卷积神经网络.经典神经网络模型之Inception Network
1. 1*1卷积核
在讲Inception network之前,首先介绍一下 Pointwise Network,即 1*1 卷积
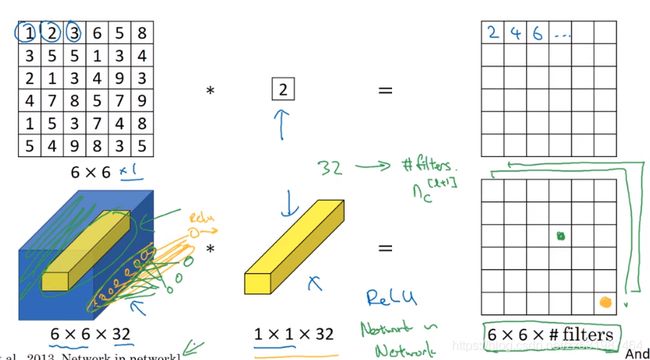
如上图所示,1*1卷积和普通卷积相同,只不过是其卷积核的宽高都是1*1的而已,所以对于1*1卷积的理解是其本质上是一个完全连接的神经网络,逐一作用在输入的36个(输入宽高6*6)不同的位置,这个完全连接的神经网络所做的是它接收32(输入的通道数为32)个数的输入,然后得到的输出特征图为 输入宽*输入高*过滤器数量
 ‘
‘
减小增加输出通道数Nc
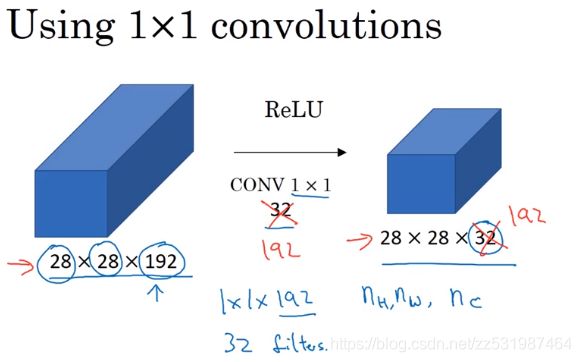
假设有一个28*28*192的输入,如果你想缩小它的高度和宽度,你可以使用一层池化层来达到目的;但如果通道数过大,我们想缩小它,将输出缩小到28*28*32的大小,那么可以使用32个1*1的卷积核来做卷积操作,即每个卷积核的大小为1*1*192(因为卷积核的通道数必须与输入通道数保持一致),所以得到最终的特征图输出为28*28*32,这样就达到了缩小输出通道Nc的目的,而池化层只能缩小输出的宽高,通过缩小通道数从而达到了在某些网络中减少计算量的目的。
增加非线性
当然如果你想要保持192个通道数,这样也是可行的,这时1*1卷积的效果是增加非线性。它通过添加一层输入28*28*192再输出28*28*192的操作(中间卷积核大小为1*1*192,卷积核数量为192,得到输出维度为28*28*192,输入和输出维度保持不变,但是在卷积之后经过了ReLU非线性函数,所以增加了非线性),使得你的网络可以学习到更复杂函数形式。
2. Inception Network
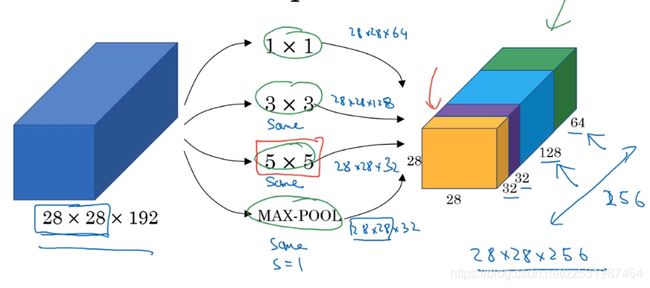
如上就是一个Inception模块,其输入为28*28*192,其经过一个网络层,该网络层包含多个数量不同,宽高不同的卷积核(如上图所示有1*1卷积核64个,3*3卷积核128个,5*5卷积核32个,做same conv,保证输入输出的维度相同)以及一个MAX-Pooling层,该池化层做same padding保证输出维度与输入维度一致,最终得到的输出维度大小为28*28*256(通道数为 64+128+32+32=256).
这个网络最基础的一个特点是不需要只挑选一个卷积核或者是池化,而是将多种卷积核进行组合,然后把所有的输出结果都连接起来,然后让神经网络去学习它想要用到的参数,以及它想要用到的卷积核大小.
