关系数据库规范化逻辑设计----范式设计(NF,normalization)
文章目录
- 1. 范式设计是为了解决什么问题?
- 2. 几种常见的范式设计
- **先回顾一下三范式**:
- 2.1 第一范式(1NF)
- 2.2 第二范式(2NF)
- 2.3 第三范式(3NF)和扩充的第三范式(BCNF,Boyce Codd Normal Form)
- 2.3.1 第三范式(3NF)
- 2.3.2 扩充的第三范式(BCNF)
- 2.4 第四范式(4NF)
- 3. 总结
- 4. 范式设计需要注意的地方
- 5. 补充知识
- 5.1关系数据库模型
1. 范式设计是为了解决什么问题?
(1)数据冗余(某个分量重复出现很多次,导致存储空间的浪费)————减小冗余
(2)更新异常(修改某项属性时,导致其他表格的改属性都需要大量修改)————方便更新
(3)插入异常(缺少码值时,是不能执行插入操作的)————正常导入数据
(4)删除异常(即本来是想删除某项元组,但删除某项元组的同时,把不该删除的其他信息也删除了)
2. 几种常见的范式设计
(1)范式(NF):一张数据表的表结构所符合的某种设计标准的级别,分为1NF,2NF,3NF,BCNF,4NF,5NF。
(2)一般在我们设计关系型数据库的时候,最多考虑到BCNF就够。
(3)高一级范式的设计,必定符合低一级范式,例如符合2NF的关系模式,必定符合1NF。
先回顾一下三范式:
- 第一范式
定义:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。
理解:
1、每一列属性都是不可再分的属性值,确保每一列的原子性;
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。
例子:用户表的"地址"字段,需要拆分成 省 市 等字段。
- 第二范式:
定义:如果关系模式R满足1NF,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。
理解:每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
例子:一个人同时订几个房间,就会出来一个订单号多条数据,这样子联系人都是重复的,就会造成数据冗余。我们应该把该表拆成两个表。
- 第三范式:
定义:设R是满足1NF的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF。
理解:数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a–>b–>c 属性之间含有这样的关系,是不符合第三范式的。
例子:比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)。存在递推关系: 学号–> 所在院校 --> (院校地址,院校电话)。此时应该拆成两个表:
用户-院校关系表(学号,姓名,年龄,性别,所在院校)–
院校表(所在院校,院校地址,院校电话)
2.1 第一范式(1NF)
(1)定义:如果关系表的每个分量都是不可分的数据项,确保每一列的原子性,则该关系表满足第一范式。
(2)举例说明:
下表1是不符合1NF的示例

表2是符合1NF的示例

(3)1NF仍存在的问题:数据冗余过大,插入异常,删除异常,修改异常。比如表3
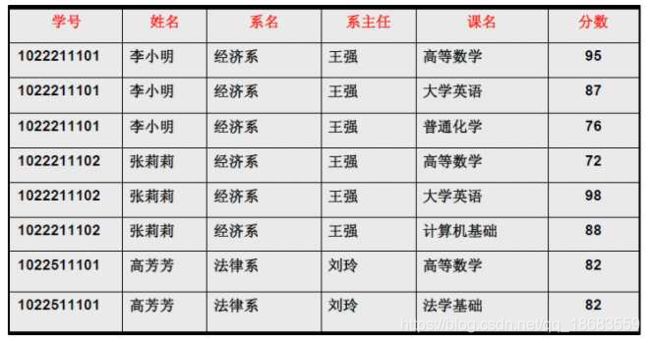
问题1. 每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次——数据冗余过大
