Flink是一个分布式的流处理引擎,而流处理的其中一个特点就是7X24。那么,如何保障Flink作业的持续运行呢?Flink的内部会将应用状态(state)存储到本地内存或者嵌入式的kv数据库(RocksDB)中,由于采用的是分布式架构,Flink需要对本地生成的状态进行持久化存储,以避免因应用或者节点机器故障等原因导致数据的丢失,Flink是通过checkpoint(检查点)的方式将状态写入到远程的持久化存储,从而就可以实现不同语义的结果保障。通过本文,你可以了解到什么是Flink的状态,Flink的状态是怎么存储的,Flink可选择的状态后端(statebackend)有哪些,什么是全局一致性检查点,Flink内部如何通过检查点实现Exactly Once的结果保障。另外,本文内容较长,建议关注加收藏。
什么是状态
引子
关于什么是状态,我们先不做过多的分析。首先看一个代码案例,其中案例1是Spark的WordCount代码,案例2是Flink的WorkCount代码。
- 案例1:Spark WC
object WordCount {
def main(args:Array[String]){
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
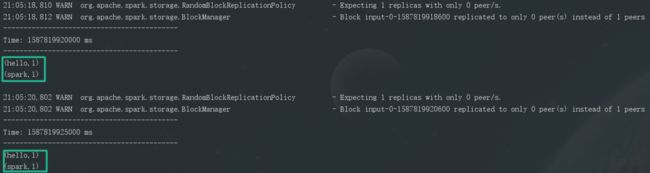
}输入:
C:\WINDOWS\system32>nc -lp 9999
hello spark
hello spark输出:
- 案例2:Flink WC
public class WordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DataStreamSource streamSource = env.socketTextStream("localhost", 9999);
SingleOutputStreamOperator> words = streamSource.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String value, Collector> out) throws Exception {
String[] splits = value.split("\\s");
for (String word : splits) {
out.collect(Tuple2.of(word, 1));
}
}
});
words.keyBy(0).sum(1).print();
env.execute("WC");
}
} 输入:
C:\WINDOWS\system32>nc -lp 9999
hello Flink
hello Flink输出: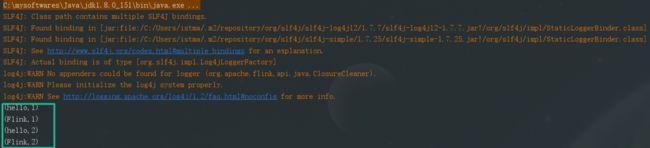
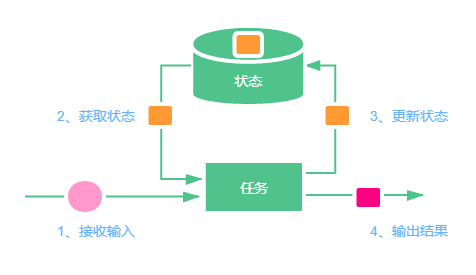
从上面的两个例子可以看出,在使用Spark进行词频统计时,当前的统计结果不受历史统计结果的影响,只计算接收的当前数据的结果,这个就可以理解为无状态的计算。再来看一下Flink的例子,可以看出当第二次词频统计时,把第一次的结果值也统计在了一起,即Flink把上一次的计算结果保存在了状态里,第二次计算的时候会先拿到上一次的结果状态,然后结合新到来的数据再进行计算,这就可以理解成有状态的计算,如下图所示。
状态的类别
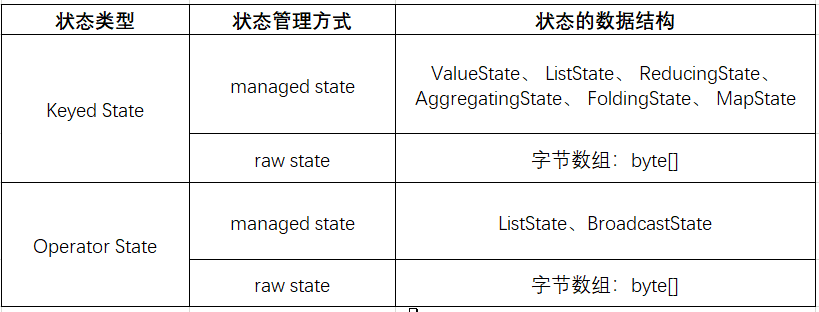
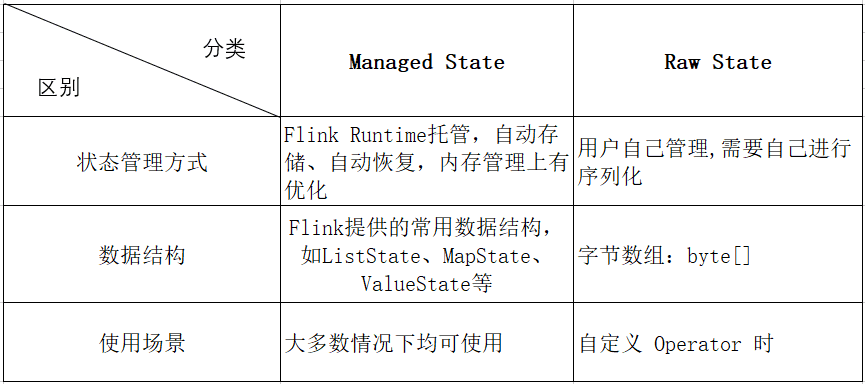
Flink提供了两种基本类型的状态:分别是 Keyed State 和Operator State。根据不同的状态管理方式,每种状态又有两种存在形式,分别为:managed(托管状态)和raw(原生状态)。具体如下表格所示。需要注意的是,由于Flink推荐使用managed state,所以下文主要讨论managed state,对于raw state,本文不会做过多的讨论。
managed state & raw state区别
Keyed State & Operator State

Keyed State
Keyed State只能由作用在KeyedStream上面的函数使用,该状态与某个key进行绑定,即每一个key对应一个state。Keyed State按照key进行维护和访问的,Flink会为每一个Key都维护一个状态实例,该状态实例总是位于处理该key记录的算子任务上,因此同一个key的记录可以访问到一样的状态。如下图所示,可以通过在一条流上使用keyBy()方法来生成一个KeyedStream。Flink提供了很多种keyed state,具体如下:

- ValueState
用于保存类型为T的单个值。用户可以通过ValueState.value()来获取该状态值,通过ValueState.update()来更新该状态。使用ValueStateDescriptor来获取状态句柄。
- ListState
用于保存类型为T的元素列表,即key的状态值是一个列表。用户可以使用ListState.add()或者ListState.addAll()将新元素添加到列表中,通过ListState.get()访问状态元素,该方法会返回一个可遍历所有元素的IterableListStateDescriptor来获取状态句柄。
- ReducingState
调用add()方法添加值时,会立即返回一个使用ReduceFunction聚合后的值,用户可以使用ReducingState.get()来获取该状态值。使用 ReducingStateDescriptor来获取状态句柄。
- AggregatingState
与ReducingStateAggregatingStateDescriptor来获取状态句柄
- MapState
用于保存一组key、value的映射,类似于java的Map集合。用户可以通过get(UK key)方法获取key对应的状态,可以通过put(UK k,UV value)方法添加一个键值,可以通过remove(UK key)删除给定key的值,可以通过contains(UK key)判断是否存在对应的key。使用 MapStateDescriptor来获取状态句柄。
- FoldingState
在Flink 1.4的版本中标记过时,在未来的版本中会被移除,使用AggregatingState进行代替。
值得注意的是,上面的状态原语都支持通过State.clear()方法来进行清除状态。另外,上述的状态原语仅用于与状态进行交互,真正的状态是存储在状态后端(后面会介绍状态后端)的,通过该状态原语相当于持有了状态的句柄(handle)。
keyed State使用案例
下面给出一个MapState的使用案例,关于ValueState的使用情况可以参考官网,具体如下:
public class MapStateExample {
//统计每个用户每种行为的个数
public static class UserBehaviorCnt extends RichFlatMapFunction, Tuple3> {
//定义一个MapState句柄
private transient MapState behaviorCntState;
// 初始化状态
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
MapStateDescriptor userBehaviorMapStateDesc = new MapStateDescriptor<>(
"userBehavior", // 状态描述符的名称
TypeInformation.of(new TypeHint() {}), // MapState状态的key的数据类型
TypeInformation.of(new TypeHint() {}) // MapState状态的value的数据类型
);
behaviorCntState = getRuntimeContext().getMapState(userBehaviorMapStateDesc); // 获取状态
}
@Override
public void flatMap(Tuple3 value, Collector> out) throws Exception {
Integer behaviorCnt = 1;
// 如果当前状态包括该行为,则+1
if (behaviorCntState.contains(value.f1)) {
behaviorCnt = behaviorCntState.get(value.f1) + 1;
}
// 更新状态
behaviorCntState.put(value.f1, behaviorCnt);
out.collect(Tuple3.of(value.f0, value.f1, behaviorCnt));
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 模拟数据源[userId,behavior,product]
DataStreamSource> userBehaviors = env.fromElements(
Tuple3.of(1L, "buy", "iphone"),
Tuple3.of(1L, "cart", "huawei"),
