mysql的mvcc和加锁分析
1:数据库的隔离级别
数据库的隔离级分类分为四类READ_UNCOMMITTED,READ_COMMITTED,REPEATABLE_READ,SERIALIZABLE。
1.1:READ_UNCOMMITTED
读未提交时,读事务直接读取主记录,无论更新事务是否完成
1.2:READ_COMMITTED
读提交时,读事务每次都读取undo log中最近的版本,因此两次对同一字段的读可能读到不同的数据(幻读),但能保证每次
都读到最新的数据。
1.3:REPEATABLE_READ
每次都读取指定的版本,这样保证不会产生幻读,但可能读不到最新的数据
1.4:SERIALIZABLE
锁表,读写相互阻塞,使用较少
2:MVCC多版本机制
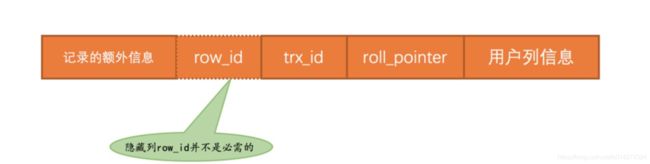
为了实现上面的数据库的隔离级别,mvcc应运而生,mysql怎么实现mvcc,这依赖于mysql的隐藏列,trx_id事务id,
roll_pointer回滚指针,row_id主键,这个主键是表不存在主键和唯一索引的时候自动添加的。
2.1:insert

