Spring Boot 2.x 事务处理(一篇长文让你读懂什么是隔离级别和传播行为)
写在前面
在互联网发达的时代里,对于那些电商和金融网站,最关注的的内容毫无疑问就是数据库事务,因为对于热门商品的交易和库存以及金融产品的金额,是绝对不允许发生错误的。面对这样的高并发场景,掌握数据库事务机制是至关重要的,它能够帮助我们在一定的程度上保证数据的一致性,并且有效提高系统性能,避免系统产生宕机。下面我们聊一聊SpringBoot2.x的事务处理机制。
这篇文章是博主参考《深入浅出SpringBoot2.x》这本书写的,有很多的心得体会,文字性的理论较多,但是大家耐心看完,就一定会有所收获,话不多说,正文开始。
需要了解的知识点总结:
- JDBC的数据库事务
- Spring声明式数据库事务约定及@Transactional注解的使用
- 隔离级别
- 传播行为
①、JDBC的数据库事务
我们先配置数据库信息
spring:
datasource:
url: jdbc:mysql://localhost:3306/chapter3?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8
password: ***
username: ***
driver-class-name: com.mysql.jdbc.Driver
platform: mysql
# 下面为连接池的补充设置,应用到上面所有数据源中
# 初始化大小,最小,最大
initialSize: 1
minIdle: 3
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 30000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,slf4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
#useGlobalDataSourceStat: true
在spring数据库事务中可以使用编程式事务,也可以使用声明式事务。编程式事务这种比较底层的方式已经基本被淘汰了,SpringBoot也不推荐我们使用,因此在这里不再讨论编程式事务。
为了让大家有更直观的感受,我们先看一段代码,JDBC的事务处理。
public class JdbcService {
@Autowired
private DataSource dataSource;
public int insertUser(String userName,String note){
Connection conn =null;
int result = 0;
try {
//获取连接
conn = dataSource.getConnection();
//开启事务
conn.setAutoCommit(false);
//设置隔离级别
conn.setTransactionIsolation(Connection.TRANSACTION_READ_COMMITTED);
//执行sql
PreparedStatement ps = conn.prepareStatement("insert into t_user value(null,?,?)");
ps.setString(1,userName);
ps.setString(2,note);
//提交事务
conn.commit();
} catch (Exception e) {
//回滚事务
if(conn!=null){
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
e.printStackTrace();
}finally {
//关闭数据库连接
try {
if(conn!=null&&conn.isClosed()){
conn.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
return result;
}
}
//执行sql
PreparedStatement ps = conn.prepareStatement(“insert into t_user value(null,?,?)”);
ps.setString(1,userName);
ps.setString(2,note);
在这段代码中,业务代码只有执行sql的三行,其他都是JDBC的配置功能代码,我们看到了又要获取连接,又要关闭,又要提交,又要回滚,还得写大量的 踹、开吃,看着就让人头大,极大的挑战我们阅读代码的能力,而你要知道这仅仅只有一条sql,如果多条sql,代码就完全难以控制了。
