在之前的三篇文章中,我尝试了使用python爬虫实现的对于特定站点的《剑来》小说的爬取,对于豆瓣的短评的爬取,也有对于爬取的短评数据进行的词云展示,期间运用了不少的知识,现在是时间回顾一下。在此之后,我会再关注一些爬虫框架的使用,以及更多的爬虫的优化方法,争取做到尽量多的吸收新知识,巩固旧知识。
在参考文章爬虫(1)--- Python网络爬虫二三事的基础上,我写了这篇文章。
这篇文章主要的目的有两个,收集新知识,巩固旧知识。
关于爬虫背后的(这一节是主要是http的概要,下一节是我的一些总结)
要想不限于代码表面,深入理解爬虫,就得需要了解一些关于网络的知识。
HTTP 协议
HTTP(Hypertext Transfer Protocol)是应用级协议,它适应了分布式超媒体协作系统对灵活性及速度的要求。它是一个一般的、无状态的、基于对象的协议。
可以参考的文章:
想要细致了解协议的可以查看:
- 中文 HTTP/1.0 RFC文档目录
- 深入理解HTTP协议(转)
- HTTP协议详解(真的很经典)
- HTTP请求方法大全 & HTTP请求头大全 & HTTP状态码大全 & HTTP Content-type 对照表
一些术语
- 请求(request):HTTP的请求消息
- 响应(response):HTTP的回应消息
- 资源(resource):网络上可以用URI来标识的数据对象或服务。URI有许多名字,如WWW地址、通用文件标识(Universal Document Identifiers)、通用资源标识(Universal Resource Identifiers),以及最终的统一资源定位符(Uniform Resource Locators (URL))和统一资源名(URN)。
- 实体(entity):可被附在请求或回应消息中的特殊的表示法、数据资源的表示、服务资源的回应等,由实体标题(entity header)或实体主体(entity body)内容形式存在的元信息组成。
- 客户端(client):指以发出请求为目的而建立连接的应用程序。
- 用户代理(user agent):指初始化请求的客户端,如浏览器、编辑器、蜘蛛(web爬行机器人)或其它终端用户工具。用户代理请求标题域包含用户原始请求的信息,这可用于统计方面的用途。通过跟踪协议冲突、自动识别用户代理以避免特殊用户代理的局限性,从而做到更好的回应。虽然没有规定,用户代理应当在请求中包括此域。
- 服务器(server):指接受连接,并通过发送回应来响应服务请求的应用程序。
- 代理(proxy):同时扮演服务器及客户端角色的中间程序,用来为其它客户产生请求。请求经过变换,被传递到最终的目的服务器,在代理程序内部,请求或被处理,或被传递。代理必须在消息转发前对消息进行解释,而且如有必要还得重写消息。代理通常被用作经过防火墙的客户端出口,用以辅助处理用户代理所没实现的请求。

任何指定的程序都有能力同时做为客户端和服务器。我们在使用这个概念时,不是看程序功能上是否能实现客户及服务器,而是看程序在特定连接时段上扮演何种角色(客户或服务器)。同样,任何服务器可以扮演原始服务器、代理、网关、隧道等角色,行为的切换取决于每次请求的内容。
简单流程
HTTP协议是基于请求/回应机制的。客户端与服务器端建立连接后,以请求方法、URI、协议版本等方式向服务器端发出请求,该请求可跟随包含请求修饰符、客户信息、及可能的请求体(body)内容的MIME类型消息。服务器端通过状态队列(status line)来回应,内容包括消息的协议版本、成功或错误代码,也跟随着包含服务器信息、实体元信息及实体内容的MIME类型消息。
绝大多数HTTP通讯由用户代理进行初始化,并通过它来组装请求以获取存储在一些原始服务器上的资源。
一次HTTP操作称为一个事务,综上,其工作过程可分为四步:
- 首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
- 建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
- 服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
- 客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
HTTP 消息(HTTP Message)
HTTP消息由客户端到服务器的请求和由服务器到客户端的回应组成。
HTTP-message = Simple-Request ; HTTP/0.9 messages
| Simple-Response
| Full-Request ; HTTP/1.0 messages
| Full-Response
完整的请求(Full-Request)和完整的回应(Full-Response)都使用RFC822中实体传输部分规定的消息格式。两者的消息都可能包括标题域(headers,可选)、实体主体(entity body)。实体主体与标题间通过空行来分隔(即CRLF前没有内容的行)。
Full-Request = Request-Line
*( General-Header
| Request-Header
| Entity-Header )
CRLF
[ Entity-Body ]
Full-Response = Status-Line
*( General-Header
| Response-Header
| Entity-Header )
CRLF
[ Entity-Body ] (想要了解更多,可以前往中文 HTTP/1.0 RFC文档目录 )
代码实现的流程
从我之前的代码中可以从一些方法中看出,我们利用urllib库,实际上完成了请求,并接受了响应。通过我们自己构造(例如添加headers)或者使用默认的请求信息,利用了urllib库的request模块的Request()方法构造请求,利用urlopen()方法接受响应返回的页面代码。
至于我们的爬虫工作的过程,在这里盗用(http://www.jianshu.com/p/0bfd...)一张图片:
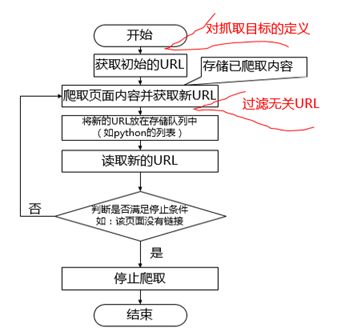
爬虫是一个综合性的工具
在实现爬虫的过程中,为了实现我们的目的,我们借助了各种各样的工具。浏览器的开发者工具,正则表达式,以及python的各种功能库。可谓是无所不用其极。但是,对于这些工具,我们实际上用到的功能,目前来看,其实并不多,核心代码就是那点而已,所以说,抽离出汇总起来,日后重新使用,一旦对于这个工具不再熟悉,回过头来看这些小小的片段,总是会省下很多的时间。
所以,这篇文章的核心内容就要来了。
获取URL