当插入的是一条新数据时,roll_pointer指向insert的undo日志,事务提交之后就没有意义了。
2.2:update

每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表
2.3:delete
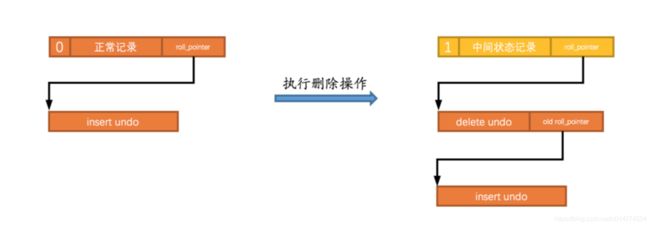
delete语句和update基本上没有区别,只是把记录的delete_mask置成删除,在后面purge的时候,加入到删除的数据页当中去。
2.4:readview
有了多版本之后,不知道怎么用也不行啊,mvcc真正使用的地方是readview,readview包含四个内容。
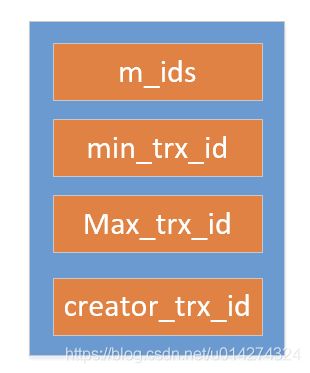
m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。
min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。
max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。
creator_trx_id:表示生成该ReadView的事务的事务id。
- 如果被访问版本的trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值大于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创 建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。这个的可以访问,在不同的隔离级别下的表现并不相同,READ_COMMITTED和REPEATABLE_READ的表现并不相同,rc下,事务提交了就可见,rr下事务提交了,并不可见,保证每次查询的记录相同。但是存在例外,比如a提交了事务,b去查询a事务是查不到提交的内容,但是如果去更新a提交的事务,是能够更新的,对于这个的讨论,有很多意见,这里我就不发表意见了,下面看一下具体的例子。
2.5:READ COMMITTED —— 每次读取数据前都生成一个ReadView
# Transaction 100
BEGIN;
UPDATE hero SET name = '关羽' WHERE number = 1;
UPDATE hero SET name = '张飞' WHERE number = 1;
# Transaction 200 BEGIN;
# 更新了一些别的表的记录 ...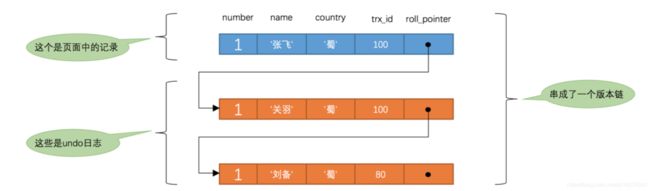
假设现在有一个使用READ COMMITTED隔离级别的事务开始执行:
# 使用READ COMMITTED隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值为'刘备'这个SELECT1的执行过程如下:
在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。
然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列name的内容是'张飞',该版本的trx_id值为100,在m_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。
下一个版本的列name的内容是'关羽',该版本的trx_id值也为100,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。
下一个版本的列name的内容是'刘备',该版本的trx_id值为80,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的,最后返回给用户的版本就是这条 列name为'刘备'的记录。
之后,我们把事务id为100的事务提交一下,就像这样:
# Transaction 100
BEGIN;
UPDATE hero SET name = '关羽' WHERE number = 1;
UPDATE hero SET name = '张飞' WHERE number = 1;
COMMIT;然后再到事务id为200的事务中更新一下表hero中number为1的记录:
# Transaction 200
BEGIN;
# 更新了一些别的表的记录 ...
UPDATE hero SET name = '赵云' WHERE number = 1;
UPDATE hero SET name = '诸葛亮' WHERE number = 1;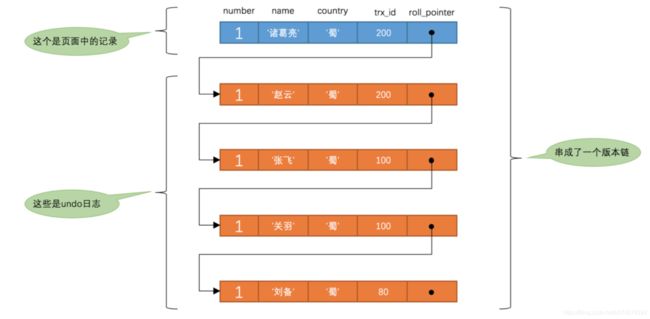
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个number为1的记录,如下:
# 使用READ COMMITTED隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200均未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值为'刘备'
# SELECT2:Transaction 100提交,Transaction 200未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值为'张飞'这个SELECT2的执行过程如下:
在执行SELECT语句时会又会单独生成一个ReadView,该ReadView的m_ids列表的内容就是[200](事务id为100的那个事务已经提交了,所以再次生成快照时就没有它 了),min_trx_id为200,max_trx_id为201,creator_trx_id为0。
然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列name的内容是'诸葛亮',该版本的trx_id值为200,在m_ids列表内,所以不符合可见性要求,根 据roll_pointer跳到下一个版本。
下一个版本的列name的内容是'赵云',该版本的trx_id值为200,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。 下一个版本的列name的内容是'张飞',该版本的trx_id值为100,小于ReadView中的min_trx_id值200,所以这个版本是符合要求的,最后返回给用户的版本就是这条列name为'张飞'的记录。
2.6:REPEATABLEREAD——在第一次读取数据时生成一个ReadView
比方说现在系统里有两个事务id分别为100、200的事务在执行:
# Transaction 100 BEGIN;
UPDATE hero SET name = '关羽' WHERE number = 1;
UPDATE hero SET name = '张飞' WHERE number = 1;
# Transaction 200 BEGIN;
# 更新了一些别的表的记录 ...
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行:
# 使用REPEATABLE READ隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值为'刘备'这个SELECT1的执行过程如下:
在执行SELECT语句时会先生成一个ReadView,ReadView的m_ids列表的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。 然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列name的内容是'张飞',该版本的trx_id值为100,在m_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。
下一个版本的列name的内容是'关羽',该版本的trx_id值也为100,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。
下一个版本的列name的内容是'刘备',该版本的trx_id值为80,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的,最后返回给用户的版本就是这条 列name为'刘备'的记录。
之后,我们把事务id为100的事务提交一下,就像这样:
# Transaction 100
BEGIN;
UPDATE hero SET name = '关羽' WHERE number = 1;
UPDATE hero SET name = '张飞' WHERE number = 1;
COMMIT;
然后再到事务id为200的事务中更新一下表hero中number为1的记录:
# Transaction 200
BEGIN;
# 更新了一些别的表的记录 ...
UPDATE hero SET name = '赵云' WHERE number = 1; UPDATE hero SET name = '诸葛亮' WHERE number = 1;此刻,表hero中number为1的记录的版本链就长这样:

然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,如下:
# 使用REPEATABLE READ隔离级别的事务
BEGIN;
# SELECT1:Transaction 100、200均未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值为'刘备'
# SELECT2:Transaction 100提交,Transaction 200未提交
SELECT * FROM hero WHERE number = 1; # 得到的列name的值仍为'刘备'这个SELECT2的执行过程如下:
因为当前事务的隔离级别为REPEATABLE READ,而之前在执行SELECT1时已经生成过ReadView了,所以此时直接复用之前的ReadView,之前的ReadView的m_ids列表 的内容就是[100, 200],min_trx_id为100,max_trx_id为201,creator_trx_id为0。
然后从版本链中挑选可见的记录,从图中可以看出,最新版本的列name的内容是'诸葛亮',该版本的trx_id值为200,在m_ids列表内,所以不符合可见性要求,根据roll_pointer跳到下一个版本。
下一个版本的列name的内容是'赵云',该版本的trx_id值为200,也在m_ids列表内,所以也不符合要求,继续跳到下一个版本。 下一个版本的列name的内容是'张飞',该版本的trx_id值为100,而m_ids列表中是包含值为100的事务id的,所以该版本也不符合要求,同理下一个列name的内容是'关羽'的版本也不符合要求。
继续跳到下一个版本。 下一个版本的列name的内容是'刘备',该版本的trx_id值为80,小于ReadView中的min_trx_id值100,所以这个版本是符合要求的,最后返回给用户的版本就是这条列c为'刘备'的记录。
也就是说两次SELECT查询得到的结果是重复的,记录的列c值都是'刘备',这就是可重复读的含义。如果我们之后再把事务id为200的记录提交了,然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,得到的结果还是'刘备'。
3:sql加锁分析
3.1:组合一:id列是主键,RC隔离级别
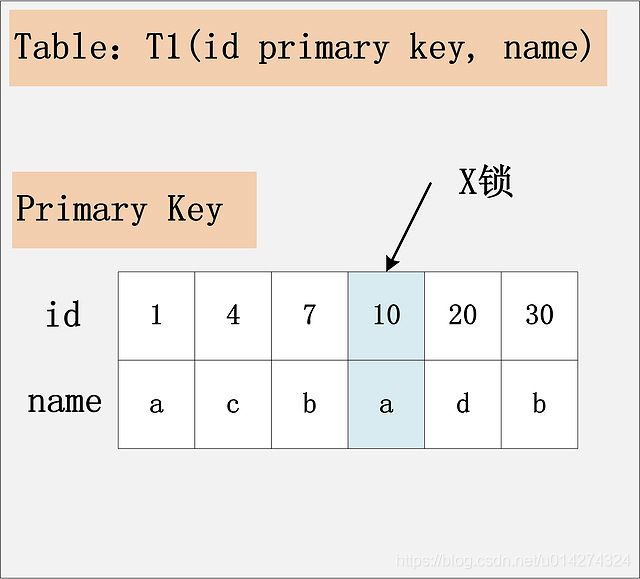
id是主键,Read Committed隔离级别,给定SQL:delete from t1 where id = 10; 只需要将主键上,id = 10的记录加上X锁即可。
3.2:组合二:id唯一索引+RC