于是人们不管的优化,使用持久层框架Mybatis、Hibernate等都可以减少代码,但是还是不够方便,于是 AOP 出现了,简直就是我们的福音。
AOP允许我们通过面向切面编程的方式将公共代码抽出来,单独实现,为了更好的理解,请看图:
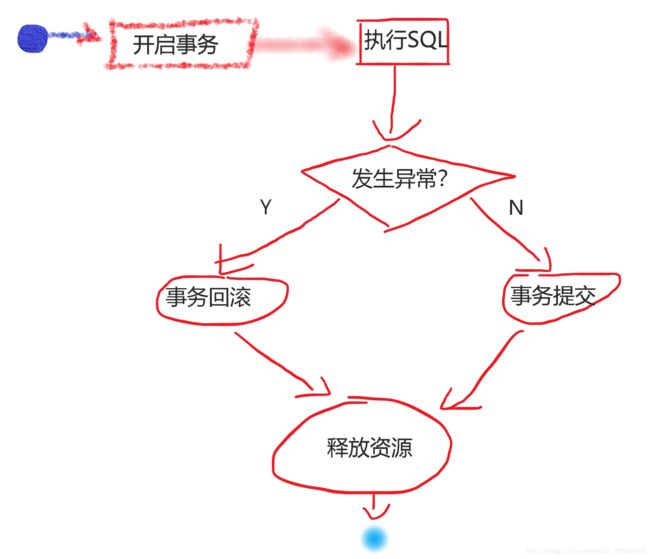
美术细胞实在有限大家凑合看。。。
这个流程与我们AOP约定流程十分接近,而在图中,有业务逻辑的部分也只是执行SQL那一段,其他都是比较固定的,按照AOP的设计思想,就可以把除了执行SQL的其他步骤全部抽取出来单独实现,这便是Spring数据库事务编程的思想。
②、Spring声明式数据库事务约定及@Transactional注解的使用
对于事务,需要通过标注告诉spring在什么地方启动数据库事务功能。对于声明式事务,使用@Transactional进行标注的。这里让我想起一段广告词
“啊呀,妈妈再也不用担心我的学习,某某高点读机哪里不会点哪里。”
确实是这样,Spring提供的@Transactional,只需要加在代码上就可以,这个注解可以加在类上也可以加在方法上。加到哪里,哪里就会被spring自动接管进行事务控制。
- 加在类上:代表这个类所有的公共(public)非静态的方法都将启动事务功能。
- 加在方法上:代表当前方法将启动事务功能。
当然,在@Transactional注解中,还允许配置许多的属性,如发生异常是否回滚啊、如事务的隔离级别和传播行为啊,后文会有讲解。
划重点:
事务拦截器会对我们标记的方法进行拦截,如果没有异常就会帮我们提交,如果发生异常,则是会判断我们事务定义的配置,如果实现我们约定好了某某类型的异常不回滚,那么还是会帮我们提交事务。哦对了,如果你懒得配置,@Transactional的默认配置是发生异常就回滚,将异常抛出,这一步也是由事务拦截器完成的。
下面我们看一段代码吧,跟上面的JDBC事务管理比一下:
public class UserService {
@Autowired
private UserDao userDao;
@Transactional
public int insertUser(User user){
return userDao.insertUser(user);
}
}
这里仅仅用了一个注解,就解决了前面大量的代码,把insertUser方法织入约定的编程中,所有连接、关闭、提交、回滚等都不需要手写,可见这是十分便利的。从代码中我们只需要完成对业务的逻辑编辑就可以了,提高了代码的可读性和可维护性。
下面介绍@Transactional属性的配置:
- timeout 属性
事务的超时时间,默认值为-1。如果超过该时间限制但事务还没有完成,则自动回滚事务。
- readOnly 属性
指定事务是否为只读事务,默认值为 false;为了忽略那些不需要事务的方法,比如读取数据,可以设置 read-only 为 true。
- rollbackFor 属性
用于指定能够触发事务回滚的异常类型,可以指定多个异常类型。
- noRollbackFor 属性
抛出指定的异常类型,不回滚事务,也可以指定多个异常类型。
- isolation 属性
事务的隔离级别,默认值为 Isolation.DEFAULT。
可选的值有:
Isolation.DEFAULT //使用底层数据库默认的隔离级别。
Isolation.READ_UNCOMMITTED //未提交读隔离级别
Isolation.READ_COMMITTED //读写提交隔离级别
Isolation.REPEATABLE_READ//可重复读隔离级别
Isolation.SERIALIZABLE //串行化隔离级别
- propagation 属性
事务的传播行为,默认值为 Propagation.REQUIRED。
可选的值有:
Propagation.REQUIRED
如果当前存在事务,则加入该事务,如果当前不存在事务,则创建一个新的事务。
Propagation.SUPPORTS
如果当前存在事务,则加入该事务;如果当前不存在事务,则以非事务的方式继续运行。
Propagation.MANDATORY
如果当前存在事务,则加入该事务;如果当前不存在事务,则抛出异常。
Propagation.REQUIRES_NEW
重新创建一个新的事务,如果当前存在事务,暂停当前的事务。
Propagation.NOT_SUPPORTED
以非事务的方式运行,如果当前存在事务,暂停当前的事务。
Propagation.NEVER
以非事务的方式运行,如果当前存在事务,则抛出异常。
Propagation.NESTED
在批量任务执行单独任务时,如果当前任务出现异常,回滚当前任务的SQL,不回滚批量任务的SQL
这些概念性的东西可以截个图,留作备用,后文会有详细讲解。