问题2. 假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需修改三条记录中系与系主任的数据。——修改异常。
问题3. 假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)。——删除异常
问题4. 假如学校新建了一个系,但是暂时还没有招收任何学生,那么是无法将系名与系主任的数据单独地添加到数据表中去的——插入异常
2.2 第二范式(2NF)
(1)定义:如果关系表满足第一范式,且每个非主属性 完全函数依赖于 任何一个候选码,则该关系表满足第二范式。
(2)简单理解:在数据表中,X属性组能确定Y。即如果两行的X相同,则Y一定也相同的表。
(3)举例说明:
表4
| 关系分析 | 2NF逻辑设计 |
|---|---|
| 学号 → 姓名 学号 → 系名 学号 → 系主任 学号 → 系名 → 系主任 学号 + 课名 → 分数 |
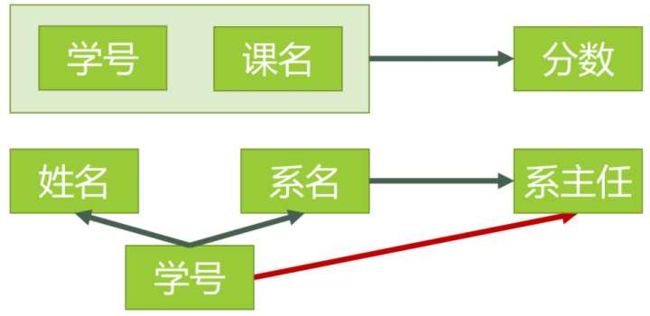 |
图1 是2NF的逻辑设计
表5 2NF设计表
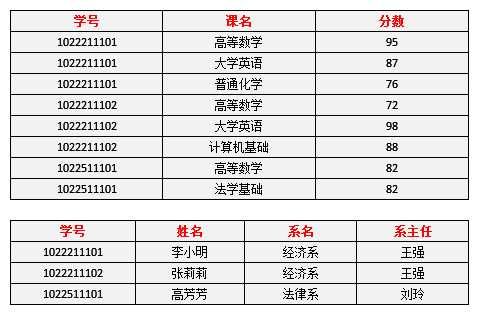
(4)2NF已经解决了的问题:
问题1. 数据冗余是否减少了?——学生的姓名、系名与系主任,不再像之前一样重复那么多次了。——有改进
问题2. 李小明转系到法律系——只需要修改一次李小明对应的系的值即可。——有改进
(5)2NF仍存在的问题
问题3. 删除某个系中所有的学生记录——该系的信息仍然全部丢失。——无改进
问题4. 插入一个尚无学生的新系的信息。——因为学生表的码是学号,不能为空,所以此操作不被允许。——无改进
(6)原因:仍然存在非主属性(系主任)对于码(学号)的传递函数依赖(学号 → 系名 → 系主任)。
2.3 第三范式(3NF)和扩充的第三范式(BCNF,Boyce Codd Normal Form)
2.3.1 第三范式(3NF)
(1)定义:如果关系模式R满足第一范式,且R中不存在这样的码,属性组Y和非主属性Z(Y不是Z的子集)使得X能确定Y,Y能确定Z成立,Y不能确定X,则该关系表满足第三范式。(第三范式属于第二范式)。
(2)简单理解:数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。
像:a–>b–>c 属性之间含有这样的关系,是不符合第三范式的。
(3)举例说明:
| 关系分析 | 3NF逻辑设计 |
|---|---|
| 选课(学号,课名,分数) 学生(学号,姓名,系名) 系(系名,系主任) |
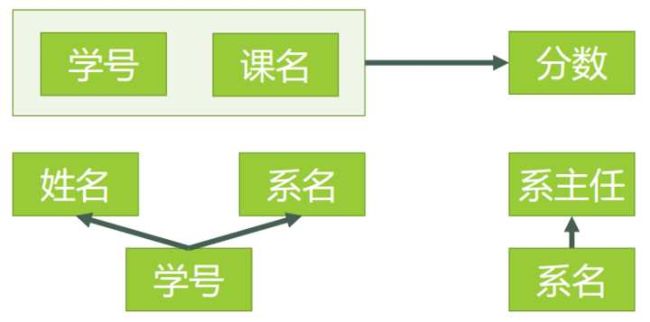 |
表6 3NF设计表
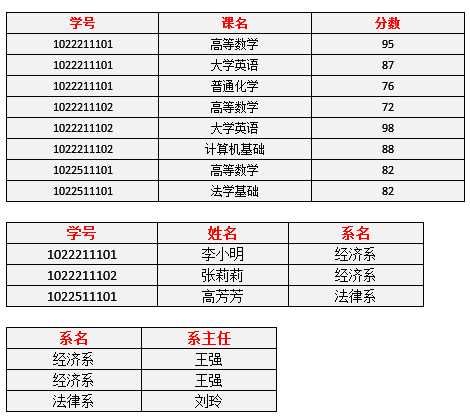
(4)3NF已解决的问题
问题1. 删除某个系中所有的学生记录——该系的信息不会丢失。——有改进
问题2. 插入一个尚无学生的新系的信息。——因为系表与学生表目前是独立的两张表,所以不影响。——有改进
问题3. 数据冗余更加少了。——有改进
(5)3NF仍存在的问题:3NF缺点示例1如下,
| 要求 | 关系分析 |
|---|---|
| 1. 某公司有若干个仓库。 | |
| 2. 每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作。 | 仓库名 → 管理员 管理员 → 仓库名 |
