如何解决大规模高性能存储可靠性问题?

凌云时刻 · 技术


导读:阿里云操作系统团队,阿里云存储团队以及上海交通大学新兴并行计算研究中心一起合作的论文 “Spool: Reliable Virtualized NVMe Storage Pool in Public Cloud Infrastructure” 被系统领域著名会议 2020 USENIX Annual Technical Conference(USENIX ATC'20)录用为长论文。USENIX ATC 由 USENIX 协会创办于 1992 年,是计算机系统领域顶级会议(CCF A)类会议,今年录用了 65 篇论文,录用率为 18.6%。
论文作者 | 咸正、笑意、陈全、据德、文卿、木芽、文侑、伯瑜、智彻、凌一、云及、思杰、过敏意
来源 | 云巅论剑
前言

Spool 是我们 4 年前提出并在阿里云块存储持续落地的解决方案,Spool 阐述了阿里云如何解决本地 SSD 实例存储服务的可靠性,以 2.97% 的性能损失,减少 94% 的数据丢失和 90.58% 的启动时间,并帮助基于 SPDK 的 NVMe 大规模稳定可靠的应用于生产,目前包括阿里云最新一代云存储 ESSD 也一直沿用 Spool 技术,这次我们的工作也又一次得到了系统顶级学术会议的认可,我们将在这篇文章中详细介绍 Spool 的工作细节。
摘要
确保虚拟化 NVMe存储系统的高可靠和高可用,对于大规模云服务至关重要。然而,以前的I/O虚拟化系统只注重提高I/O性能,而忽略了上述挑战。为此,我们提出了Spool,一个全链路可靠的 NVMe 虚拟化云存储解决方案。
Spool 有三个主要优点:
(1) Spool对NVMe设备进行故障诊断,仅对介质故障的磁盘进行热插拔替换,其他故障类型的磁盘通过重置磁盘控制器来处理,减少了由于不必要的磁盘更换而造成的数据丢失。
(2) Spool确保在重置控制器和热升级时的数据一致性和正确性。
(3) Spool大大缩短了NVMe 云存储系统服务重启时间,快速重启减少了在热升级和故障恢复期间的服务不可用时间,与 SPDK相比减少了 90.58% 的重启时间。
介绍
在大规模公有云中,CPU和内存被虚拟化,并由多个租户共享。单个物理服务器最多可以为来自相同租户或不同租户的100个虚拟机(VM)提供服务。虚拟化I/O设备以便租户共享I/O设备引起了工业界和学术界的关注。
Guest VM 主要通过高吞吐量和低延迟的I/O虚拟化服务在本地设备上存储和访问其数据,各大云厂也都为高I/O吞吐量和低延迟的工作负载推出了下一代本地SSD存储优化型实例。对于云供应商来说,高可用是最重要但也是最具挑战性的问题,特别是使用本地磁盘的实例。之前的研究工作主要关注于提高虚拟化NVMe设备的吞吐和降低虚拟化NVMe设备的延迟上,而忽略了本地SSD存储优化型实例的可靠性问题。

当前虚拟化系统的可靠性,主要面临如下问题:
本地SSD存储优化型实例不支持热迁移。
本地SSD硬盘存储密度高,硬件故障率比通用型实例更高。
本地SSD硬盘存在单点故障的风险。
 不必要的数据丢失
不必要的数据丢失
如果在物理节点上检测到NVMe设备故障,则该硬盘处于故障状态。当一个节点上发生设备故障时,采用的通用做法(如Azure Lsv2 系列)是,该节点上的所有vm都会在被销毁并在正常节点上重新创建,该节点的租户需主动将数据加载到新节点上。之后,故障节点上的所有数据都会被安全地擦除。随着SPDK等虚拟化存储系统的出现,为了修复节点上的NVMe设备故障,管理员可以通过热插拔直接替换故障设备。
然而,由于单个NVMe设备可能存储来自多个租户的数据,并且NVMe设备具有较高的存储密度和较高的故障率,因此上述方法会导致巨大的不必要的数据丢失。我们在生产环境中收集了300000个NVMe设备故障,只有6%的硬件故障为介质故障,大多数硬件故障是由数据链路层中的错误(例如,命名空间错误、硬件链路错误、NVMe重置失败错误)引起的,这些故障可以通过重置NVMe控制器来解决。

