson的init开始被调用')
super().__init__(name, age) # 单继承不能提供全部参数
print('Grandson的init结束被调用')
gs = Grandson('grandson', 12, '男')
print('姓名:', gs.name)
print('年龄:', gs.age)
#print('性别:', gs.gender)
print("******单继承使用super().__init__ 发生的状态******\n\n")
PS.单继承中super()与类名的方法无差别
小试牛刀(面试题)
以下的代码的输出将是什么?说出你的答案并解释。
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x)
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
Parent.x = 3
print(Parent.x, Child1.x, Child2.x)
输出结果:
1 1 1
1 2 1
3 2 3
再论静态方法和类方法
1.类属性、实力属性
他们在定义和使用中有所区别,而最本质的区别是内存中保存中保存的位置不同,
- 实力属性属于对象
- 类属性属于类
class Province(object):
# 类属性
country = '中国'
def __init__(self, name):
# 实例属性
self.name = name
# 创建一个实例对象
obj = Province('山东省')
# 直接访问实例属性
print(obj.name)
# 直接访问类属性
Province.country
由上述代码可以看出【实例属性需要通过对象来访问】【类属性通过类访问】,在使用上可以看出实例属性和类属性的归属是不同的。
其在内容的存储方式类似如下图:

由上图看出:
- 类属性在内存中只保存一份
- 实例属性在每个对象中都要保存一份
应用场景:
- 通过类创建实例对象时,如果每个对象需要具有相同名字的属性,那么就使用类属性,用一份既可
2.实力方法、静态方法和类方法
方法包括:实例方法、静态方法和类方法,三种方法在内存中都归属于类,区别在于调用方式不同。
- 实例方法:由对象调用;至少一个self参数;执行实例方法时,自动将调用该方法的对象赋值给self;
- 类方法:由类调用;至少一个cls参数;执行类方法时,自动将调用该方法的类赋值给cls;
- 静态方法:由类调用;无默认参数;
class Foo(object):
def __init__(self, name):
self.name = name
def ord_func(self):
""" 定义实例方法,至少有一个self参数 """
# print(self.name)
print('实例方法')
@classmethod
def class_func(cls):
""" 定义类方法,至少有一个cls参数 """
print('类方法')
@staticmethod
def static_func():
""" 定义静态方法 ,无默认参数"""
print('静态方法')
f = Foo("中国")
# 调用实例方法
f.ord_func()
# 调用类方法
Foo.class_func()
# 调用静态方法
Foo.static_func()
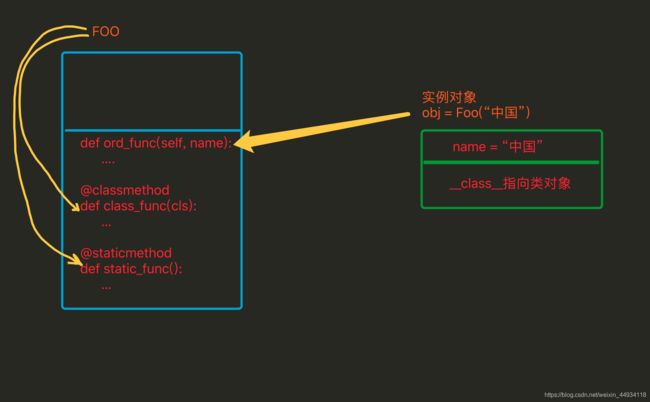
对比
- 相同点:对于所有的方法而言,均属于类,所以在内存中也只保存一份
- 不同点:方法调用者不同,调用方法时自动传入的参数不同。
property属性
1.什么是property属性
一种用起来像是使用的实例属性一样的特殊属性,可以对应于某个方法
# ############### 定义 ###############
class Foo:
def func(self):
pass
# 定义property属性
@property
def prop(self):
pass
# ############### 调用 ###############
foo_obj = Foo()
foo_obj.func() # 调用实例方法
foo_obj.prop # 调用property属性

property属性的定义和调用要注意以下几点:
- 定义时,在实例方法的基础上添加@property装饰器;并且仅有一个self参数
- 调用时,无需括号
方法:foo_obj.func()
property属性:foo_obj.prop
2.简单的实例
对于京东商城中显示电脑主机的列表页面,每次请求不可能把数据库中的所有内容都显示到页面上,而是通过分页的功能局部显示,所以在向数据库中请求数据时就要显示的指定获取从第m条到第n条的所有数据 这个分页的功能包括:
- 根据用户请求的当前页和总数据条数计算出 m 和 n
- 根据m 和 n 去数据库中请求数据
# ############### 定义 ###############
class Pager:
def __init__(self, current_page):
