爬虫之——Beautiful Soup基础
爬虫之——Beautiful Soup
Beautiful Soup库也叫beautifulsoup4,还叫bs4
一、beautiful soup库的安装
- win+R,输入cmd打开命令行
- 输入pip install beautifulsoup4
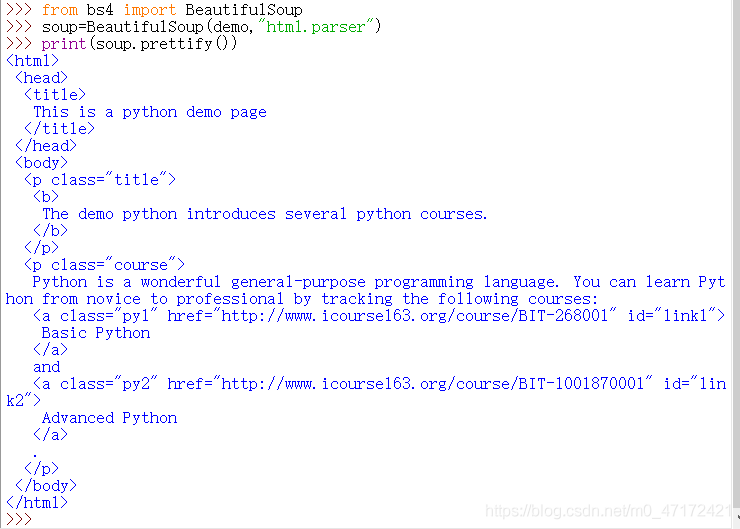
BeautifulSoup小测:以https://www.python123.io/ws/demo.html页面的代码为例
import requests
url="https://www.python123.io/ws/demo.html"
r=requests.get(url)
r.text
#输出html界面内容
demo=r.text
from bs4 import BeautifulSoup
soup=BeautifulSoup(demo,"html.parser") #demo可以换成open("本地文件地址")
print(soup.prettify())
#此时的html页面是带格式的
二、Beautiful Soup库的基本元素
Beautiful Soup库是解析、维护、遍历“标签树”的功能库。只要提供的文件类型是标签树的形式,BeautifulSoup库都可以对该文件进行解析。
1.Beautiful Soup库的引用
- 常用
from bs4 import BeautifulSoup
- 需要对Beautiful Soup库里变量进行判断时
import bs4
*BeautifulSoup对应一个HTML/XML文档的全部内容

2.Beautiful Soup 库解析器
1.bs4的HTML解析器:
- 使用方法:BeautifulSoup(mk,‘html.parser’)
- 条件:安装bs4库
2.Ixml的HTML解析器:
- 使用方法:BeautifulSoup(mk,‘ixml’)
-条件:pip install Ixml
3.Ixml的XML解析器:
- BeautifulSoup(mk,‘xml’)
- 条件:pip install Ixml
4.html5lib的解析器:
- 使用方法:BeautifulSoup(mk,‘html5lib’)
- 条件:pip install html5lib
3.Beautiful Soup 类的基本元素
1.Tag:标签,最基本的信息阻止单元,分别用<>和表明开头和结尾;
2.Name:标签的名字,< p>…< /p>的名字是"p",格式:< tag >.name;
3.Attributes:标签的属性,字典形式组织,格式:< tag >.attrs;
4.NavigableString:标签内非属性字符串,<>…中字符串,格式:< tag >.string【可以跨越多个层次】
5.Comment:标签内字符串的注释部分,一种特殊的Comment类型。
使用示范
import requests
from bs4 import BeautifulSoup
url="https://www.python123.io/ws/demo.html"
r=requests.get(url)
demo=r.text
soup=BeautifulSoup(demo,"html.parser")
soup.title #查看页面的标题
tag=soup.a #tag为a标签
tag #输出第一个遇到的tag的内容
#标签名的使用
soup.a.name #输出a标签的名字
soup.a.parent.name #输出a标签的父标签的名字
soup.a.parent.parent.name #输出a标签的父标签的父标签的名字
tag.name #也可以用这种形式输出 soup.a.name一样的效果
#属性的使用
tag.attrs #查看标签的属性
tag.attrs['class'] #获取class属性的值
tag.attrs['href'] #获取a标签的链接属性
type(tag.attrs) #查看标签的属性的类型(输出是字典类型)
type(tag) #查看标签的类型(输出是bs4的标签类型)
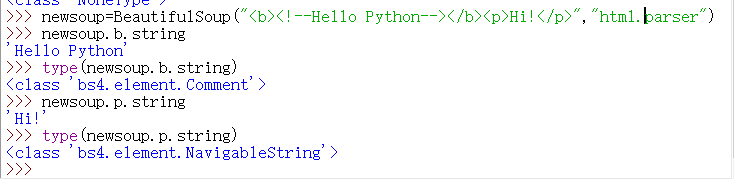
#注释的使用
newsoup=BeautifulSoup("Hi!
","html.parser")
newsoup.b.string
type(newsoup.b.string)
newsoup.p.string
type(newsoup.p.string)