这里可以借助浏览器的产看网页源代码,查看元素等开发者工具,且快捷键一般是F12。
获取页面及异常处理
常用的是利用urllib库。在python3中,没有了原来2中的urllib2,而是用urllib包含了。
主要是用urllib.request.Request()&urllib.request.urlopen()
urllib.request
urllib is a package that collects several modules for working with URLs:
urllib.request for opening and reading URLs urllib.error containing the exceptions raised by urllib.request urllib.parse for parsing URLs urllib.robotparser for parsing robots.txt files
import urllib.request
import urllib.error
import traceback
import sys
url = "..."
try:
request = urllib.request.Request(url)
html = urllib.request.urlopen(request).read().decode("")# 按情况解码
print(html)
except urllib.error.URLError as error_1:
if hasattr(error_1,"code"):
print("URLError异常代码:")
print(error_1.code)
if hasattr(error_1,"reason"):
print("URLError异常原因:")
print(error_1.reason)
except urllib.error.HTTPError as error_2:
print("HTTPError异常概要:")
print(error_2)
except Exception as error_3:
print("异常概要:")
print(error_3)
print("---------------------------")
errorInfo = sys.exc_info()
print("异常类型:"+str(errorInfo[0]))
print("异常信息或参数:"+str(errorInfo[1]))
print("调用栈信息的对象:"+str(errorInfo[2]))
print("已从堆栈中“辗转开解”的函数有关的信息:"+str(traceback.print_exc()))
作者:whenif
链接:http://www.jianshu.com/p/0bfd0c48457f
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。URLError
通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。HTTPError
首先我们要明白服务器上每一个HTTP 应答对象response都包含一个数字“状态码”,该状态码表示HTTP协议所返回的响应的状态,这就是HTTPError。比如当产生“404 Not Found”的时候,便表示“没有找到对应页面”,可能是输错了URL地址,也可能IP被该网站屏蔽了,这时便要使用代理IP进行爬取数据。两者关系
两者是父类与子类的关系,即 HTTPError是URLError的子类,HTTPError有异常状态码与异常原因,URLError没有异常状态码。所以,我们在处理的时候,不能使用URLError直接代替HTTPError。同时,Python中所有异常都是基类Exception的成员,所有异常都从此基类继承,而且都在exceptions模块中定义。如果要代替,必须要判断是否有状态码属性。
异常处理有还有else&finally可以选择。
伪装浏览器
添加头信息。可以在浏览器的开发者工具中的网路选项卡中点击对应的html页面查看请求报文和相应报文信息。一般的,只需添加用户代理信息即可。
import urllib.request
url = 'http://www.baidu.com'
# 构造方法1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'}
request = urllib.request.Request(url, headers = headers)
data = urllib.request.urlopen(request).read().decode('utf-8')
# 构造方法2
headers=("User-Agent", "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36")
opener = urllib.request.build_opener()
opener.addheaders = [headers]
# # 打开方法1
data = opener.open(url, timeout=3).read().decode('utf-8')
# 打开方法2
urllib.request.install_opener(opener)
data = urllib.request.urlopen(url).read().decode('utf-8')
print(data)class urllib.request.Request(url[, data][, headers][, origin_req_host][, unverifiable])data 数据可以是指定要发送到服务器的附加数据的字符串,如果不需要这样的数据,则为None。目前HTTP请求是唯一使用数据的请求; 当提供数据参数时,HTTP请求将是POST而不是GET。 数据应该是标准的 application/x-www-form-urlencoded 格式。urllib.parse.urlencode()函数采用映射或2元组的序列,并以此格式返回一个字符串。
headers 应该是一个字典,并且将被视为使用每个键和值作为参数调用 add_header()。 这通常用于“欺骗”用户代理头,浏览器使用它来识别自己 - 一些HTTP服务器只允许来自普通浏览器的请求而不是脚本。
时间问题
超时重连
有时候网页请求太过频繁,会出现长时间没有响应的状态,这时候一般需要设置超时重连。下面是一个例子片段
import urllib.request
import socket
url = "..."
