Head_First_Python笔记
Head_First_Python
- 记录些啥
- 正文
- 0. 引子
- 1. 初识python:人人都爱列表
- 2. 共享你的代码:函数模块
- 3. 文件与异常:处理错误
- 4. 持久储存:数据保存到文件
- 5. 推导数据:处理数据
- 6. 定制数据对象:打包代码与数据
- 7.Web 开发:集成在一起
记录些啥
从小白开始学习Python。选择学习参考资料书的理念,要么独特,要么全面。对于记录些啥,我认为我应该会记录作者的一些独特思维、良好方法、优越的理念等,当然也会记录一些自己的理解与思考。另外,我希望记录的东西不太多,零星的一些提示点即可。所以,可能分为两个阶段,先把书读厚,再把书读薄。
原书可从链接下载Head First Python
其中本书的支持文件的下载见本书支持文件下载
正文
0. 引子
- 大脑就范
- 讲出来,大声讲出来。最好可以大声的解释给别人听。
- 要喝水,而且要喝大量的水。有充足的液体大脑就会有最佳的表现。
- 编写大量的软件!
1. 初识python:人人都爱列表
- Python 列表是个高级集合,列表不关心储存类型,它的存在只是为了提供一种储存机制,从而可以采用列表形式储存数据。
- for循环:用于处理列表和其他迭代结构
for循环与基础C不相同

目标标识符 标识符没有类型,但是标识符所指的数据对象有类型。 - 单双引号都可以用来创建字符串,没有区别。对此只有一个规则,如果字符串前面使用了某个引号(单引号或者双引号),那么后面的字符串也要使用同样的引号,不可混合使用。引号要统一可以用“\”或者‘ ’(单引号)引入一个想要表达的双引号
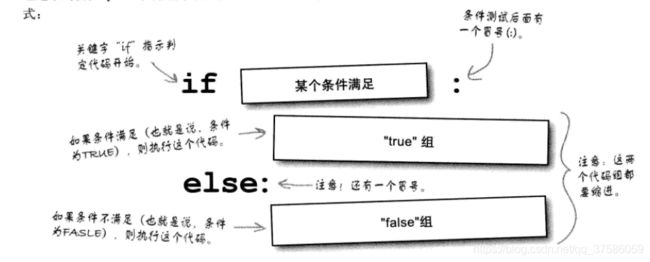
- if语句
- 解决重复代码-----------建立函数:得到代码的一般模式将其变为可重复使用的函数。
- 函数
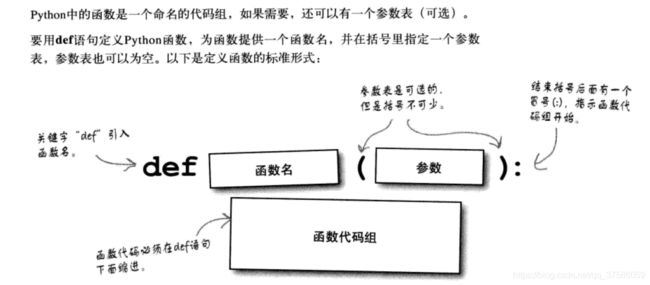
使用def来定制一个函数。
2. 共享你的代码:函数模块
- python包索引(Python Package Index , PyPI)相关学习见PyPI
进一步熟悉操作 - 注释代码 如果使用了一个三重引号,(’’’…’’’ 或""" …""")而没有将他赋值给一个变量,三重引号之间的所有内容都被认为是一个注释。
- python的模块实现命名空间
- 命名空间 import nester ------ nester
(模块名,识别命名空间).(隔开函数)print_lol()。 - 当然也可以直接improt函数 ----- from nester import print_lol。但是此方法相当于定义了一个print_lol函数。
- 以上两种import导入方式可根据个人喜好使用,
但是“from module import function”形式会搅乱你当前的命名空间,因为当前的命名空间中已经定义的名字会被导入的名字重写。
- 命名空间 import nester ------ nester
- 缺省值的使用意义
缺省值可以在升级函数版本时使用,当我们增加了函数的传递参数时为了更兼容之前的版本,我们利用参数名后面增加一个缺省值,这样就可以多种方式调用这个函数了。 - range()可以与for一起用从而迭代固定次数 for num in range(table_num) ----num目标函数 依次等于range(table_num)的数值
range()的用法- range(start, stop, step)
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1) - 实例
>>>range(10) # 从 0 开始到 10 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> range(1, 11) # 从 1 开始到 11 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> range(0, 30, 5) # 步长为 5 [0, 5, 10, 15, 20, 25] >>> range(0, 10, 3) # 步长为 3 [0, 3, 6, 9] >>> range(0, -10, -1) # 负数 [0, -1, -2, -3, -4, -5, -6, -7, -8, -9] >>> range(0) [] >>> range(1, 0) [] - print("\t", end=’’) 其中end=’'作为print()的一个参数,可以关闭默认行为(即输出包括自动换行)
