2019独角兽企业重金招聘Python工程师标准>>> 
互联网已经成为人们日常获取信息与沟通交流的重要方式,伴随用户规模的不断攀升每日的传播数据呈现爆发式增加。在这些海量数据中包括文本、图片、声音及视频多种格式,既有积极的也有消极的,甚至包括有悖伦理道德及违反法律法规的不良信息。为了创建一个良性的网络环境,有必要建立一套有效的机制,从海量信息中快速准确的识别出不良信息,切断其传播渠道,从而达到净化网络环境的目的。
敏感信息识别系统的设计应采用以机器为主导的,人工干预为辅助的处理机制,并随着算法的不断优化与数据模型的不断完善,逐步降低人工干预比例;系统设计应满足对“存量数据”和“增量数据”两种不同规模下,“全量扫描”与“抽样扫描”二种方式的支持;文本数据能够识别语言和字符集,图片、声音及视频等数据能够识别存储格式及编码类型;视频数据能够导出帧,通过逐帧或跳帧进行识别;系统应采用并行处理的计算机制,日处理能力不低于5TB;系统的识别算法应设计为立体多维度,降低因不合理的单一维度识别命中率而导致的偏差情况的发生,且算法模型应具备自我追加自我完善的动态机制。
敏感信息识别系统由建模层、识别层和存储层组成,实现从构建到应用再到持久化的完整流程。建模型的主要功能是提供建模所需要的各项基础要素,以机器自动化为主人工干预为辅,要素的质量直接关系到模型的品质与后期识别的正确率;识别层的任务是将模型放到业务中进行匹配操作,各个维度的加权计算可以有效纠正单一算法中加权因子缺失所导致的结果失真情况的发生,而模型自身是一个不断追加不算优化的过程,在业务应用服务中应采用预加载和空间换时间的思想来满足每日海量数据的计算需求;存储层存储元数据,敏感信息识别系统本身不应对存储层进行结构化修改,采用标注法对信息的敏感类型、敏感等级进行操作,对外提供人工复审接口,方便后期维护和效果检测。
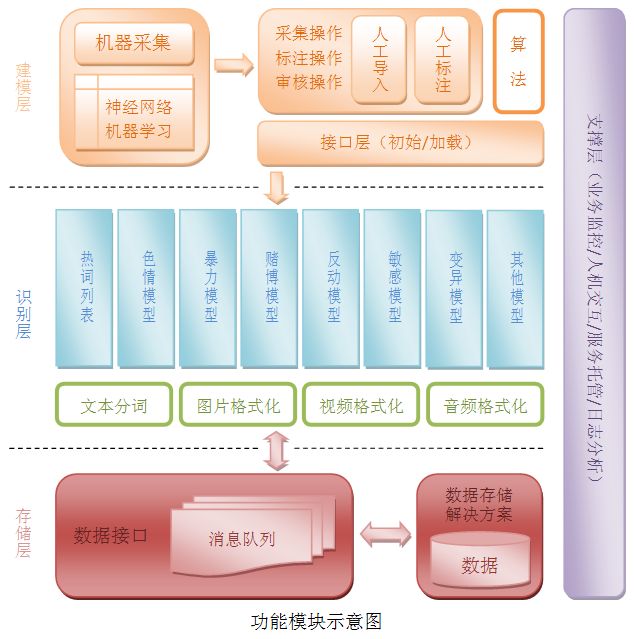
- 功能描述:
1、建模层
建模层由机采(机器采集)和人采(人工采集)两部分构成,系统在交付早期运营阶段,可由人工分拣样本数据到训练库,并对样本进行敏感类型及等级标注,在模型初具规模以后可逐步降低人工干预强度,进入良性学习阶段,人工不定期抽检即可。建模算法可采用基于单层神经网络的机器学习建模开源项目,文本数据分词后附带敏感类型作为入参,图片(视频)数据以文件集合附带分类标签作为入参,(语音数据待考),训练结果以二进制文件形式作为模型保存至业务端,以备识别层启动加载。
人采模块应提供到识别层模块地址的操作接口,由人工提供批量关键字导入,其他模型的样本规模每个应不少于100条信息。由于人工操作的主观性比较强,同一样本在不同的人看来可能敏感类型和等级均有偏差,为了避免这种情况的发生,一条敏感信息应至少由二名以上人员进行标注并取均值,重大网监时期可启动审核操作,最大程度杜绝敏感信息给公司业务带来的不利影响。
算法模块覆盖上述机采和人采功能,机采算法需密切关注行业在神经网络和人工智能方面技术前沿企业开源的算法专利与第三方库,人采算法是对机采算法进行业务相关性的修正,对敏感分类和评级打分体系进行平滑过渡处理,可适当引入相似度计算、海明距离等扩展性算法,增加近似度和词法联想的自然语言处理,但有必要关注扩展性算法对精准度的不利因素,应在充分测试的基础上逐步推进模型的优化工作。此外在算法模块中还应定期更新物料库的IDF文本模型,这有利于根据社会热点准实时调整热词基准率,对关键词提取有着重要意义。
2、识别层
识别层以建模层的输出作为输入,在业务具体的识别阶段,对模型进行初始加载操作,模型包括“功能模块示意图”中的模型项,但不仅限于此,可根据业务需要动态增减模型项,并支持热插拔操作。针对每个敏感模型返回的命中评分系统应具备一个汇总算法,即每个分类自身权重乘以其匹配度(百分比)累加值取对数,其结果是一个介于零和一之间的浮点数,来作为敏感最终评估计算的修正值。