| 3. 一个仓库中可以存放多种物品,一种物品也可存放在不同仓库, 每种物品在每个仓库中都有对应的数量。 |
(仓库名,物品名)→ 数量 |
| 码:(管理员,物品名),(仓库名,物品名) 3NF设计数据表 |
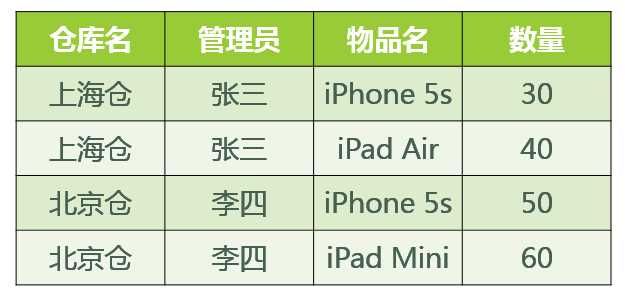 |
问题1. 先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。
问题2. 某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?——仓库本身与管理员的信息也被随之删除了。
问题3. 如果某仓库更换了管理员,会带来什么问题?——这个仓库有几条物品存放记录,就要修改多少次管理员信息。
(6)原因分析:存在着主属性对于码的部分函数依赖与传递函数依赖。(主属性【仓库名】对于码【(管理员,物品名)】的部分函数依赖。)
2.3.2 扩充的第三范式(BCNF)
(1)定义:如果关系模式R满足第一范式,“X能确定Y” 且 “Y不是X的子集”时 X必含有码,则该关系表满足BCNF。
(2)简单理解:要求每个决定因素都包含码,没有码就不能确定其他属性。
(3)举例说明:
| BCNF逻辑设计 |
|---|
| 仓库表(仓库名,管理员) |
| 库存表(仓库名,物品名,数量) |
(4)特点:
- 所有非主属性对每个码都是完全函数依赖;
- 所有主属性对每个不包含它的码也是完全函数依赖;
- 没有任何属性完全依赖于非码的任何一组属性。
2.4 第四范式(4NF)
(1)定义:在关系模式满足第一范式的情况下,消除了非平凡且非函数依赖的多值依赖。
3. 总结
(1)规范化范式设计的基本思想—— 逐步消除数据依赖中不合适的部分,使模式中的各关系模式达到某种程度的 “ 分离 ” 。
(2)让一个关系描述一个概念、实体或实体间的关系。
(3)多于一个概念就把它“分离”出去。
总结:因此,规范化设计实质上是概念上的单一化。
—————————————————————————————————————————————————
下图描述了规范化的过程: 
4. 范式设计需要注意的地方
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。
如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求 > 性能 > 表结构。所以不能一味地追求范式建立数据库。
5. 补充知识
5.1关系数据库模型
(1)关系(relation):一张表即是一个关系。
(2)元组(tuple):表中的一行即一个元组。
(3)属性(attribute):表中的一列即为一个属性,给属性起的名称即为属性名。
(4)码(key):指表中的某个属性组,它可以唯一确定一个元组。
(5)候选码(candidate key):候选码是能唯一地标志一个元组的属性组,且该属性组的子集不能。
5.1 候选码的诸属性称为主属性;
5.2 不在候选码中的属性称为非主属性。
(6)主码(primary key):若一个关系有多个候选码,则选择一个作为主码。
(7)域(domain):域是指一组具有相同数据类型的值的集合。
(8)分量:元组种的一个属性值。
(9)关系模型:是对关系的描述,关系名(属性1,属性2,…),如——学生(编号,学号,姓名,年龄,院系)。
(10)X完全函数依赖Y?指X能确定Y,且X的子集不能确定Y,即Y为候选码。
(11)X部分函数依赖Y?指X能确定Y,但Y不完全函数依赖于X,即X的子集也能确定Y。