# 用户当前请求的页码(第一页、第二页...)
self.current_page = current_page
# 每页默认显示10条数据
self.per_items = 10
@property
def start(self):
val = (self.current_page - 1) * self.per_items
return val
@property
def end(self):
val = self.current_page * self.per_items
return val
# ############### 调用 ###############
p = Pager(1)
p.start # 就是起始值,即:m
p.end # 就是结束值,即:n
从上述可见
- python的property属性的功能是:property属性内部进行一系列的逻辑计算,最终将计算结果返回。
3.property属性的两种方式
- 装饰器 即:在方法上应用装饰器
- 类属性 即:在类中定义值为property对象的类属性
3.1装饰器方式
在类的实例方法上应用@property装饰器
Python中的类有经典类和新式类,新式类的属性比经典类的属性丰富。(如果类继object,那么该类是新式类)
经典类,具有一种@property装饰器
# ############### 定义 ###############
class Goods:
@property
def price(self):
return "laowang"
# ############### 调用 ###############
obj = Goods()
result = obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
print(result)
新式类,具有三种@property装饰器
#coding=utf-8
# ############### 定义 ###############
class Goods:
"""python3中默认继承object类
以python2、3执行此程序的结果不同,因为只有在python3中才有@xxx.setter @xxx.deleter
"""
@property
def price(self):
print('@property')
@price.setter
def price(self, value):
print('@price.setter')
@price.deleter
def price(self):
print('@price.deleter')
# ############### 调用 ###############
obj = Goods()
obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数
del obj.price # 自动执行 @price.deleter 修饰的 price 方法
注意
- 经典类中的属性只有一种访问方式,其对应被@property修饰的方法
- 新式类中的属性有三种访问方式,并分别对应了三个被@property、@方法名.setter、@方法名.deleter修饰的方法
由于新式类中具有三种访问方式,我们可以根据他们几个属性的访问特点,分别将三个方法定义为同一个属性:获取、修改、删除
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
@property
def price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
@price.setter
def price(self, value):
self.original_price = value
@price.deleter
def price(self):
del self.original_price
obj = Goods()
obj.price # 获取商品价格
obj.price = 200 # 修改商品原价
del obj.price # 删除商品原价
3.2类属性方式,创建值为property对象的类属性
- 当使用类属性的方式创建property属性时,经典类和新式类无区别
class Foo:
def get_bar(self):
return 'laowang'
BAR = property(get_bar)
obj = Foo()
reuslt = obj.BAR # 自动调用get_bar方法,并获取方法的返回值
print(reuslt)
property方法中有四个参数
- 第一个参数是方法名,调用 对象.属性 时自动触发执行方法
- 第二个参数是方法名,调用 对象.属性 = XXX 时自动触发执行方法
- 第三个参数是方法名,调用 del 对象.属性 时自动触发执行方法
- 第四个参数是字符串,调用 对象.属性.doc ,此参数是该属性的描述信息
#coding=utf-8
class Foo(object):
def get_bar(self):
print("getter...")
return 'laowang'
def set_bar(self, value):
"""必须两个参数"""
print("setter...")
return 'set value' + value
def del_bar(self):
print("deleter...")
return 'laowang'
BAR = property(get_bar, set_bar, del_bar, "description...")
obj = Foo()
obj.BAR # 自动调用第一个参数中定义的方法:get_bar
obj.BAR = "alex" # 自动调用第二个参数中定义的方法:set_bar方法,并将“alex”当作参数传入
desc = Foo.BAR.__doc__ # 自动获取第四个参数中设置的值:description...