Tuple3.of(1L, "buy", "logi"),
Tuple3.of(1L, "fav", "oppo"),
Tuple3.of(2L, "buy", "huawei"),
Tuple3.of(2L, "buy", "onemore"),
Tuple3.of(2L, "fav", "iphone"));
userBehaviors
.keyBy(0)
.flatMap(new UserBehaviorCnt())
.print();
env.execute("MapStateExample");
}
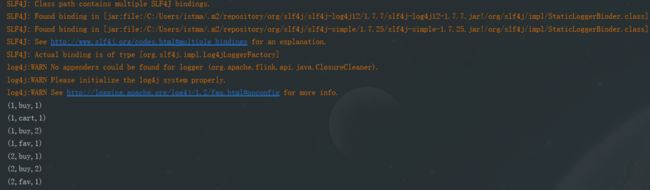
} 结果输出:
状态的生命周期管理(TTL)
对于任何类型Keyed State都可以设定状态的生命周期(TTL),即状态的存活时间,以确保能够在规定时间内及时地清理状态数据。如果配置了状态的TTL,那么当状态过期时,存储的状态会被清除。状态生命周期功能可以通过StateTtlConfig配置,然后将StateTtlConfig配置传入StateDescriptor中的enableTimeToLive方法中即可。代码示例如下:
StateTtlConfig ttlConfig = StateTtlConfig
// 指定TTL时长为10S
.newBuilder(Time.seconds(10))
// 只对创建和写入操作有效
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 不返回过期的数据
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
// 初始化状态
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
MapStateDescriptor userBehaviorMapStateDesc = new MapStateDescriptor<>(
"userBehavior", // 状态描述符的名称
TypeInformation.of(new TypeHint() {}), // MapState状态的key的数据类型
TypeInformation.of(new TypeHint() {}) // MapState状态的value的数据类型
);
// 设置stateTtlConfig
userBehaviorMapStateDesc.enableTimeToLive(ttlConfig);
behaviorCntState = getRuntimeContext().getMapState(userBehaviorMapStateDesc); // 获取状态
} 在StateTtlConfig创建时,newBuilder方法是必须要指定的,newBuilder中设定过期时间的参数。对于其他参数都是可选的或使用默认值。其中setUpdateType方法中传入的类型有三种:
public enum UpdateType {
//禁用TTL,永远不会过期
Disabled,
// 创建和写入时更新TTL
OnCreateAndWrite,
// 与OnCreateAndWrite类似,但是在读操作时也会更新TTL
OnReadAndWrite
}值得注意的是,过期的状态数据根据UpdateType参数进行配置,只有被写入或者读取的时间才会更新TTL,也就是说如果某个状态指标一直不被使用或者更新,则永远不会触发对该状态数据的清理操作,这种情况可能会导致系统中的状态数据越来越大。目前用户可以使用StateTtlConfig.cleanupFullSnapshot设定当触发State Snapshot的时候清理状态数据,但是改配置不适合用于RocksDB做增量Checkpointing的操作。
上面的StateTtlConfig创建时,可以指定setStateVisibility,用于状态的可见性配置,根据过期数据是否被清理来确定是否返回状态数据。
/**
* 是否返回过期的数据
*/
public enum StateVisibility {
//如果数据没有被清理,就可以返回
ReturnExpiredIfNotCleanedUp,
//永远不返回过期的数据,默认值
NeverReturnExpired
}Operator State
Operator State的作用于是某个算子任务,这意味着所有在同一个并行任务之内的记录都能访问到相同的状态 。算子状态不能通过其他任务访问,无论该任务是相同的算子。如下图所示。
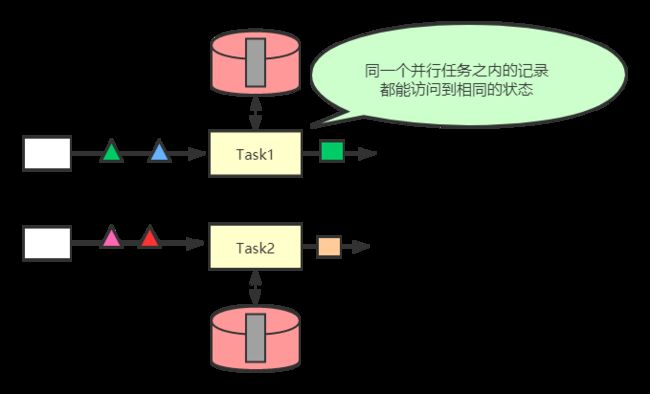