高代价的内核态驱动
内核模式驱动程序可以访问系统地址空间并调用操作系统的内核函数,这些函数直接操作重要的系统结构。内核模式驱动程序中的错误可能会损坏这些结构,并可能导致系统崩溃。而用户态驱动程序只能访问运行自己的地址空间,一个损坏或错误的驱动程序可能会导致其设备无法运行,但它不太可能导致系统范围的问题。因此,用户态驱动有助于提高主机操作系统的稳定性。

此外,复杂的内核态驱动无法充分发挥NVMe设备的性能。最新一代NVMe固态硬盘(Samsung PM1735)支持高达150万IOPS和8K MB/s的顺序读取。随着硬件的发展,IO软件栈成为性能瓶颈。之前的研究表明,内核软件I/O栈占用了大量的执行时间,包括上下文切换、内核与用户空间之间的数据复制、中断、I/O栈中的共享资源竞争等开销。因此,我们的实现基于Intel开源的SPDK用户态驱动。
薄弱的可用性
在生产环境中,I/O虚拟化系统往往需要频繁升级以添加新功能或安全补丁。在升级I/O虚拟化系统时,关键要求是在确保数据正确性的同时尽量减少I/O服务停机时间。
云供应商可以使用两种方法:VM热迁移和实时升级。不幸的是,VM 热迁移对于常规的后端更新来说代价太高,特别是当需要更新大量后端时,例如,要应用紧急安全修补程序,对于具有本地NVMe的存储优化实例,云供应商甚至不支持VM热迁移(如Azure Lsv2)。我们唯一的办法就是支持热升级,并尽可能地消除服务停机时间。

I/O虚拟化系统将重新启动以完成热升级。使用SPDK驱动,我们需要初始化DPDK EAL库,probe NVMe设备,并初始化SPDK本身的内部数据结构。从图中可以看出,三星PM963固态硬盘的热升级导致的服务停机时间高达1200毫秒。对于英特尔P3600,总服务停机时间将更长,最长可达2500毫秒。
设计原则
为了解决传统NVMe虚拟化系统的诸多问题,我们提出了Spool,一个全链路的NVMe虚拟化系统。设计的考虑目标为:
应识别设备故障的原因,并采用不同的方法处理故障,从而消除大部分不必要的NVMe设备更换。
应尽可能减少热启动的时间。
应确保Guest的数据访问请求不会在控制器重置和系统热升级时丢失。

基于Spool,节点上的NVMe设备被虚拟化并组织为存储池( Storage Pool ,Spool)。虚拟化的NVMe设备被分成多个逻辑卷,这些逻辑卷通过buddy system算法进行分配管理。虚拟机以块设备的形式使用逻辑卷。如图6所示,host上的I/O worker从块设备的vhost virtqueue中提取I/O请求并提交给相应的物理设备。
Spool由跨进程生命周期的日志(journal)、基于隔离的故障恢复组件和快速重启组件组成。基于这三个组件,Spool确保了存储池的高可靠和高可用。
跨进程生命周期的journal
IO请求路径上的可靠性问题