print(desc)
del obj.BAR # 自动调用第三个参数中定义的方法:del_bar方法
由于类属性方式创建property属性具有3种访问方式,我们可以根据它们几个属性的访问特点,分别将三个方法定义为同一个属性:获取、修改、删除
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
def get_price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
def set_price(self, value):
self.original_price = value
def del_price(self):
del self.original_price
PRICE = property(get_price, set_price, del_price, '价格属性描述...')
obj = Goods()
obj.PRICE # 获取商品价格
obj.PRICE = 200 # 修改商品原价
del obj.PRICE # 删除商品原价
4.Django框架中应用了property属性(了解)
WEB框架Django的视图中request.POST就是使用的类属性的方式创建的属性
class WSGIRequest(http.HttpRequest):
def __init__(self, environ):
script_name = get_script_name(environ)
path_info = get_path_info(environ)
if not path_info:
# Sometimes PATH_INFO exists, but is empty (e.g. accessing
# the SCRIPT_NAME URL without a trailing slash). We really need to
# operate as if they'd requested '/'. Not amazingly nice to force
# the path like this, but should be harmless.
path_info = '/'
self.environ = environ
self.path_info = path_info
self.path = '%s/%s' % (script_name.rstrip('/'), path_info.lstrip('/'))
self.META = environ
self.META['PATH_INFO'] = path_info
self.META['SCRIPT_NAME'] = script_name
self.method = environ['REQUEST_METHOD'].upper()
_, content_params = cgi.parse_header(environ.get('CONTENT_TYPE', ''))
if 'charset' in content_params:
try:
codecs.lookup(content_params['charset'])
except LookupError:
pass
else:
self.encoding = content_params['charset']
self._post_parse_error = False
try:
content_length = int(environ.get('CONTENT_LENGTH'))
except (ValueError, TypeError):
content_length = 0
self._stream = LimitedStream(self.environ['wsgi.input'], content_length)
self._read_started = False
self.resolver_match = None
def _get_scheme(self):
return self.environ.get('wsgi.url_scheme')
def _get_request(self):
warnings.warn('`request.REQUEST` is deprecated, use `request.GET` or '
'`request.POST` instead.', RemovedInDjango19Warning, 2)
if not hasattr(self, '_request'):
self._request = datastructures.MergeDict(self.POST, self.GET)
return self._request
@cached_property
def GET(self):
# The WSGI spec says 'QUERY_STRING' may be absent.
raw_query_string = get_bytes_from_wsgi(self.environ, 'QUERY_STRING', '')
return http.QueryDict(raw_query_string, encoding=self._encoding)
# ############### 看这里看这里 ###############
def _get_post(self):
if not hasattr(self, '_post'):
self._load_post_and_files()
return self._post
# ############### 看这里看这里 ###############
def _set_post(self, post):
self._post = post
@cached_property
def COOKIES(self):
raw_cookie = get_str_from_wsgi(self.environ, 'HTTP_COOKIE', '')
return http.parse_cookie(raw_cookie)
def _get_files(self):
if not hasattr(self, '_files'):
self._load_post_and_files()
return self._files
# ############### 看这里看这里 ###############
POST = property(_get_post, _set_post)
FILES = property(_get_files)
REQUEST = property(_get_request)
综上所述
- 定义property属性共有两种方式,分别是【装饰器】和【类属性】,而【装饰器】方式针对经典类和新式类又有所不同。
- 通过使用property属性,能够简化调用者在获取数据的流程