3. 文件与异常:处理错误
- python中有两种类型的列表:一种是可以改变的列表(用中括号[list]包围),另一种是不可以改变的列表(用小括号(list)包围)。

- 对于文件这部分主要是首先学会如何导入文件数据 随后学会如何处理文件的数据。相关的一些内容见另一篇小的博客内容 python中导入及处理文件数据
- 对于数据内容出现的错误,本章最前面的部分主要采用了两种方式,第一种方式就是针对出现的问题不断的完善代码的逻辑。第二种方式主要是检测出现错误或者异常,捕捉到这个异常采取一定的措施从错误中恢复,避免代码的崩溃。
第二种方式的思路
在我看来第二种方式,仅仅关注自己管兴趣的部分进行处理,对于不关注或者不需要的部分进行筛选和处理 我们可以关注代码真正需要做些什么,不去操心那里可能出问题,并编写额外的代码来避免运行时候的错误
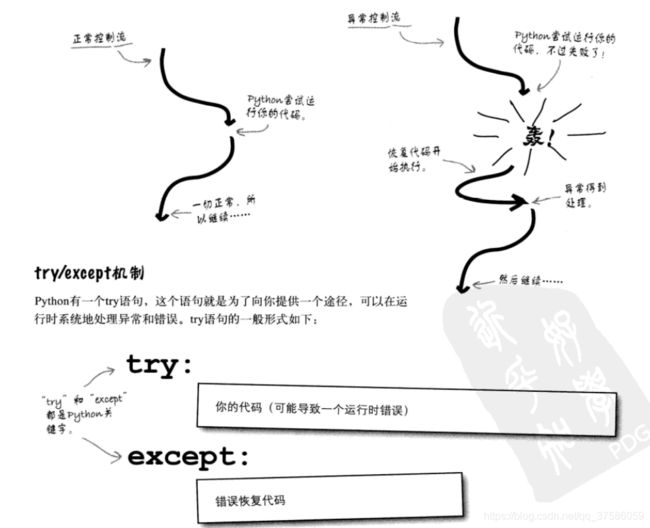
第二种方式利用**try except机制**
提供了一个异常处理机制,从而保护可能导致运行时错误的某些代码行。
try:
代码(可能导致运行时候的一个错误)重点确定这些想要保护的代码是那些 应该是错误出现的代码以及与之相关的不想执行的部分
except:
错误恢复代码 例如 pass
finally:
无论发生什么错误都必须执行的代码
try:
data = open('sketch.txt')
# data.seek(0)
for each_line in data:
try:
(speaker, line_spoken) = each_line.split(":", 1)
print(speaker, end='')
print(' said:', end='')
print(line_spoken, end='')
except ValueError:
pass
data.close()
# else:
# print('there is not the file')
except IOError:
print('there is not the file')
其中 except 后面的错误的类型标明(ValueError和IOError),制定了错误的类型,如果不是此类错误,则不进行下列的操作。
- pass语句就是python的空语句或者null语句
4. 持久储存:数据保存到文件
在使用访问模式w时,python会打开指定的文件进行写操作,
如果文件存在则清空现有内容
要追加到一个文件,需要使用访问模式a
要打开一个文件进行写或读不清除用“w+”
如果打开文件进行写操作,如果文件不存在,首先会自动创建文件,然后再打开文件写
try:
man_data_out = open("man_data", "w")
other_data_out = open("other_data", "w")
man_out = open("sketch.txt", "a")
man_add = open("sketch.txt", "w+")
print(man, file=man_data_out)
print(other, file=other_data_out)
print(man, file=man_out)
print(man, file=man_add)
except IOError:
print("the file is not closed")
finally:
man_data_out.close()
other_data_out.close()
man_out.close()
man_add.close()
- open默认是r形式
- man_data_out 是数据文件对象(以写的方式打开了文件夹,对这个对象操作就是对打开的文件夹的写操作。)
- man_data是所写入文件的文件名
- w要使用的访问模式