③、隔离级别
上面介绍了事务简单的使用,下面两个是重头戏,大家理解了这两个的概念以及用法,事务控制就差不多了。
由于隔离级别是个比较难理解的东西,我们先从数据库事务的知识入手:
数据库事务具有4个基本特性,也就是著名的ACID:
-
Atomic (原子性) :
事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行 -
Consistency(一致性):
事务在完成时,必须所有的数据都保持一致,保证数据完整 -
Isolation(隔离性):
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离 -
Durability(持久性):
事务结束后,所有的数据会固化到一个地方,比如保存到磁盘,即使断点重启也能找到数据
除了隔离性,其他的还算比较好理解,那么怎么保证我们的数据隔离呢,下面讲解了隔离级别。
详解隔离级别:
四种隔离级别由低到高依次是:
- 未提交读
- 读写提交
- 可重复读
- 串行化
1.未提交读:
它是最低的隔离级别,含义是允许一个事务读取另一个事务没有提交的数据。

前前后后就违反了一致性的原则,出现了脏读,未提交读是一种危险的隔离级别,所以在开发场景我们一般不用,但是他的优点在于并发高。
2.读写提交:
是指一个事务只能读取已经提交的数据,读取不到未提交的数据。
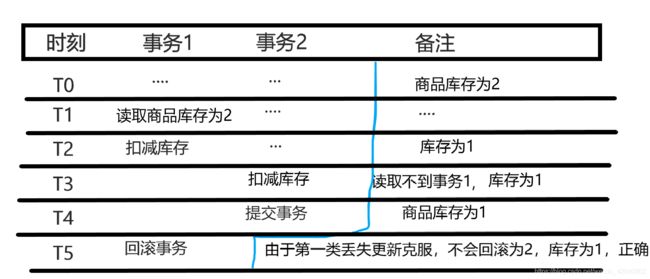
这就解决了脏读的问题,那么这么做有什么缺点呢,上图稍微一变,就出现了不可重复读的场景:
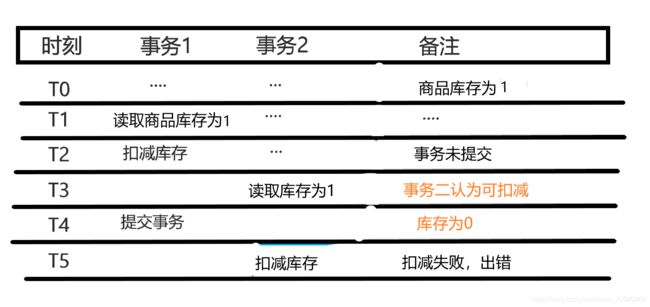
这里的问题在于事务2之前还认为库存可以扣减,过一会事务1提交了,实际库存为0,而事务2不知道啊,接着扣减,发现完犊子了,扣减不了了,出错了。这就是不可重复读,而应对这个问题,数据库的隔离级别又提出了可重复读。
3.可重复读:
在读写提交的时候,经常会发生一些值得变化,影响其他事务的执行,可重复读就是在读写提交的思想上提出了尝试的概念。看图 ↓

一波未平一波又起啊,又有新难题出现了,俗称幻读:
通俗理解,幻读就是读的跟操作的数据不一致,就像出现幻觉一样:
如图:

这边是幻读,是不是被搞到头晕了,这也不行那也不行,到底应该怎么办,其实写程序就像人生一样,再完美的人也会有缺陷,摆正位置找准角度,就能对症下药,解决问题。掌握了概念,在运用中不断探索不断学习,就一定会掌握好的。最后说一种,最高级别的隔离,串行化。
4.串行化:
这个没图,也超级好理解,就是要求所有的SQL都按照顺序排队执行,保证数据的一致性。
合理利用隔离级别:
通过上面的讲述,大家应该也有一定的了解,总结一下,每个隔离级别出现的问题吧:
未提交读:最低级别,什么问题都会出现,脏读啊,幻读啊,不可重复读啊。
读写提交:稍微高一点,少一个问题,会出现不可重复读和幻读。
可重复读:再高一点,只会出现幻读。
串行化:什么问题都没有。
说的比较通俗,但是在开发高并发业务的时候需要时刻谨记隔离级别可能发生的问题,
追求更高的隔离级别,虽然能保护好数据的一致性,但是它慢啊,性能差啊,付出了锁的代价啊,所以开发得时候不能只考虑数据一致性,还得考虑性能。
使用隔离级别:

直接这么用就可以啦,具体代表着什么,我在上面已经介绍过了,可以返回看看,瞧瞧。
如果不愿意一个一个的加注解,那么就可以修改配置文件,整体修改:
#隔离级别数字配置含义:
#-1 数据库默认隔离级别
#1 未提交读
#2 读写提交
#4 可重复读
#8 串行化
spring:
datasource:
#tomcat数据源默认隔离级别
tomcat:
default-transaction-isolation: 2
#dbcp2数据库连接池默认隔离级别
dbcp2:
default-transaction-isolation: 2
但是最好不要配置整体,需要一个加一个注解也不麻烦啊对吧。
这里加一句题外话,SpringBoot2.x以后默认的数据库连接池:
1.如果你是引的starter的JPA和JDBC ,那默认就是 HikariCP
2.如果是外部引的JPA和JDBC,那就是用 Tomcat JDBC pool
都是SpringBoot根据情况选择的。
总结:
在现实中,选择隔离级别一般会以读写提交为主,为了克服数据不一致的问题,我们可以用乐观锁,甚至不再使用数据库而使用其他手段,比如用Redis作为数据载体。对于隔离级别,不同的数据库支持也是不一样的,比如Oracle只能支持读写提交和串行化,而Mysql则能够支持4中,Oracle默认读写提交,Mysql默认则是可重复读,这些需要根据具体数据库判断。
④、传播行为
传播行为就是在进行事务的时候所干的事儿!
