分布式文件系统基础
分布式文件系统
基础技术
A、 fstrim/discard
调用 TRIM整理 NAND上的碎片有两种方法,一是挂载 ext4分区时加上 discard选项,二是使用 fstrim命令。Android 4.3中的 TRIM是用 fstrim 实现的,但一般 Linux发行版并不建议使用 fstrim的方法,而是使用 mount ext4分区时加上 discard选项的办法。因为 discard选项会在每一个磁盘操作时同时执行 TRIM指令,所以可能会影响到删除文件时的性能。
通俗讲就是能把你删除了的文件彻底抹除,
系统删除文件的方法是把这个文件标记为已删除,而不是真的把这个文件从硬盘上抹除。这种删除方法对于传统的硬盘这类使用磁记录的没有关系,传统硬盘可以直接用磁头覆盖写入而不用考虑盘面上已经有了什么记录。但对于固态硬盘这类使用存储芯片的就不行了,所以需要这么设备有空时就抹除记录的技术,这样要写入数据的时候就能直接写入,而不是等到要写入的时候再去抹平这么临场操作,这样少了个步骤貌似硬盘写入就快了。
lustre
lustre 文件系统介绍
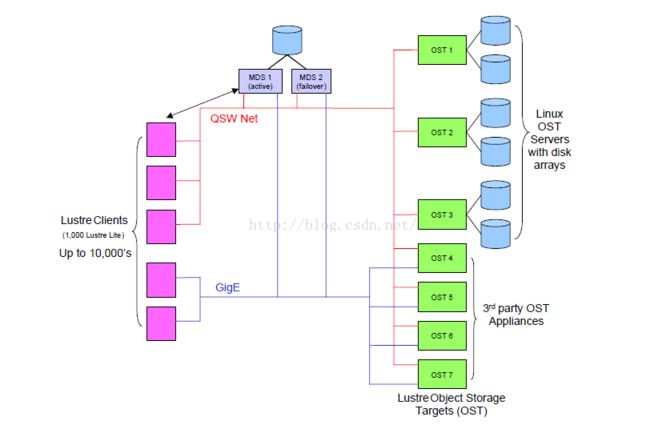
Luster是集群存储系统的结构。中心元件是lustre 文件系统,集群共享的文件系统。Lustre 目前linux可用并提供POSIX-compliant的UNIX文件系统接口。Lustre用于很多不同的集群中,最为出名的是世界上10个HPC中心的7个使用它,成千上万的客户端系统,PB级的存储能力和上百个GB/S的I/O吞吐率。很多HPC地点都使用lustre作为全球的文件系统,为很多史无前例的规模的集群服务。
最为重要的是,lustre文件系统用于多种用途,数据中心的后端文件系统,从互联网服务提供者到大型的金融机构。
lustre 集群
包含三个方面:
文件系统客户端:用来使用文件系统
对象存储服务器OSS:用来提供文件I/O服务
元数据服务器MDS:管理文件系统的名称和目录,并且存储元数据
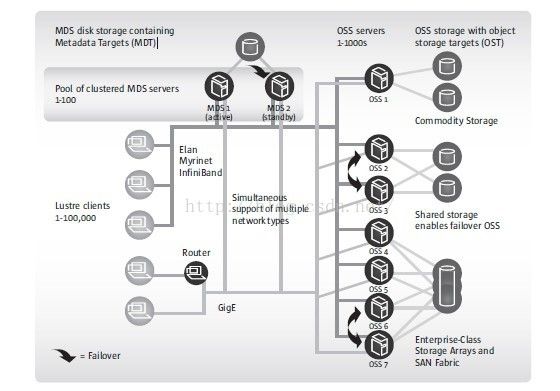
文件系统的配置:
安装lustre软件
使用标准的UNIX mkfs命令安装MDT和OST部分
带有lustre文件系统的目录将会被挂载到服务器节点上,作为本地的文件系统
Luster的客户端将以非常类似于NFS的方式挂载
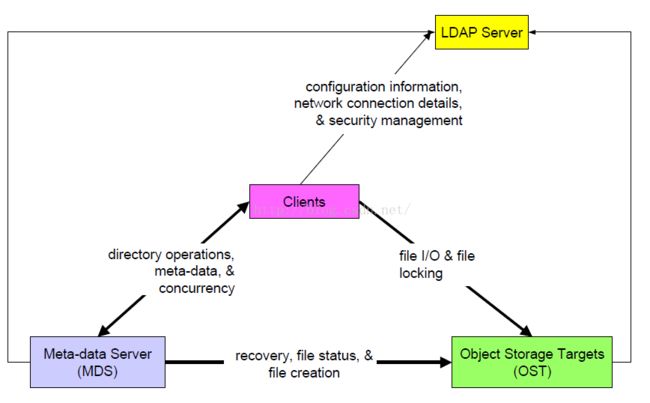
Luster网络
在安装了lustre的集群中,系统网络是服务端和客户端之间的网络连接。MDS和OSS服务端的磁盘存储使用的是传统的SAN技术,但是这个SAN不扩展到clusre的客户端上,所以并不需要SAN转换器。LNET只在系统网络上使用,这里它提供所有的lustre需要的通信基础设施。有一个网络抽象层(network abstraction layer).可以使用多种网络协议,这样可以在随着硬件和协议的发展,同痒可以使用本文件系统。
LNET的关键特征:
RDMA:被底层的网络所支持,例如,Elan,Myrinet,InfiniBand
支持多种通用的网络类型:InfiniBand和IP
高可用性和恢复特征使得透明的与故障恢复服务器恢复变为可能。
多网络类型下同时可用(网络路由连接)
在一次安装中可以使某些客户端连接到以太网,另外一些客户端连接到QWS网络上。
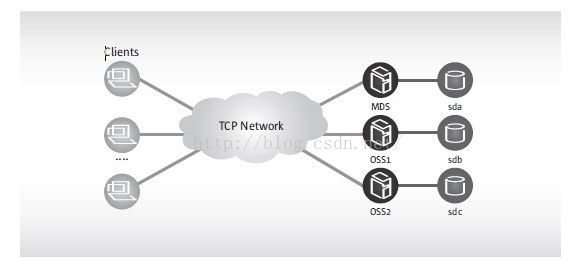
图 lustre的网络结构
其他
4 高可用性和滚动升级
5 文件存放的位置
6 另外的特征
7 lustre和其他的文件系统的比较
Lustre的元数据存放在mds上,数据存放在osd上,这样有问题吧?