IO请求以生产者-消费者模型在guest和host之间传递。具体地,io驱动程序维护一个available ring和一个used ring来管理其I/O请求。提交一个I/O请求时,该请求的描述符链被记录到descriptor table中。请求的描述符链包括请求的元数据、缓冲区和状态。简要IO处理流程如下:
Guest将请求描述符链的head index放入available ring中,guest的 available index加一,通知存储虚拟化系统存在可用的I/O请求。
Host的存储虚拟化系统获取available ring待处理I/O请求的head index,host的 last available index加一,并将I/O请求提交给NVMe设备硬件驱动程序。
待请求完成后,host的存储虚拟化系统将已完成请求的head index放入used ring中,host的used index加一,并通知guest。
存储虚拟化系统可以采用中断(Interupt)或轮询(Polling)的方式从guest获取I/O请求。之前的研究表明,Polling能够充分利用NVMe设备的优势来获得显著的性能优势,因此,Spool采用专用的I/O线程从guest获取I/O请求并从NVMe设备读取数据,该机制是基于SPDK用户态NVMe驱动程序实现的。
一般来说,上述IO处理流程运行良好。但是,如果存储虚拟化系统重新启动以进行升级或重新设置NVMe设备控制器,则可能会发生数据丢失。
在图7中,Spool获得两个I/O请求,分别是IO1和IO2,然后更新last available index。如果存储虚拟化系统此时重新启动,则last available index将丢失,这将导致Spool不知道从哪接着做。即使将last available index持久化,IO1和IO2是否已被处理,也无从得知。如果获得的两个I/O请求IO1和IO2尚未完成,则意味着数据丢失。
此外,当我们重置NVMe设备的控制器时,将清除所有管理队列(admin queue)和I/O队列(I/O queue)。假设Spool已经将IO1和IO2提交给设备,但它们仍在I/O队列中,尚未处理。由于缺少I/O请求的完成状态,已清除的I/O队列中提交的I/O请求也会丢失。
journal的设计
为了解决Spool重启或设备控制器重置导致的数据丢失问题,我们提出了一种跨进程生命周期的journal,将数据持久化保存在共享内存中。
Spool将以下数据保存在journal中:
available ring的last available index。last available index记录了Spool从available ring读取的最新请求的起始描述符索引。
从available ring中获取的IO请求的head inex。head inex指的是一个IO请求在描述符表中头索引。
通过last available index,Spool重新启动升级后,可以知道哪些请求已被完成,从而继续处理其余待处理的请求。Spool在处理I/O请求时,将请求赋予三种状态之一:INFLIGHT、DONE和NONE,如算法1所示。

当Spool从Guest收到请求时,首先持久化的该请求的head inex,并将该请求标记为INFLIGHT,最会更新last available index,然后将该请求提交给硬件驱动程序。一旦设备完成该I/O请求,Spool将更新该请求的状态为DONE。之后,Spool将此请求的结果放入used ring,更新used index,并将该请求标记为NONE。
合并journal更新的指令
直观的想法是使用共享内存作为日志,以低延迟开销持久化需要的信息。但是,如何以较低开销确保journal本身的一致性是一项挑战,因为Spool需要在处理I/O请求期间多次更新日志。
具体来说,Spool中每个I/O请求的处理过程包括:更新最后一个可用的索引,将请求的状态标记为INFLIGHT,在处理过程中,如果Spool重新启动或控制器在前两条指令之间重置,则此请求将丢失。如果我们能保证算法1中的指令3(更新last available index)和指令6(更改请求的状态)以原子方式执行,那么请求丢失问题就可以得到解决,然而,现代处理器只能保证64位读写的原子性。

为了解决上述问题,我们设计了一个多指令事务模型来保证这两条指令的原子执行。如图8所示,每个事务由三个阶段组成。在T0(init阶段)中,我们保留要修改的变量的副本,例如last available index。在T1中,事务处于START状态,修改journal中的变量。所有指令完成后,事务将在T2中处于FINISHED状态。如果一个事务失败,我们通过保存的副本回滚该事务以删除所有数据修改。事务的状态可以原子更新,因此可以有效判断事务的状态。

然而,在高吞吐、低延迟的场景下,每一个IO请求保存副本依然有不小开销。我们设计了一个aux数据结构,以消除在T0中进行保存副本的开销。相关请求的状态、last available index和head index将填充到64位,并将其内与一个64位值联合,如图9所示。在算法1中的步骤5,我们可以通过一条指令中更新这三条记录。
通过journal进行故障恢复
在重启后,Spool使用算法2,进行故障恢复。

如果事务的状态为START,则完成该事务。对于恢复算法基于guest中last used index的和日志中used index。如果它们相等,Spool可能在算法1中的步骤13之后崩溃,但我们不知道步骤14是否完成。因此,Spool再次尝试执行步骤14,并将DONE请求的状态更改为NONE。否则,请求的过程可能在步骤10到12之间中断。在这种情况下,我们不知道该请求是否已提交到guest。为了避免丢失任何I/O请求,我们还将所有DONE状态的请求标记为INFLIGHT。由于guest总是有正确的数据,我们将日志中last used index的和guest中used index同步。最后,Spool重新提交所有处于INFLIGHT状态的请求。
在我们目前的实现中,我们为每个vring对维护一个单独的日志,以避免单个journal导致不必要的竞争。单个journal的大小只有368字节,因为它只记录journal本身的元数据和IO请求的索引。注意,上面的算法没有对journal溢出采取预防措施,这是因为jouranl的大小与available相同,guest驱动程序将阻止这种情况发生。
热升级启动加速
如图5所示,当重新启动Spool时,它初始化DPDK中的EAL库,并probe host上的NVMe设备。在重新启动完成之前,整个存储系统都停止服务,较长的重新启动时间(从450 ms到2500 ms)会严重影响系统的可用性。
复用配置