id是唯一索引,Read Committed隔离级别,给定SQL:delete from t1 where id = 10; 此组合中,id是unique索引,而主键是name列。首先会将unique索引上的id=10索引记录加上X锁,同时,会根据读取到的name列,回主键索引(聚簇索引),然后将聚簇索引上的name = ‘d’ 对应的主键索引项加X锁。
3.3:组合三:id非唯一索引+RC
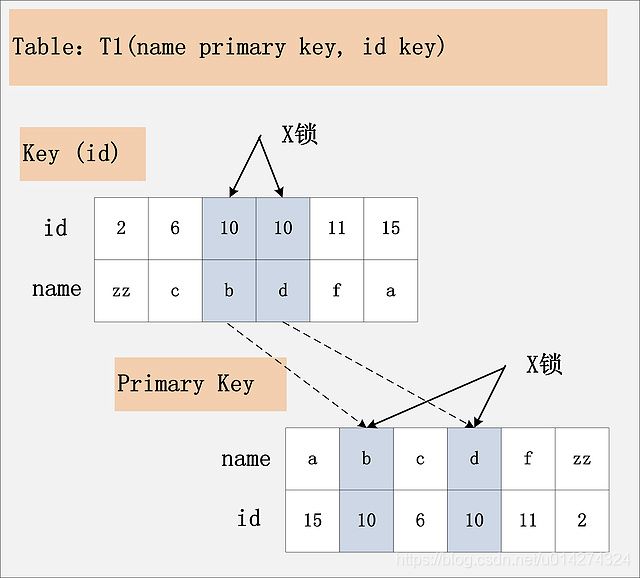
id是普通索引,Read Committed隔离级别,给定SQL:delete from t1 where id = 10; 此组合中,id是普通索引,而主键是name列。首先,id列索引上,满足id = 10查询条件的记录,均已加锁。同时,这些记录在主键索引上的记录,也会被加锁。
3.4:组合四:id无索引+RC
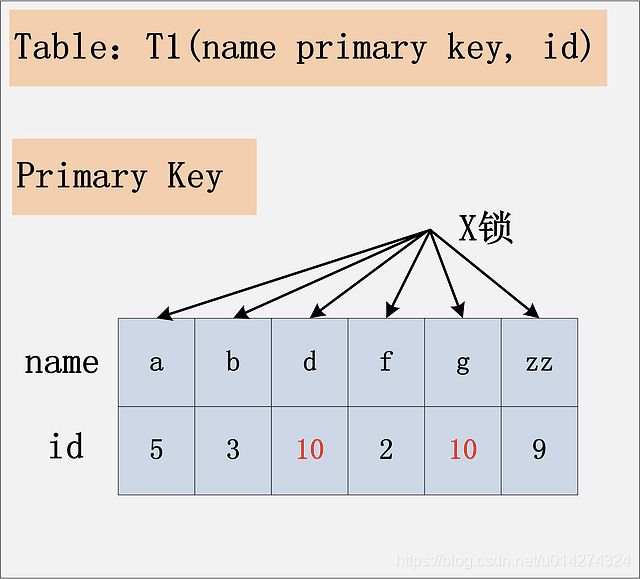
id是无索引,Read Committed隔离级别,给定SQL:delete from t1 where id = 10; 此组合中,id是无索引,而主键是name列。由于id列上没有索引,因此只能走聚簇索引,进行全部扫描。
3.5:组合五:id主键+RR
id列是主键列,Repeatable Read隔离级别,针对delete from t1 where id = 10; 这条SQL,加锁与组合一:[id主键,Read Committed]一致。
3.6: 组合六:id唯一索引+RR
与组合五类似,组合六的加锁,与组合二:[id唯一索引,Read Committed]一致。两个X锁,id唯一索引满足条件的记录上一个,对应的聚簇索引上的记录一个。
3.7:组合七:id非唯一索引+RR
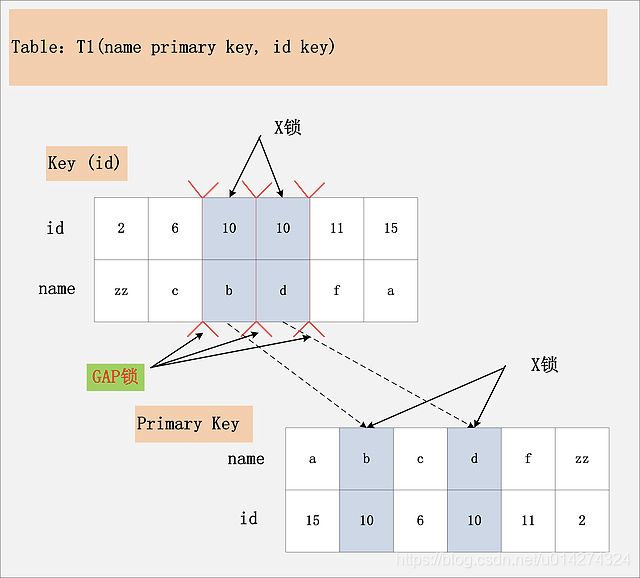
相对于组合三:[id列上非唯一锁,Read Committed]看似相同,其实却有很大的区别。
首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
3.8:组合八:id无索引+RR