open()函数默认使用模式为r
- print默认把数据输出到屏幕上,要把文件写入到一个文件则需要file
- man 写入到文件的内容
- man_data_out缩写数据文件对象的名
- 完成工作一定要关闭文件
- 其中finally的作用是 无论出现什么错误都必须执行finally后面的代码。
- python中一旦创建了一个字符串,无论字符串调用什么改变函数(string.strip()),字符串都不会改变,只不过创建了一个新的字符串。如果 string = string.strip(),就将新创建的字符串重新赋值给了string
try:
with open('missing.txt', "w") as cover: #问号前可以有多个 ..as.. 逗号隔开
print("it is covering", file=cover)
except IOError as err:
print('File error:' + str(err))
- python 将异常对象作为一个参数传给except组 用 as将其赋值给一个变量。
locals()将反馈当前作用域中定义的所有名的一个集合。因为文件不存在所以missfile没有被定义。- with可以减少代码量。with能妥善管理关闭文件
- python函数用缺省值时,如果有多个参数有缺省值,但只有某一个参数的缺省值与我想要的不相同,我不必提供其他的参数,只需要写出这个参数和我提供的值即可。
例如:
print(value, sep=' ', end='\n', file=sys.stdout)
我可以只调用print(value, end='') - pickle “腌制”数据
什么作用呢?
实验一:用pickle
new_man = []
try:
with open("man_data.txt", "wb") as man_data_out:
pickle.dump(man, man_data_out)
except IOError as err:
print("Error:" + str(err))
except pickle.PickleError as pickleErr:
pickle("Error:" + str(pickleErr))
try:
with open("man_data.txt", "rb") as man_data_out:
new_man = pickle.load(man_data_out)
except IOError as err:
print("Error:" + str(err))
except pickle.PickleError as pickleErr:
pickle("Error:" + str(pickleErr))
print(new_man)
实验二:不用pickle
new_other = []
try:
with open("other_data.txt", "w") as other_data_out:
print(other, fh=other_data_out)
except IOError as err:
print("Error:" + str(err))
try:
with open("other_data.txt") as other_data_out:
for each_line in other_data_out:
new_other.append(each_line)
except IOError as err:
print("Error:" + str(err))
print(new_other)
- 标准库的 pickle 模块允许你容易而高效地将Python数据对象保存到磁盘以及从磁盘恢复
- 在上述例子中发现pickle函数并没有什么特殊的。
但是不用 pickle 的函数储存的封装协议和读取时解封装的协议要自己写。
其优点在于
而pickle内置了标准的封装形式。减少了封装和解封协议两个主要步骤。
5. 推导数据:处理数据
- 原地排序(In-Place sorting):
sort()--利用排序后的数据替换原来的数据。
[默认升序]如果想按降序排列则sort(reverse = Ture) - 复制排序(Copied sorting):
