mysql数据库之查询语言(二)
前言
上一篇记录了mysql查询语句的一些简单条件限制,现在来对select查询语句进行后续补充,这篇写完后整个select单表查询语句也就基本记录完了。
1. 字段控制
1. distinct:实现去重
2. select 字段1+字段2 as 名字 from 表名:实现字段相加和字段命名,相加的字段必须是数据类型
3. ifnull(字段名,默认值):用于处理值为null的记录,如果字段名为null则将其值设置为默认值
4. order by 字段名1,字段名2,... asc/desc: 实现排序,默认为asc升序,desc为降序;优先以靠前的字段排序,依次递减。
现在来做一些小练习,数据如下:
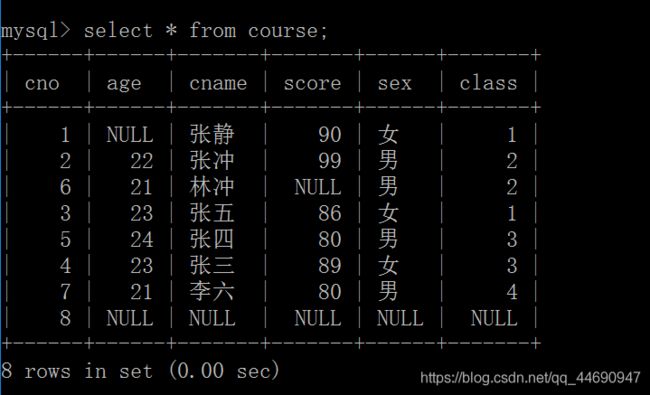
查询有多少个班级:select distinct class from course;

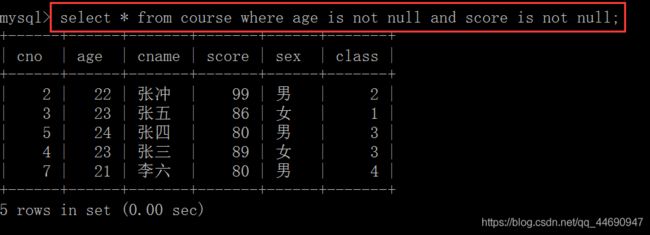
查询出年龄和分数不为空的学生信息:select * from course where age is not null and score is not null;
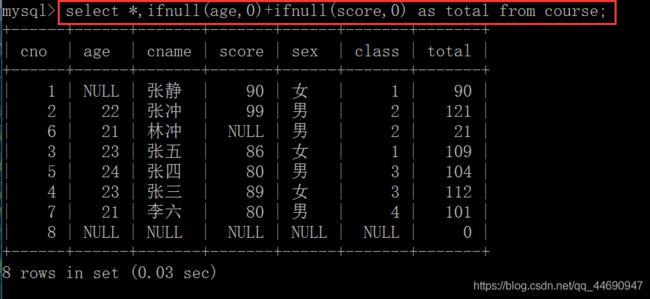
查询出所有学生的年龄和分数的和:select *,ifnull(age,0)+ifnull(score,0) as total from course;
查询出学生的信息,按分数排名显示:select * from course order by score desc;