当然,跟组合四:[id无索引, Read Committed]类似,锁上表中的所有记录,同时会锁上聚簇索引内的所有GAP,杜绝所有的并发 更新/删除/插入 操作。
4:explain简单使用

EXPLAIN SELECT age,name from test where age > 11 and age < 15

id:选择标识符 select_type:表示查询的类型 table:输出结果集的表 partitions:匹配的分区 type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引 key:表示实际使用的索引 key_len:索引字段的长度 ref:列与索引的比较
rows:扫描出的行数(估算的行数) filtered:按表条件过滤的行百分比 Extra:执行情况的描述和说明
在这些元素里面,可能大家经常使用的type 和 extra,其他的也重要,有兴趣的可以自己去搜索一下,像物化表这些,在目前的环境中,公司是不允许出现太复杂sql的,太复杂的sql,如果做架构升级,那也是噩梦,所以一般的sql都是单表操作的。
4.1:type属性
type:system 当表中只有一条记录并且该表使用的存储引擎的统计数据是精确的,比如MyISAM、Memory,那么对该表的访问方法就是system。比方说我们新建一个MyISAM表,并为其插入一条记录:

type:const 当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const

type:eq_ref 在连接查询时,如果被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较),则对该被驱动表的 访问方法就是eq_ref

type:ref 当通过普通的二级索引列与常量进行等值匹配时来查询某个表,那么对该表的访问方法就可能是ref
type:ref_or_null 当对普通二级索引进行等值匹配查询,该索引列的值也可以是NULL值时,那么对该表的访问方法就可能是ref_or_null

type:range 如果使用索引获取某些范围区间的记录,那么就可能使用到range访问方法

type:index 当我们可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是index
 type:all 最熟悉的全表扫描
type:all 最熟悉的全表扫描

4.2:extra属性
extra:Using index 当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用索引覆盖的情况下,在Extra列将会提示该额外信息

extra:Using where 当我们使用全表扫描来执行对某个表的查询,并且该语句的WHERE子句中有针对该表的搜索条件时,在Extra列中会提示上述额外信息

extra:Using index condition
有些搜索条件中虽然出现了索引列,但却不能使用到索引,比如下边这个查询:
SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';
其中的key1 > 'z'可以使用到索引,但是key1 LIKE '%a'却无法使用到索引,在以前版本的MySQL中,是按照下边步骤来执行这个查询的:
先根据key1 > 'z'这个条件,从二级索引idx_key1中获取到对应的二级索引记录。
根据上一步骤得到的二级索引记录中的主键值进行回表,找到完整的用户记录再检测该记录是否符合key1 LIKE '%a'这个条件,将符合条件的记录加入到最后的结果集。 但是虽然key1 LIKE '%a'不能组成范围区间参与range访问方法的执行,但这个条件毕竟只涉及到了key1列,所以设计MySQL的大叔把上边的步骤改进了一下:
先根据key1 > 'z'这个条件,定位到二级索引idx_key1中对应的二级索引记录。
对于指定的二级索引记录,先不着急回表,而是先检测一下该记录是否满足key1 LIKE '%a'这个条件,如果这个条件不满足,则该二级索引记录压根儿就没必要回表。 对于满足key1 LIKE '%a'这个条件的二级索引记录执行回表操作。

extra:using index & using where 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据,这个和上面的相对,select后面的列在索引上都有,不需要回表,而上面的有部分列没有,需要回表。
5:总结
上面只说了最经常用的,有些东西说的不全,就先这样吧。