NET_STATUS = False
while not NET_STATUS:
try:
response = urllib.request.urlopen(url, data=None, timeout=3)
html = response.read().decode('GBK')
print('NET_STATUS is good')
return html
except socket.timeout:
print('NET_STATUS is not good')
NET_STATUS = False
# 也可以直接设置全局超时进行捕获,用的还是`socket.timeout`异常
import socket
timeout = 3
socket.setdefaulttimeout(timeout)线程延迟
线程推迟(单位为秒),避免请求太快。
import time
time.sleep(3)页面解析
目前掌握的方法是使用正则表达式和bs库。当然,之后会了解下XPath,这个也提供了一种搜索的思路。
正则匹配
这个用的函数并不多。有两种书写方式,面向对象和
import re
pattern = re.compile('[a-zA-Z]')
result_list = pattern.findall('as3SiOPdj#@23awe')
print(result_list)
# re.search 扫描整个字符串并返回第一个成功的匹配。
searchObj = re.search( r'(.*) are (.*?) .*', "Cats are smarter than dogs", re.M|re.I)
print(searchObj.group())# Cats are smarter than dogs
print(searchObj.group(1))# Cats
print(searchObj.groups())# ('Cats', 'smarter')python3正则表达式
beautifulsoup4
Python利用Beautiful Soup模块搜索内容详解
我个人感觉,这个库的使用,主要难点在于搜索时的麻烦。我觉得比较好用的是方法find()&find_all()&select()。
使用 find() 方法会从搜索结果中返回第一个匹配的内容,而 find_all() 方法则会返回所有匹配的项,返回列表。
select()中可以使用CSS选择器。很方便可以参考浏览器开发者工具。
from bs4 import BeautifulSoup
# 可以获取验证码图片地址并下载图片
soup = BeautifulSoup(response_login, "html.parser")
captchaAddr = soup.find('img', id='captcha_image')['src']
request.urlretrieve(captchaAddr, "captcha.jpg")
...
totalnum = soup.select("div.mod-hd h2 span a")[0].get_text()[3:-2]文件读写
# 要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数
with open(filename, 'w+') as open_file:
...
# 遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略
with open(filename, 'r', encoding='gbk', errors='ignore') as open_file:
all_the_text = open_file.read([size])
list_of_all_the_lines = open_file.readlines()
open_file.write(all_the_text)
open_file.writelines(list_of_text_strings)登录信息
我们构造好 POST 请求,这一旦发送过去, 就登陆上了服务器, 服务器就会发给我们 Cookies。继续保持登录状态时,就需要借助相关的库的方式,可以简化处理。
Cookies 是某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密)。
from urllib import request
from urllib import parse
from http import cookiejar
main_url = '...'
formdata = {
# 看网站post页面需求
"form_email":"你的邮箱",
"form_password":"你的密码",
"source":"movie",
"redir":"https://movie.douban.com/subject/26934346/",
"login":"登录"
}
user_agent = 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
headers = {'User-Agnet': user_agent, 'Connection': 'keep-alive'}
cookie = cookiejar.CookieJar()
cookie_support = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(cookie_support)
data = parse.urlencode(formdata).encode('utf-8')
req_ligin = request.Request(url=main_url, data=data, headers=headers)
html = opener.open(req_ligin).read().decode('utf-8')
print(html)代理
有一种反爬虫策略就是对IP进行封锁。所以我们有时需要设置代理。
原理:代理服务器原理如下图,利用代理服务器可以很好处理IP限制问题。
一般都是利用互联网上提供的一些免费代理IP进行爬取,而这些免费IP的质量残次不齐,出错是在所难免的,所以在使用之前我们要对其进行有效性测试。另外,对开源IP池有兴趣的同学可以学习Github上的开源项目:IPProxyPool。
import urllib.request
def use_proxy(url,proxy_addr,iHeaders,timeoutSec):
'''
功能:伪装成浏览器并使用代理IP防屏蔽
@url:目标URL
@proxy_addr:代理IP地址
@iHeaders:浏览器头信息
@timeoutSec:超时设置(单位:秒)
'''
proxy = urllib.request.ProxyHandler({"http":proxy_addr})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
try:
req = urllib.request.Request(url,headers = iHeaders) #伪装为浏览器并封装request
data = urllib.request.urlopen(req).read().decode("utf-8","ignore")
except Exception as er:
print("爬取时发生错误,具体如下:")
print(er)
return data
url = "http://www.baidu.com"
proxy_addr = "125.94.0.253:8080"
iHeaders = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0"}
timeoutSec = 10
data = use_proxy(url,proxy_addr,iHeaders,timeoutSec)
print(len(data))
作者:whenif
链接:http://www.jianshu.com/p/0bfd0c48457f
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。后续
后面我会在考虑学习多线程异或多进程改写之前的爬虫,研究研究前面引用的文章里的提到的一些我之前还未了解的技术,感觉要学的东西还是很多,快要开学了,自己的效率有点低,也不知道还能有多少时间给自己这样浪。