DPDK中EAL库的初始化过程中大约需要800ms,大部分的时间消耗在对大页(hugepage)物理内存布局信息的获取上。这一过程中,首先将所有可用的hugepage映射到进程地址空间,读取/proc/self/pagemap找到相应的物理地址,对物理地址排序及合并,然后选取尽可能物理连续的hugepage来作为内存分配的物理空间,而不需要的hugepage则unmap掉。理论上,EAL库的初始化一次就足够,后续只要不删除hugepage文件,那么物理内存布局并不会变,只是可能不是最佳的连续物理内存布局(比如释放hugepage,产生了更连续的物理内存段),不过不影响使用。
基于以上发现,我们对Spool的初始化步骤进行了优化。具体来说,重新启动后的新Spool进程重用之前Spool进程的内存布局信息。图10展示了复用内存内存布局的方法。如图所示,在第一次启动Spool之后,我们将相关信息(例如,正在使用的大页面,大页面的虚拟地址)存储在内存中驻留的内存映射文件中。当Spool重新启动时,它直接从内存中的内存映射文件获取所需的信息。具体来说,rte_config文件存储全局运行时配置,ret_hugepageinfo文件存储与Spool使用的hugepage相关的内存布局信息。
跳过重置设备控制器
在SPDK驱动probe NVMe设备时,90%以上的时间是通过重置NVMe设备的控制器花费的。在英特尔P3600固态硬盘上,NVMe探测阶段需要超过1500毫秒。在重置设备控制器过程中,SPDK释放控制器中的管理队列、I/O队列,并在重置后为控制器再次创建它们。
与SPDK相比,Spool在重启过程中跳过了重置控制器的过程,重用了之前控制器的数据结构。host的所有的NVMe设备都是通过Spool来管理的,因此控制器中的数据结构是有效的。为了实现重用,Spool将NVMe设备控制器相关信息保存在内存映射文件nvme_ trl中,在Spool重新启动后,它将重用设备控制器的数据。
这里最具挑战性的部分是,随着Spool的退出,I/O请求的上下文已经消失。因此,我们需要确保管理队列和I/O队列是完全干净的。为此,我们捕获终止信号SIGTERM、SIGINT,在Spool进程终止前,确保所有已提交的请求完成。对于进程中无法处理的SIGKILL信号或异常退出,我们在重启后需要重置控制器。
故障处理机制
传统上,任何NVMe设备硬件故障都会导致整个机器离线并进行修复,故障节点上的所有vm都需要主动迁移到正常节点。随着SPDK等虚拟化存储系统的出现,为了修复节点上的NVMe设备故障,管理员可以通过热插拔直接替换故障设备。然而,不必要的硬件替换,一方面给用户造成数据丢失,另一方面也增加了运营成本。
为了最大限度地减少数据丢失和降低运行成本,我们实现了故障诊断,以识别硬件故障类型,有效地避免不必要的硬件更换。在大规模云中,硬件故障频繁,主要表现为SIGBUS处理和IO hang,如图11。

Spool采用用户态的SPDK NVMe 驱动访问本地NVMe PCIe SSD。NVMe SSD的基址寄存器(BAR)空间将通过VFIO映射到用户进程中,从而允许驱动程序直接执行MMIO。当Guest向设备发送I/O时,Spool将直接访问设备的地址空间。但是,当设备出现故障或被热删除时,BAR可能会变得无效。此时,如果Guest仍向出现故障的host设备发送I/O请求,将触发SIGBUS错误并导致Spool进程崩溃。为了提高可靠性,我们将SIGBUS处理程序注册到Spool中。一旦Guest向出现故障的设备发送I/O并访问非法的BAR空间,处理程序将捕获SIGBUS错误,并将无效的BAR空间重新映射,以便不再触发SIGBUS错误。
在保证Spool稳定运行的前提下,我们通过对设备的S.M.A.R.T 数据进行分析,诊断故障原因。若设备为介质故障,Spool会主动使提交的IO请求失败并返回IO错误。在新磁盘热插拔之前,所有后续请求都将直接返回IO错误。如果设备由于其他错误而失败,则重置设备控制器,这一期间,Guest的IO请求阻塞。待设备修复后,journal中的INFLIGHT IO请求将自动重新提交,Guest的IO请求恢复。
实验数据分析
实验配置
测试平台如表一所示。

