创建MapReduce程序,并在hadoop集群中运行
关键词: MapReduce, hadoop 2.6.0, intellij IDEA, Maven
1、在intellij IDEA下创建maven项目
2、引入hadoop相关jar包
3、创建MapReduce程序(程序的思想copy来的)
package cn.edu.kmust.cti;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author [email protected]
* @since 15-3-27
*/
public class Dedup {
public static class Map extends Mapper {
private static Text line = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//super.map(key, value, context);
line = value;
context.write(line, new Text(""));
}
}
public static class Reduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "10.211.55.6:9001");
Job job = Job.getInstance(conf, "Data Deduplication");
job.setJarByClass(Dedup.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,
new Path("hdfs://hadoop1:9000/dedup_in"));
FileOutputFormat.setOutputPath(job,
new Path("hdfs://hadoop1:9000/dedup_out"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
说明:
10.211.55.6 hadoop集群namenode的ip地址
dedup_in hadoop文件夹名称,MapReduce的输入路径
dedup_out hadoop文件夹名称,MapReduce的输出路径
4、打jar包
参考:http://bglmmz.iteye.com/blog/2058785
a、不能通过mvn package打包,原因:打入不了所依赖的第三方jar包等
intellij IDEA -> File -> Project Structure

-> OK
b、intellij IDEA -> Build -> Build Artifacts
-> Build / Rebuild
5、将程序传输到hadoop集群的namenode上
scp ./out/artifacts/HadoopDemo_jar/* [email protected]:/home/user/hadoop/dedup/
查看linux服务器
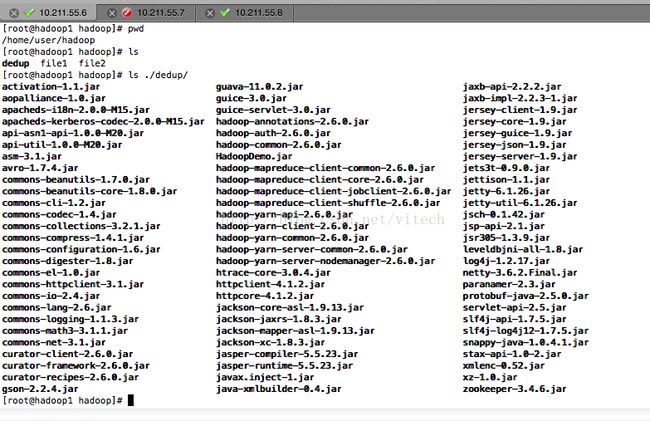
说明:
file1和file2为程序用到的数据文件,一会儿将上传到hadoop集群中
6、准备程序使用的数据

在hadoop集群的namenode节点,创建文件夹、上传文件
hadoop fs -mkdir /dedup_in
hadoop fs -mkdir /dedup_out
hadoop fs -put /home/user/hadoop/file1 /dedup_in/
hadoop fs -put /home/user/hadoop/file2 /dedup_in/
查看
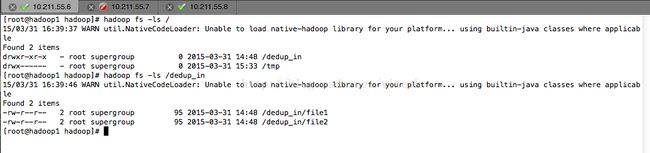
7、运行程序
hadoop jar ./dedup/HadoopDemo.jar /dedup_in /dedup_out
执行过程



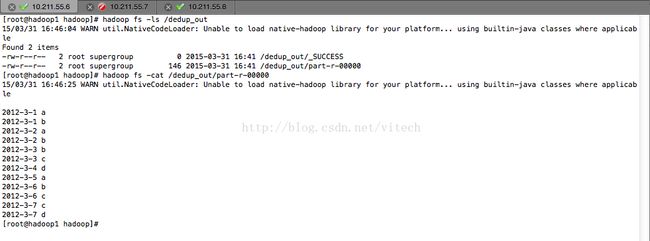
8、查看计算结果