ceph
Ceph是追求性能的分布式文件系统;
在保证数据可用性方面使用副本机制,而不是纠删码机制;这样保证了应用的高性能;
而相反,tahoe则使用纠删码来保证数据的高可用性,这样耗费更多的cpu,从而降低了系统的性能,但是极大的保障了安全性和可用性;
在数据分布算法上,ceph显然要比tahoe好,ceph使用的是可分层的CURSH算法,保证数据伪随机的分布在各个层次上;而tahoe使用的伪随机的hash算法,这种算法不能分层,而是将存储节点作为source进行hash,大集群中不能很好保证数据的均衡分布,从而导致负载不均衡的分布;
Ceph使用c++;tahoe使用python;python的跨平台性更强;
Ceph使用案例调研
在inktank的官网上,说明ceph可以被用于公有或私有云;但是具体的使用案例并没有进行说明;主要是其多副本机制,导致数据可靠性仍然比较低;默认为2个副本,而很多其他的类似文件系统都默认为3个,因为3个副本同时失效的概率已经非常低;(得出这种结论的依据是???)
目前,整个云存储行业的商业模式都不清晰。初步看来,是很多行业和应用都能使用云存储服务,但是,这样的应用少之又少。
MFS和ceph的数据可靠性都使用多副本机制来保障;
而且,MFS应用实例较多:网站http://www.gaokaochina.com/
监控(平安城市、平安校园)
广电行业(数据容灾)
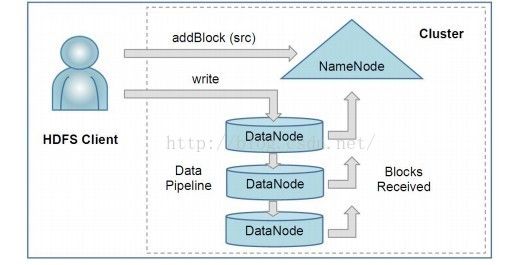
Hadoop FileSystem
主要由以下的部件组成:
1) NameNod 命名节点
2) DataNode 数据节点
3) HDFS Client HDFS客户端
结构图如下:
前提和设计目标
1、硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。
2、跑在HDFS上的应用与一般的应用不同,它们主要是以流式读为主,做批量处理;比之关注数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。
3、HDFS以支持大数据集合为目标,一个存储在上面的典型文件大小一般都在千兆至T字节,一个单一HDFS实例应该能支撑数以千万计的文件。
4、 HDFS应用对文件要求的是write-one-read-many访问模型。一个文件经过创建、写,关闭之后就不需要改变。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。典型的如MapReduce框架,或者一个web crawler应用都很适合这个模型。
5、移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效,这在数据达到海量级别的时候更是如此。将计算移动到数据附近,比之将数据移动到应用所在显然更好,HDFS提供给应用这样的接口。
6、在异构的软硬件平台间的可移植性。
Google Filesystem
GFS
Map/Reduce
分布式锁
Bigtable
GlusterFS
和ceph一样,属于分布式文件系统,没有mds元数据服务器;
应用范围较广,目前属于redhat维护;
Windows Azure
MFS(MooseFS)
Sector/Sphere分布式文件系统
是由一位在美攻读博士学位的中国人写的文件系统,始于2006年,目前的版本为2.5
Surfs
FastDFS
FastDFS是一个轻量级的分布式文件系统;
FastDFS主要解决了大容量的文件存储和高并发访问的问题,文件存取时实现了负载均衡
FastDFS实现了软件方式的RAID,可以使用廉价的IDE硬盘进行存储
支持存储服务器在线扩容
支持相同内容的文件只保存一份,节约磁盘空间
FastDFS只能通过Client API访问,不支持POSIX访问方式
FastDFS特别适合大中型网站使用,用来存储资源文件(如:图片、文档、音频、视频等等)
FastDFS使用源storage的方式避免文件更新时的不一致;(类似集群存储中的primary节点,可以使用异步方式,primary完成操作之后就返回客户端,这样,后续同步到replica的过程可以在后天进行)
Next generation file system
下一代文件系统探索:
基于flash等物理介质
虚拟化存储(按需扩展),分层(三副本或者N+2模式的容错性已经无法满足需求了),可扩展,现代化的接口(文件的接口,块的速度,类POSIX,REST,HDFS)