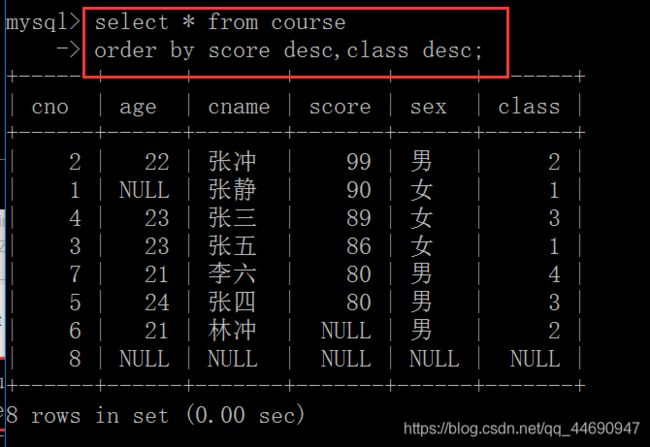
查询出学生的信息,结果按分数排名显示,分数相同的按班级排名:select * from course order by score desc,class desc;
2. 聚合函数
mysql中的聚合函数一般用来对数据进行统计,下面是常用的一些聚合函数
count():count(*)/count(1)统计包括空值在内的数据记录条数;count(字段名) 统计不包含空置在内的的记录
sum():求和
avg():求平均值
max():求最大值
min():求最小值
注意:
1.使用sum,avg,max,min时数据类型必须为数值型
2.以上不统计值为null的记录
查询出学生人数:select count(*) from course;/select count(cno) from course;/select count(1) from course;
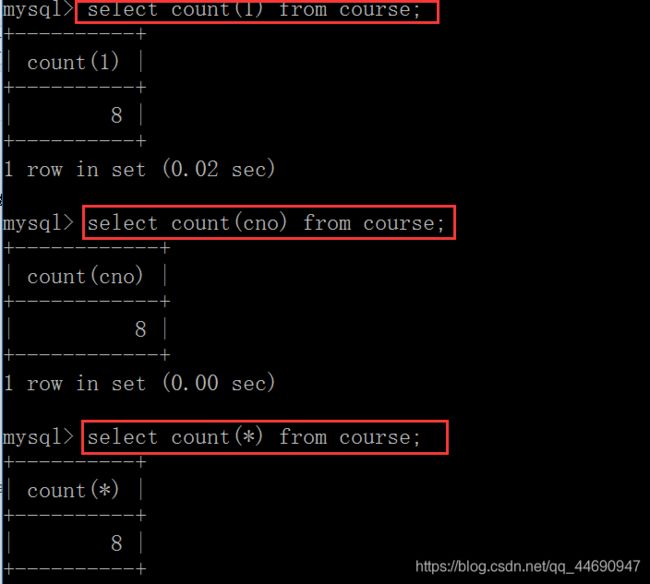
查询出平均分,最高分,最低分以及总分和:select avg(score),max(score),min(score),sum(score) from course;

3. 分组查询
分组查询就是把查询结果按字段值进行分组,相同的为一组,格式如下
select 字段名1,字段名2,... from 表名
group by 字段名1,字段名2...
比如,对班级进行分组:select class from course group by class;
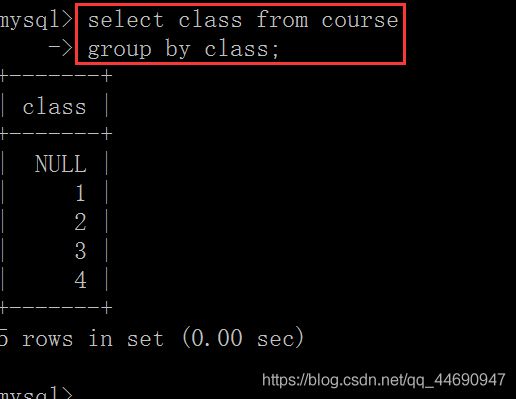
分组后可用group_concat(字段名)查看分组的值
group_concat(字段名):将字段的值以集合形式展示
比如上面对班级进行了分组,现在可以用group_concat(cname)查看学生对应所在的班级:select class,group_concat(cname) from course group by class;

4. having语句
having语句:用在分组查询后指定一些条件来输出查询结果,一般放在group by 语句后
group by 字段名 having 条件
比如上面查出的结果有class为空的记录,这时就可以用having语句来进一步筛选了:select class,group_concat from course group by class having class is not null;

having与where都可以加添加条件限制,那么他们有什么区别呢?如下
1. where是在分组前进行条件过滤,而having是在分组后再进行条件过滤
2. where后不能跟聚合函数,而having后则可以跟聚合函数
那么为什么where后面不能跟聚合函数呢?这得跟mysql查询语句的执行顺序有关了
因为where的执行顺序在聚合函数之前
5. 查询语句的书写顺序和执行顺序
书写顺序
select 查询字段
from 表名
where 条件
group by 字段名
having 条件
order by 字段名
limit 参数1,参数2
这里对limit语句进行一下补充,limit的作用是可以指定从哪一行开始查,要查多少行
格式:limit 参数1,参数2
说明:参数1为开始行,参数2为数据条数
比如只查询前3条数据信息:select * from course limit 0,3
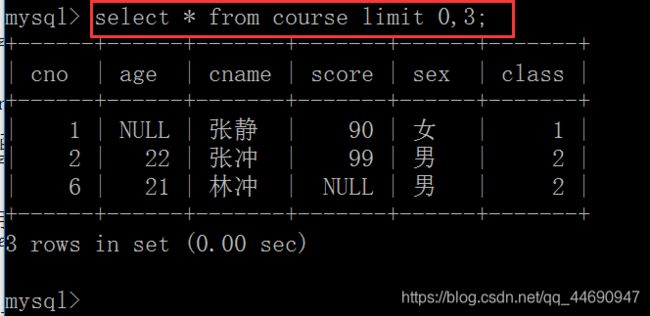
执行顺序
from->where->group by->having->select->order by->limit