有这么个情况:
执行一个批量程序,他会处理很多交易,绝大部分交易是可以顺利进行的,但是也有极少数的交易因为特殊原因不能完成而发生异常,这时我们不应该因为极少数的交易不能完成而回滚整个批量任务,使得那些本应该完成的交易也变得不能完成了。我们现在的需求是,在一个批量任务中,使那些能完成的顺利完成,不能完成的回滚,这时候就需要我们定义传播行为。
传播行为的7种定义上面已经说过了,用法跟隔离级别一样。

在这里着重介绍常用的三种传播行为:
- Propagation.REQUIRED:
默认的传播行为,如果该方法里面调用的方法有事务的存在,那么就沿用当前事务,如果没有就会创建一个,比如:
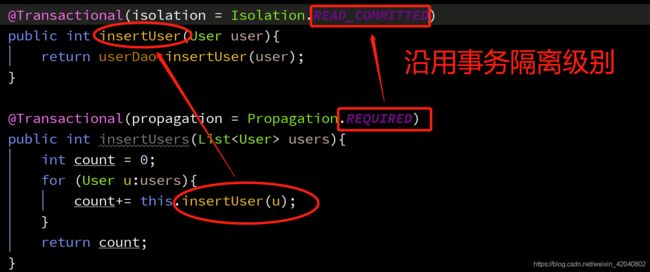
下面的方法调用了上面的方法,而上面用的事务隔离级别是读写提交隔离级别,那么下面的方法也会沿用读写提交隔离级别;
- Propagation.REQUIRES_NEW
无论当前方法有没有事务存在,都会创建新的事务,这样新事务就可以设置新的隔离等级等属性。

下面方法新建了属于自己的事务,每个insertUser方法都有自己独立的锁以及隔离级别。使得insertUser()这个方法脱离当前方法规定事务的管控,因为是每个insertUser方法都独立运行事务,所以开头说的那个场景就可以用到啦。
- Propagation.NESTED
沿用之前的事务,但是会在执行每一条sql的时候加一个标示点,如果哪个sql发生问题就回滚哪个,同样的,该传播行为也可以用于上面说的那个场景,可以说更加好用,因为spring在运行时也是使用保存点技术来完成让子事务回滚而当前事务不回滚的工作。注意:并不是所有数据库都支持保存点技术,当目前数据库不支持保存点技术时,可以用Propagation.REQUIRES_NEW。
NESTED和REQUIRES_NEW还是有区别的,NESTED会沿用当前事务的隔离级别和锁等特性而REQUIRES_NEW则是可以拥有自独立的隔离级别和锁等特性,这是在应用中需要注意的地方。
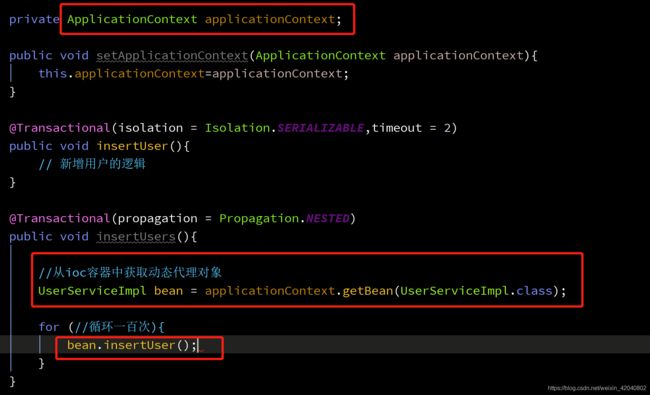
关于@Transactional自调用失调的问题
其实上面的代码在实际运用中是不能生效的,在这里就是为了给大家做演示用。
为什么呢?这牵扯到类自调用的方面。
该注解使用spring的AOP编程实现的,而aop的原理是使用动态代理,而自调用的时候是自身的类去调用,而不是动态代理对调用,那么aop就没用了,那就不会把我们的代码织入到约定的编程当中,@Transactional注解就自然而然失效了。
解决:
- 一个service调另一个service。
- 可以获得springIOC容器中的动态代理,去启动aop。
结语:
这篇文章是本人学习的一些感悟吧,由于本人知识和能力有限,文中如有没说清楚或者不对的地方,希望大家能在评论区指出,感激不尽。