property属性-应用
1.私有属性添加getter和setter方法
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
2. 使用property升级getter和setter方法
class Money(object):
def __init__(self):
self.__money = 0
def getMoney(self):
return self.__money
def setMoney(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
# 定义一个属性,当对这个money设置值时调用setMoney,当获取值时调用getMoney
money = property(getMoney, setMoney)
a = Money()
a.money = 100 # 调用setMoney方法
print(a.money) # 调用getMoney方法
#100
3.使用property取代getter和setter方法
- 重新实现一个属性的设置和读取方法,可做边界判定
class Money(object):
def __init__(self):
self.__money = 0
# 使用装饰器对money进行装饰,那么会自动添加一个叫money的属性,当调用获取money的值时,调用装饰的方法
@property
def money(self):
return self.__money
# 使用装饰器对money进行装饰,当对money设置值时,调用装饰的方法
@money.setter
def money(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
a = Money()
a.money = 100
print(a.money)
面对对象设计
- 继承 - 是基于Python中的属性查找(如X.name)
- 多态 - 在X.method方法中,method的意义取决于X的类型
- 封装 - 方法和运算符实现行为,数据隐藏默认是一种惯例
with与“上下文管理器”
对于系统资源如文件、数据库连接、socket而言,应用程序打开这些资源并执行完业务逻辑之后,必须做一件事就是关闭(断开)该资源
比如Python程序打开一个文件,往文件中写内容,写完之后,就要关闭该文件,否则会出现什么情况呢?极端情况下会出现“Too many open files”的错误,因为系统允许你打开的最大文件数量是有限的。
同样,对于数据库,如果连接数过多而没有及时关闭的话,就可能会出现“Can not connect to MySQL server Too many connections”,因为数据库连接是一种非常昂贵的资源,不可能无限制的被创建。
来看看如何正确关闭一个文件。
普通版
def m1():
f = open("output.txt", "w")
f.write("python之禅")
f.close()
这样写有一个潜在的问题,如果在调用 write 的过程中,出现了异常进而导致后续代码无法继续执行,close 方法无法被正常调用,因此资源就会一直被该程序占用者释放。那么该如何改进代码呢?
进阶版
def m2():
f = open("output.txt", "w")
try:
f.write("python之禅")
except IOError:
print("oops error")
finally:
f.close()
改良版本的程序是对可能发生异常的代码处进行 try 捕获,使用 try/finally 语句,该语句表示如果在 try 代码块中程序出现了异常,后续代码就不再执行,而直接跳转到 except 代码块。而无论如何,finally 块的代码最终都会被执行。因此,只要把 close 放在 finally 代码中,文件就一定会关闭。
高级版
def m3():
with open("output.txt", "r") as f:
f.write("Python之禅")
一种更加简洁,优雅的方式就是用with关键字。open方法的返回值赋值给变量f,当离开with代码块的时候,系统会自动调用f.close()方法,with的作用和使用try/finally语句是一样的。那么它的实现原理是什么?在讲with的原理前要涉及到另外一个概念,就是上下文管理器(Context Manager)
上下文管理器
任何实现了__enter__()和__exit__()方法的对象都可称之为上下文管理器,上下文管理器对象可以使用with关键字。显然,文件(file)对象也实现了上下文管理器。
那么文件对象是如何实现这两个方法的呢?我们可以模拟实现一个自己的文件夹,让该类实现__enter__()和__exit__()方法。
class File():
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
print("entering")
self.f = open(self.filename, self.mode)
return self.f
def __exit__(self, *args):
print("will exit")
self.f.close()
enter()方法返回资源对象,这里就是你将要打开的那个文件对象,exit()方法处理一些清楚工作。
因为File类实现了上下文管理器,现在就可以使用with语句了。
with File('out.txt', 'w') as f:
print("writing")
f.write('hello, python')
这样,你就无需显示地调用 close 方法了,由系统自动去调用,哪怕中间遇到异常 close 方法也会被调用。
实现上下文管理器的另外方式
Python 还提供了一个 contextmanager 的装饰器,更进一步简化了上下文管理器的实现方式。通过 yield 将函数分割成两部分,yield 之前的语句在 enter 方法中执行,yield 之后的语句在 exit 方法中执行。紧跟在 yield 后面的值是函数的返回值。
from contextlib import contextmanager
@contextmanager
def my_open(path, mode):
f = open(path, mode)
yield f
f.close()
调用
with my_open('out.txt', 'w') as f:
f.write("hello , the simplest context manager")
总结
Python提供了with语法用于简化资源操作的后续清除操作,是try/finally的替代方法,实现原理建立在上下文管理器之上。此外,Python还提供了一个contextmanager装饰器,更进一步简化上下文管理器的实现方式