测试参数如表二所示。

处理硬件故障的可靠性
当NVMe发生硬件故障时,Spool会隔离故障设备、进行设备更换或控制器重置。在处理此类故障时,Spool不应影响同一节点的其他设备上的I/O操作,使用故障设备的vm应接收I/O错误,而不是异常退出。
在实验中,我们在一个硬件节点上启动两个vm,该节点配备两个NVMe,每个vm使用一个NVMe。两个vm在开始时随机从NVMe读取数据,我们手动移出其中一个NVMe并观察两个vm的行为。

图12中,在80s时热删除NVMe设备(SSD2)后两个vm的I/O性能。热删除是将非零值写入/sys/bus/pci/devices/../remove。从图中可以看出,当删除SSD2时,使用NVMe设备SSD1的VM1的I/O性能不受影响。同时,删除SSD2后VM2不会异常退出。一旦新的SSD设备替换出故障的SSD2或SSD2的控制器在95s被重置成功,VM2就能够直接使用SSD2而不受任何用户干扰。
Spool能够捕获硬件热插拔事件,并首先诊断设备故障类型。硬件故障的处理有两种方式:介质故障通过热插拔新硬盘来解决,然后存储服务自动恢复,其中相关逻辑设备自动映射到新设备;而数据链路故障则由重置控制器来处理,而不是替换硬盘。相反,如果用传统的SPDK来管理SSD,硬件故障只能热插拔,造成不必要的数据丢失。而且SPDK的存储服务需要手动重置才能恢复。
应对随机升级的可靠性
为了验证Spool在处理升级过程中的可靠性,同时又不会导致数据丢失,我们设计了一个实验,人为随机终止并重新启动Spool。我们利用FIO中的数据验证功能来检验数据的一致性。通过启用数据验证功能,FIO在连续使用crc32写入10个块后验证文件内容,并报告是否发生数据损坏。

图13是人为restart、stop并start、随机kill并restart Spool时SSD的读写性能。从图中可以看出,对SSD的I/O操作最终正确完成,即使Spool是直接kill并restart也没有影响。
Spool可以保证升级时的数据一致性,这得益于跨进程生命周期的journal。Journal保存所有NVMe设备的当前状态。无论何时重新启动Spool,它都能够恢复重新启动前的状态,并继续完成未处理的I/O请求。相反,SPDK没有保证机上I/O数据一致性的机制。
减少重启时间

从图14可以看出,在三星PM963固态硬盘上,Spool将总重启时间从1217.96ms减少到114.68ms。重启时间的减少源于EAL初始化时间和NVMe探测时间的减少。
SPDK的EAL初始化时间和NVMe探测时间都很长,因为它在每次启动时都会在探测期间初始化EAL并重置设备的控制器。相反,通过重用以前的内存布局信息,Spool将EAL初始化时间最小化。同时,跳过复位装置控制器也减少了NVMe的探测时间。
Spool的I/O性能
在保证可靠性的同时,高I/O性能(即高IOPS和低延迟)至关重要。在本小节中,我们将测试两种情况下Spool的I/O性能,在两种情况下:NVMe设备仅分配给单个VM,NVMe设备由多个VM共享。
 CASE 1
CASE 1

在图15中,native代表直接在主机节点上测量的SSD性能;SPDK vhost blk和SPDK vhost scsi分别代表SPDK作为blk设备或scsi设备时SSD的性能。可以看出,与native相比,由于虚拟化系统中存在额外开销,所有I/O虚拟化系统都会导致更长的数据访问延迟。同时,Spool达到了与SPDK接近的数据访问延迟。从IOPS的角度看,Randread的IOPS比Virtio高2.54X,甚至略好于native。与SPDK vhost blk相比,我们实现的性能几乎相同。由于SPDK vhost blk软件栈额外开销比SPDK vhost scsi小,因此SPDK vhost scsi的IOPS比Spool的低。
CASE 2