sorted()–排序后赋值给一个有序副本。
[默认升序]如果想按降序排列则sorted(reverse = Ture) - 方法串链:从左向右读
把多个方法串链在一起生成所需要的结果person = person_data.strip().split(",") - 函数串链:函数串链允许数据应用一系列函数。每个函数会取得数据,对他完成某个操作,然后把转化后的数据传递给下一个函数。与方法串链不同,他是从左向右读,函数串链要从右往左读。
append()- 语法:
list.append(obj) - 参数:
obj(添加到列表末尾的对象) - 返回值:没有返回值,只会修改原来的列表
如果强行赋值会显示AttributeError: 'NoneType' object has no attribute 'append' -
- 列表可包含任何数据类型的元素,单个列表中的元素无须全为同一类型。
append()方法向列表的尾部添加一个新的元素。- 列表是以类的形式实现的。“创建”列表实际上是将一个类实例化。因此,列表有多种方法可以操作。
extend()方法只接受一个列表作为参数,并将该参数的每个元素都添加到原有的列表中。
- 常见错误

- 语法:
- 列表迭代 列表推导
列表推导
列表迭代:正常for循环new_l = [len(t) for t in old_l]
如果必须对一个列表中的每一项完成一个转换,使用列表推导是上策,特别是如果能很容易地在一行上指定转换(或者指定一个函数链),列表推导尤其适用。列表迭代可以完成列表推导所能完成的全部工作,迭代需要的代码更多一些,不过如果需要,迭代确实能提供更大的灵活性。new_l =[] for t in old_l new_l.append(len(t)) - mutable 和 inmutable
james[0:3]
左闭右开set()函数是工厂函数可以创建一个集合。
6. 定制数据对象:打包代码与数据
Python提供了字典,允许你有效的组织数据,可以将数据与名关联而不是与数据关联,从而实现快速查找。并且Python class语句还允许定义自己的数据结构。
字典是一个内置的数据结构,允许将数据与键而不是与数字关联。这样可以使内存中的数据与实际数据的结构保持一致。
-
创建字典
classes = { }classes = dict()
-
定义一个类
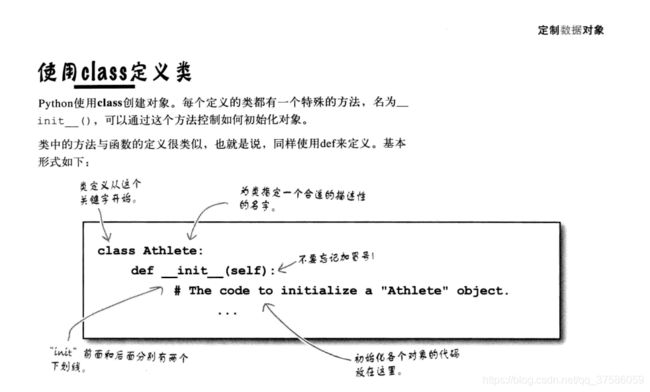
- 面向对象的世界里,代码通常称为类的方法,而数据通常称为类的属性,实例化的数据通常称为实例
- 类属性是指定义在类的内部而在方法外部的属性
- 对象属性是指定义在方法内部的属性。
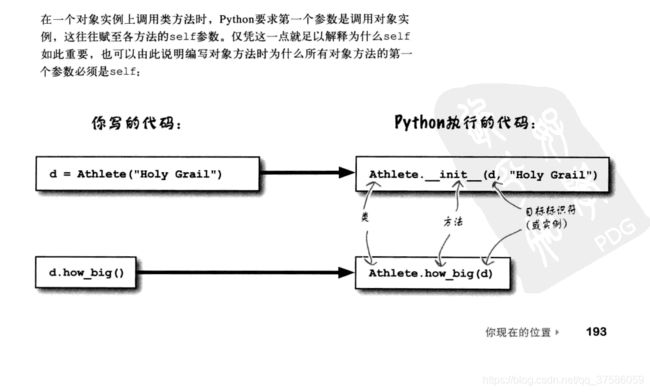
- 小结
- 字典----这是一个内置的数据结构,允许数据值与键关联。
- 键----字典中查找的部分
- 值----字典中的数据部分(可以是任意值,也包括另一种数据结构)
self----这是一个方法参数,总是指向当前对象实例
- Bullet Point
- 使用
dict()的工厂函数或使用{}可以创建一个空字典。 - 用
person['name']来访问person字典中与键Name关联的值 - 类似于列表和集合,字典会随着新数据增加到这个数据结构中而动态扩大。
- 可以先创建一个空字典
new_d = { }或new_d = dict()然后添加数据d['name'] = 'James'
也可以一次完成任务new_d = {'name' : 'James'} - 可以用
class定义一个类 - 类方法与函数定义基本相同要用
def关键字 - 类属性(数据)就像是对象实例中的变量
- 可以在类中定义__init__()方法来初始化对象实例
- 类中定义的每一个方法都必须提供
==self==作为第一参数 - 类中每个属性前面都必须有self将数据与其实例关联
- 类可以从零开始创建,也可以从内置类或者其他定制类继承。
- 使用
7.Web 开发:集成在一起
目的:分享自己的应用
- 好的Web应用应当遵循模型-视图-控制器模式,这样有助于Web应用的代码分解为易于管理的模块

- 面向对象的世界里,代码通常称为类的方法,而数据通常称为类的属性,实例化的数据通常称为实例