但是这样这里就会存在一个计算成本问题,这里以上面的5*5的卷积核为例子
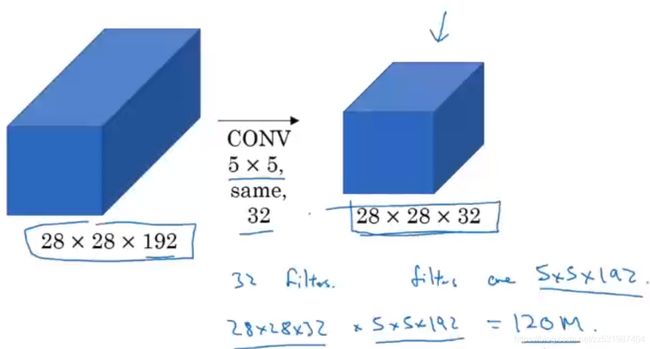
这里的卷积核大小为5*5*192,卷积核数量为32个,
那么总的参数数量为:(5*5*192+1)*32=153,632
总的所做的乘法运算数量为:5*5*192*28*28*32=120,422,400
虽然现在的计算机能够执行1.2亿次乘法运算,但是这个计算成本还是相当大的。
------------------
接下来我们通过中间添加使用1*1的卷积核来降低计算成本到大约 1/10 左右,从1.2亿次乘法运算到它的 1/10,但是输出维度和上面还是一样28*28*32,具体结构如下:

输入图像维度为28*28*192,首先经过1*1的卷积运算将通道数的个数从192减小为16,然后我们用这个相对较小的量去做5*5的卷积运算并得出最终输出的维度为28*28*32,这里和前面的方法一样都是从28*28*192输出到28*28*32。但是这里我们首先将28*28*192的输入减小成一个较小的中间值28*28*16,我们会将中间的这一层叫做bottleneck layer瓶颈层。
这里瓶颈层的卷积核数量为16,卷积核大小为1*1*192,那么生成这个28*28*16瓶颈层的参数数量为
(1*1*192+1)*16=3088,乘法运算成本为 28*28*16*(1*1*192)=2,408,448
从瓶颈层到输出层的卷积核数量为32,卷积核大小为5*5*16,那么这一层的参数数量为
(5*5*16+1)*32=12,832,乘法运算成本为 (5*5*16)*28*28*32=10,035,200
采用瓶颈层这种方式总的计算成本为2,408,448+10,035,200 = 12,443,648,运算成本相比第一种方法下降至1/10.
这里如此剧烈地缩小特征表示的大小会不会影响神经网络的性能?
这里只要我们合理地去实现这个瓶颈层,你既可以缩小输入张量的维度,又不会影响到整体的性能,还能节省计算成本。
所以这里我们总结一下:
如果你在建立一个卷积网络层,并且你不想去决定到底用1*1,3*3,5*5的卷积核或者是否使用pooling,那么就用这个inception模型,它会做所有的工作,并会将所有的结果都连接起来,同时我们使用1*1的卷积核来生成一个瓶颈层来显著降低计算成本。

于是,我们就得到了一个inception网络单个模块,我们将这些模块连接到一起,组成了一个完整的Inception网络结构,如下:
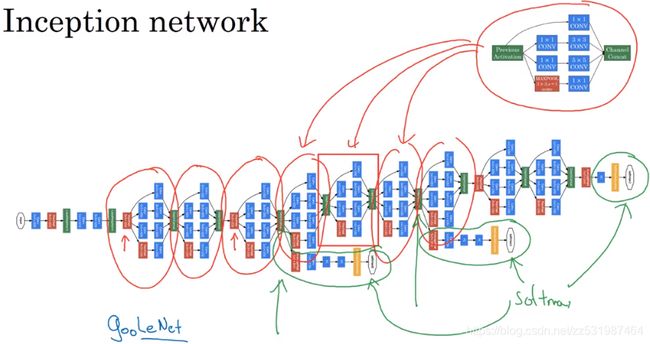
这个Inception网络中包含了很多的重复的Inception模块,其中还包含了两个旁支,这个旁支的作用就是它把隐藏层作为输入来做预测,经过一些网络层次,如一些连接层,然后通过softmax方程来预测输出的种类,它用来保证所计算的特征值,即使它们是在最头部的单元里或者在中间层里,他们对于预测结果来说不算太差,这是对Inception网络的正则化,用来防止这个网络的过度学习。