在图16中,我们将一个SSD划分为三个逻辑磁盘,并将每个逻辑磁盘分配给一个单独的VM,验证了Spool在NVMe设备上处理多个vm的有效性。
图16的每个值是所有虚拟机的总和。对于延迟测试,我们运行每个benchmark10次,并记录平均延迟。可以看出,与SPDK vhost blk和SPDK vhost scsi相比,Spool不会显著降低benchmark的I/O性能。除此之外,Spool与SPDK vhost blk相比,将Randread的IOPS提高了12.8%,与SPDK vhost blk和SPDK vhost scsi相比,将Randread的平均数据访问延迟分别降低了54.2%到54.6%。
另外通过比较图15(b)和图16(b)发现,当一个虚拟机和三个虚拟机使用SSD时,SSD设备达到了相接近的IOPS。当三个vm共享SSD时,benchmark的数据访问延迟是案例1的三倍。这是合理的,因为后端I/O负载压力随虚拟机的数量线性增加,因此三个虚拟机的总延迟增加。虽然一个虚拟机的I/O负载压力已达到Samsung PM963的吞吐量限制,但三个虚拟机的总IOPS保持不变。由于Spool和SPDK使用不同的逻辑卷管理机制,所以Spool的I/O性能略优于SPDK。Spool使用buddy系统来管理逻辑卷,而SPDK使用Blobstore。
journal的开销

我们比较了使用journal(Spool)和不使用journal(Spool-NoJ)时的性能,如图17所示,Spool NoJ和Spool拥有几乎一样的数据访问延迟和IOPS。与Spool NoJ相比,Spool增加的平均数据访问延迟不超过2.97%。同时,Spool与Spool NoJ相比,IOPS降低不到0.76%。
在阿里云中的应用
我们目前在210个集群中部署Spool,大约20000台物理机,配备超过200000个NVMe SSD,提供低延迟、高IOPS和高吞吐量I/O支持的平台即服务云(IaaS)。生产中的云托管包括Cassandra、MongoDB、Cloudera和Redis等应用,是大数据、SQL、NoSQL数据库、数据仓库和大型事务数据库的理想选择。
一个完整的全链路监测系统对大规模云来说至关重要。当监控系统能够诊断介质错误和其他SSD故障时,Spool以不同的方式处理这些故障。我们的统计数据显示,目前的硬件故障率全年约为1.2%。
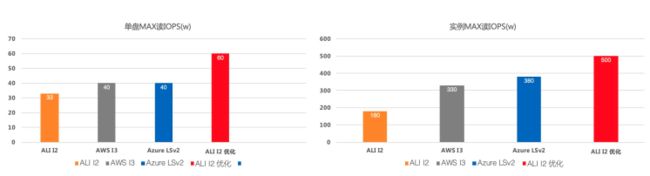
从系统升级方面,我们每六个月发布一个新版本的Spool,每年总共在40000多台物理机器上升级Spool。新版本的目的是解决两个问题:1)发布新功能;2)在运行和维护阶段修复在线稳定性反馈。大多数新特性都与性能有关,如添加对多队列的支持、优化内存DMA操作、优化内存池。Spool支持的最新实例,单盘最大读IOPS提升约1倍,比竞品高出50%;最大规格实例的最大读IOPS提升1.2倍,比竞品高出40%。
总结
本文介绍了全链路可靠的虚拟化存储系统Spool,它能够处理部分硬件故障并且支持NVMe虚拟化系统升级。Spool通过在系统升级重启时重用数据结构,显著减少了90.58%的重启时间(对比实验使用三星PM963固态硬盘)。与SPDK等新兴的虚拟化存储系统相比,Spool支持热升级,并能随时保证基于共享内存日志的数据一致性。此外针对硬件故障,Spool能够诊断设备故障类型,而不是直接热插拔,借此避免了许多不必要的NVMe设备更换。
END

往期精彩文章回顾

掌门教育微服务体系 Solar(中)
演过电影的无人驾驶卡车是如何炼成的?
全部满分!阿里云函数计算通过可信云21项测试
如何应对容器和云原生时代的安全挑战?
融合阿里云,牛客助您找到心仪好工作
掌门教育微服务体系 Solar
阿里云上新了!
我们该不该在Rust上做点投资?
云原生时代,谁是容器的最终归宿?
解读畅捷通微服务治理能力提升之路

长按扫描二维码关注凌云时刻
每日收获前沿技术与科技洞见