文本处理首先判断字符集和语言,并根据需要转换为内部存储所对应的字符集,采用分词系统对元数据进行分词,删除停用词以后提取当前文本的关键词(取tfidf前五名保存),当热点事件在网络中迅速传播的时候通过屏蔽策略可大幅度降低传播热度。
图片格式化操作用来对不同格式的图片文件进行转换,以便统一入参格式。图片敏感信息的识别可考虑图片文件名称和图像内容两方面因素,其中文件名是图像内容的补充,在识别率较低的时候对名称进行追加识别,其目的在于宁肯轻微错判也绝不漏判。
视频格式化操作对视频流文件导出为帧集合,可以采用逐一帧识别,更可采用一定比例的跳帧随机抽取样本帧,复用图像识别操作判断敏感类型和等级,对全部帧或部分帧的识别结果进行汇总算法操作,作为该视频的最终敏感分类和等级的评定终值。
音频格式化操作可将音频内容转换成文本以后复用文本处理流程来实现敏感分类和等级的评定。
3、存储层
存储层是所有元数据的持久化解决方案,确保数据的安全性、完整性和一致性,逻辑上分为物理存储和读写接口。基于网络数据特性可采用半结构化的分布式存储解决方案来保存高扩展性的网页内容,消息队列即可满足先进先出的特性又能实现消息的自由订阅。接口层可以定期读取增量数据到消息队列,并推送到识别层的各个业务节点,节点可根据自己的设备负载情况自由消费队列数据,并在处理完毕后立即回写到消息队列的返回“主题”中,即便接口层或物理存储层发生异常,数据也可保留一定时间,避免丢失造成的损失。
4、支撑层
支撑层包括业务监控、人机交互、服务托管、日志跟踪等诸多辅助工具,用于确保整个系统高效平稳地运行,并未后续的算法优化和采集重心提供策略和依据。
5、序列化
敏感信息识别系统是一个独立且相对封闭的集成环境,模块间数据传输可能存在跨设备跨网络的情况,为了保证数据的安全性和完整性,需要在生产端序列化,并在消费端反序列化,ProtoBuf和aveo均是理想的高效序列化工具可供采用。序列化信息应包含版本号、信息类型、操作类型、(加密标识和密钥)、数据长度、数据信息、识别结果等字段。
- 流程说明:
1、数据采集
机器采集列表保存在关系型数据库中,前端通过页面开放给系统运营人员定制,爬取操作启动时加载。若没有原始页面应用需求可在页面解析完毕以后将有效数据放入系统总线中供后续业务模块消费。人工采集可将页面中的有效数据复制到人机交互页面作为敏感信息样本,同时标注分类和等级,前后端通过用户权限认证接口打通直接完成底层操作,同时预留外部接口供其他系统调用。
2、识别操作
系统根据配置项加载部分或全部识别模型,线程池从消息队列逐一读取记录并执行反序列化操作,根据数据类型执行不同的处理流程,模型匹配完成后进行汇总计算,序列化后回写系统总线消息队列主题,并对当前执行过程记录日志用于离线的效果分析。
3、总线队列
系统总线启动时可创建生产工作线程和消费工作线程,生产工作线程定时跟踪底层存储增量数据的变化情况,当有数据到达的时候,将待消费数据从存储中提取出来放入消费主题;消费工作线程在入口挂起等待,有新消息的时候自动触发回写操作,更新底层的原址数据。
4、日志分析
日志分析系统以小时为单位(实时性要求较高的系统另议),采用批处理方式对日志数据进行分析并生成报表,统计得到数据规模、敏感信息比例、敏感信息强度、传播频次热度以及识别准确率等。
5、支撑系统
业务监控和服务托管可以采用众多成熟的第三方解决方案,方便运维人员实时关注服务器压力负载和资源占用情况,避免硬件和网络故障导致的服务异常情况。
6、对外接口
支撑系统预留对外操作接口为第三方提供敏感信息识别分析和统计服务,为将来业务拓展打下基础。