神经网络BP算法简单推导
这几天围绕论文A Neural Probability Language Model 看了一些周边资料,如神经网络、梯度下降算法,然后顺便又延伸温习了一下线性代数、概率论以及求导。总的来说,学到不少知识。下面是一些笔记概要。
一、 神经网络
神经网络我之前听过无数次,但是没有正儿八经研究过。形象一点来说,神经网络就是人们模仿生物神经元去搭建的一个系统。人们创建它也是为了能解决一些其他方法难以解决的问题。
对于单一的神经元而言,当生物刺激强度达到一定程度,其就会被激发,然后做出一系列的反应。模仿这个过程,就有了下面这张图:


其中X可以看作是一系列的刺激因素,而W可以看作各个刺激因素所对应的权值。计算各个刺激因素的加权和就可以作为我们总的刺激强度了。注意一下,上图中的X0和Wk0代表了随机噪声。得到中的刺激强度之后我们就可以根据这个强度做出一定的反应,这个过程交由图中的Activation function函数来处理,处理后就获得了我们最终的结果。
一般而言,Activation function函数可以有三种(下图中的a和b可以看做一种):

至此,神经网络的最基本结构——单层神经网络,已经介绍的差不多了。对于神经网络而言,我们可以利用这样的简单的单层神经网络去组合搭建一个复杂的神经网络,以实现不同的功能。它可以是这样的(接受一下参数表示的不同):
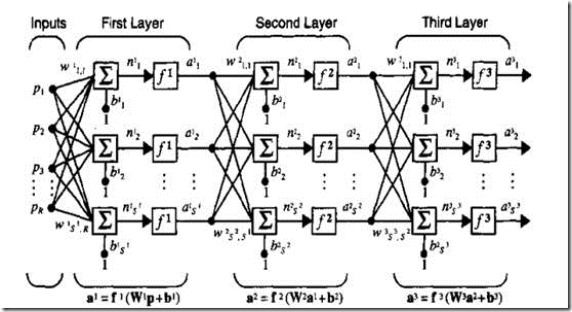
将这个图中的变量以向量的形式表示可以得到下图:

除了这种相对简单的多层神经网络,网络还可以是这样的:

这一部分的资料可以参见:An introduction to neural networks :IBM做的一个科普资料Introduction to Neural Networks :这个页面相对更加的规范以及hagan教授的书籍:Neural_Network_Design
二、 梯度下降法
这个方法呢,说起来很简单。一个很形象的比喻就是说,你站在山坡上想下山,那么如何才能尽快下山(默认速度是恒定的,你也不会摔死)?
你应该会环顾四周,找到当前最陡峭的方向下山吧?这个方向就可以用梯度来计算,这也就是梯度下降法的来源。是不是觉得很简单,以为自己掌握了?哈哈,还是太年轻了。
这一部分就不赘述了,给出我学习时候用到的两个资料:
NG教授的机器学习课程中的第二课(话说,听完了,我就会了,之前可是看了一大堆资料还是似懂非懂);
机器学习中的数学这个博客也很不错,看完课程再来看看这个还是有点好处的。
对了,梯度下降法还有一个变种:随机梯度下降法。这个才是很多场合下真正使用的方法。
三、 梯度下降法和神经网络的结合
好了,上面分别介绍完了梯度下降法以及神经网络,下面就是它们的结合应用了。
我们需要利用样本数据去训练我们的神经网络模型(其实很大程度上就是修改神经网络里面的参数,如上面看到的权值等等),那么怎么修改呢?我们当时是应该对照我们的目标去做修改,这往往意味着要去最值化一些量,提到最值,是不是跟梯度下降法搭上勾勾了啊。我们可以利用梯度下降法做多轮迭代一步步逼近我们最终的目标。这也就是它们结合的地方。哦,听说所谓的深度学习也就基本上是这个思路了。瞬间感觉高大上有没有??
注意一下,这部分需要用了很多线性代数以及导数的很多知识,自行脑补。我是参考了NG教授机器学习这门课的讲义以及 Neural_Network_Design 这本书中的相关内容。
一个简单例子:房子价格
自行学习NG教授机器学习这门课的第二课,讲的很好!
下面的是一个复杂一点的例子。
我们把多层神经网络分为三层,输入层、输出层以及中间的隐藏层,对于中间隐藏层我们没有办法直接去计算梯度,进而修改参数。于是乎就只能利用求导的链式规则,从输出层开始往回计算梯度,从而得以更新参数。这也就是传说中的BP神经网络了,我的学习资料是:hagan教授的书籍:Neural_Network_Design。其中有一章节专门将BP神经网络,讲的很好。推导过程稍微有点长,我看完后不知所以,自己又找时间不看书推到了一遍,挺有意思的,哈哈。
看完后可以再参考这篇文章:Backpropagation。加深自己的理解。
四、 A Neural Probability Language Model
有了上面的基础知识,再看这篇文章就容易多了。这篇文章的地位很高,文章主要亮点在于:首先,利用词向量去表示一个词从而可以获知不同词语之间的相似度;其次,搭建神经网络去做计算(BP神经网络加上梯度下降法);其三,并行化去做计算,从而可以处理大规模的数据;最后也是最亮的地方在于该方法的实验结果非常理想!
这篇博客也有提到:Deep Learning in NLP (一)词向量和语言模型
自己感觉对于这篇文章有些细节问题还是没有理解,比如网络的输入是怎么来的?
转自:http://f.dataguru.cn/thread-673418-1-1.html