三、HTML的遍历方法
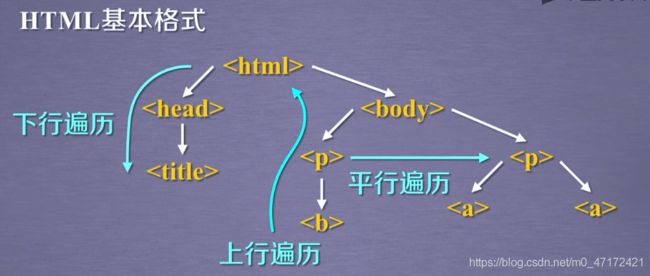
1.标签树的下行遍历
属性:
1…content:子节点的列表,将< tag >所有儿子节点存入列表;【仅获得当前节点的下一层的信息】

2…children:子节点的迭代类型,与。contents类似,用于循环遍历儿子节点;【仅获得当前节点的下一层的信息】

3…descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历。【可以获得当前节点的下面的所有层的信息】
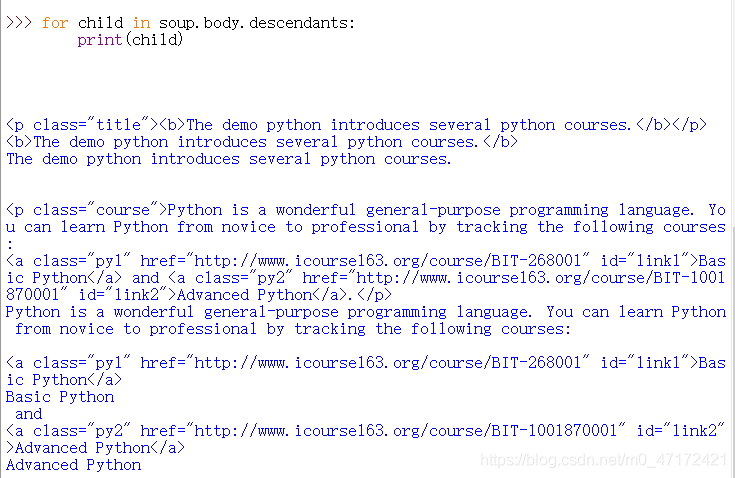
2.标签树的上行遍历
属性
1 .parent:节点的父亲标签;

2 .parents:节点先辈标签的迭代类型,用于循环遍历先辈节点。【上行遍历】

3.标签树的平行遍历
条件:平行遍历发生在同一个父节点的各节点间。
属性
-
.next_sibling:返回按照HTML文本顺序的下一个平行节点标签;
标签的平行遍历的下一个内容不一定为标签,也有可能是NavigableString

-
.previous_siblings:返回按照HTML文本顺序的上一个平行节点标签;
标签的平行遍历的前一个内容也不一定为标签,有可能是文本内容

-
.next_siblings:迭代类型,返回按照HTML文本顺序的后续所有平行节点标签;

-
.previous_siblings:迭代类型,返回按照HTML文本顺序的前续所有平行节点标签。

四、基于bs4库的HTML格式输出
使用bs4的prettify()方法,可以更好地显示html文件的格式。【bs4使用的编码形式默认为utf-8】

五、爬虫实例
功能描述:
- 输入:大学排名的链接。
- 输出:大学排名的信息。
- 技术路线:requests-bs4。
- 定向爬虫:仅对输入url进行爬取,不扩展爬取。
步骤:
- 从网页上获取大学排名的网页内容;
- 提取网页内容中信息到合适的数据结构中;
- 利用数据结构展示并输出结果。
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string])
def printU(ulist,num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo=[]
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html=getHTMLText(url)
fillUnivList(uinfo,html)
printU(uinfo,30)
main()
成功啦!但是文字不对齐TvT~~~

中文对齐问题的解决
中文不对齐的主要原因:
中文字符不够时会自动用英文字符做补充。

问题的解决:
使用中文字符的填充:chr(12288).
def printU(ulist,num):
tplt="{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))

小曦有话说:感谢路过的各位能够看到这里,本篇内容是学习嵩天教授的Python网络爬虫与信息提取课程的笔记,感兴趣的您可以前去溜溜。本篇文章为视频的学习笔记