Operator State是一种non-keyed state,与并行的操作算子实例相关联,例如在Kafka Connector中,每个Kafka消费端算子实例都对应到Kafka的一个分区中,维护Topic分区和Offsets偏移量作为算子的Operator State。在Flink中可以实现ListCheckpointed
首先,我们先看一下这两个接口的具体实现,然后再给出这两种接口的具体使用案例。先看一下ListCheckpointed接口的源码,如下:
public interface ListCheckpointed {
/**
* 获取某个算子实例的当前状态,该状态包括该算子实例之前被调用时的所有结果
* 以列表的形式返回一个函数状态的快照
* Flink触发生成检查点时调用该方法
* @param checkpointId checkpoint的ID,是一个唯一的、单调递增的值
* @param timestamp Job Manager触发checkpoint时的时间戳
* @return 返回一个operator state list,如果为null时,返回空list
* @throws Exception
*/
List snapshotState(long checkpointId, long timestamp) throws Exception;
/**
* 初始化函数状态时调用,可能是在作业启动时或者故障恢复时
* 根据提供的列表恢复函数状态
* 注意:当实现该方法时,需要在RichFunction#open()方法之前调用该方法
* @param state 被恢复算子实例的state列表 ,可能为空
* @throws Exception
*/
void restoreState(List state) throws Exception;
}
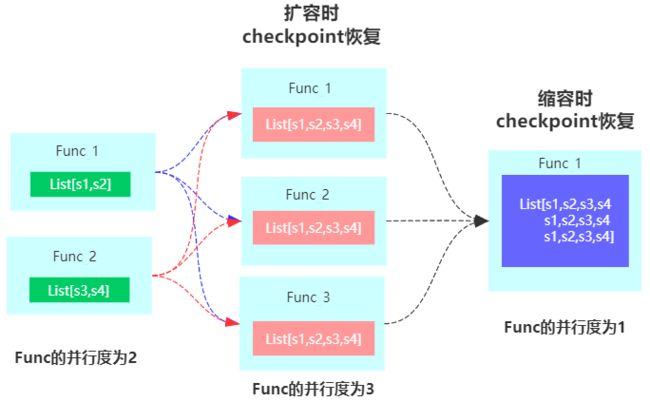
使用Operator ListState时,在进行扩缩容时,重分布的策略(状态恢复的模式)如下图所示:
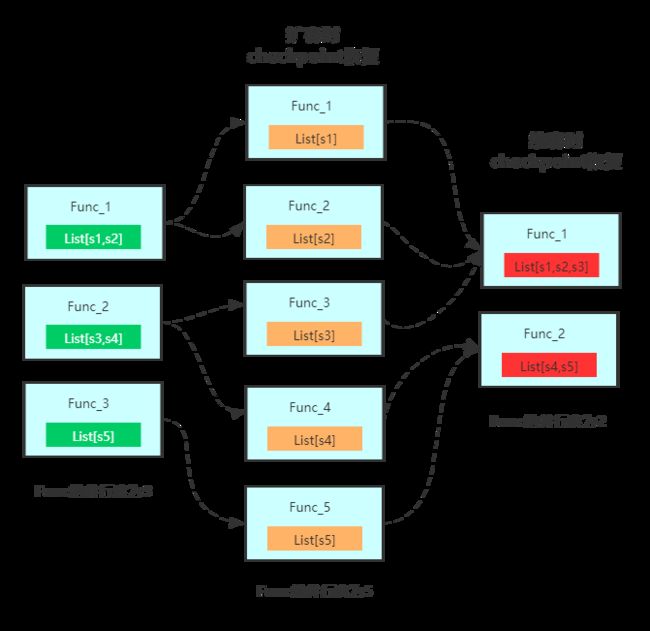
上面的重分布策略为Even-split Redistribution,即每个算子实例中含有部分状态元素的List列表,整个状态数据是所有List列表的合集。当触发restore/redistribution动作时,通过将状态数据平均分配成与算子并行度相同数量的List列表,每个task实例中有一个List,其可以为空或者含有多个元素。
我们再来看一下CheckpointedFunction接口,源码如下:
public interface CheckpointedFunction {
/**
* 会在生成检查点之前调用
* 该方法的目的是确保检查点开始之前所有状态对象都已经更新完毕
* @param context 使用FunctionSnapshotContext作为参数
* 从FunctionSnapshotContext可以获取checkpoint的元数据信息,
* 比如checkpoint编号,JobManager在初始化checkpoint时的时间戳
* @throws Exception
*/
void snapshotState(FunctionSnapshotContext context) throws Exception;
/**
* 在创建checkpointedFunction的并行实例时被调用,
* 在应用启动或者故障重启时触发该方法的调用
* @param context 传入FunctionInitializationContext对象,
* 可以使用该对象访问OperatorStateStore和 KeyedStateStore对象,
* 这两个对象可以获取状态的句柄,即通过Flink runtime来注册函数状态并返回state对象
* 比如:ValueState、ListState等
* @throws Exception
*/
void initializeState(FunctionInitializationContext context) throws Exception;
}
CheckpointedFunction接口是用于指定有状态函数的最底层的接口,该接口提供了用于注册和维护keyed state 与operator state的hook(即可以同时使用keyed state 和operator state),另外也是唯一支持使用list union state。关于Union List State,使用的是Flink为Operator state提供的另一种重分布的策略:Union Redistribution,即每个算子实例中含有所有状态元素的List列表,当触发restore/redistribution动作时,每个算子都能够获取到完整的状态元素列表。具体如下图所示:
ListCheckpointed
ListCheckpointed接口和CheckpointedFunction接口相比在灵活性上相对弱一些,只能支持List类型的状态,并且在数据恢复的时候仅支持even-redistribution策略。该接口不像Flink提供的Keyed State(比如Value State、ListState)那样直接在状态后端(state backend)注册,需要将operator state实现为成员变量,然后通过接口提供的回调函数与状态后端进行交互。使用代码案例如下:
public class ListCheckpointedExample {
private static class UserBehaviorCnt extends RichFlatMapFunction, Tuple2> implements ListCheckpointed {
private Long userBuyBehaviorCnt = 0L;
@Override
public void flatMap(Tuple3 value, Collector> out) throws Exception {
if(value.f1.equals("buy")){
userBuyBehaviorCnt ++;
out.collect(Tuple2.of("buy",userBuyBehaviorCnt));
}
}
@Override
public List snapshotState(long checkpointId, long timestamp) throws Exception {
//返回单个元素的List集合,该集合元素是用户购买行为的数量
return Collections.singletonList(userBuyBehaviorCnt);
}
@Override
public void restoreState(List state) throws Exception {
// 在进行扩缩容之后,进行状态恢复,需要把其他subtask的状态加在一起
for (Long cnt : state) {
userBuyBehaviorCnt += 1;
}
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 模拟数据源[userId,behavior,product]
DataStreamSource> userBehaviors = env.fromElements(
Tuple3.of(1L, "buy", "iphone"),
Tuple3.of(1L, "cart", "huawei"),
Tuple3.of(1L, "buy", "logi"),
Tuple3.of(1L, "fav", "oppo"),
Tuple3.of(2L, "buy", "huawei"),
Tuple3.of(2L, "buy", "onemore"),
Tuple3.of(2L, "fav", "iphone"));
userBehaviors
.flatMap(new UserBehaviorCnt())
.print();
env.execute("ListCheckpointedExample");
}
}
CheckpointedFunction
CheckpointedFunction接口提供了更加丰富的操作,比如支持Union list state,可以访问keyedState,关于重分布策略,如果使用Even-split Redistribution策略,则通过context. getListState(descriptor)获取Operator State;如果使用UnionRedistribution策略,则通过context. getUnionList State(descriptor)来获取。使用案例如下:
public class CheckpointFunctionExample {
private static class UserBehaviorCnt implements CheckpointedFunction, FlatMapFunction, Tuple3> {
// 统计每个operator实例的用户行为数量的本地变量
private Long opUserBehaviorCnt = 0L;
// 每个key的state,存储key对应的相关状态
private ValueState keyedCntState;
// 定义operator state,存储算子的状态
private ListState opCntState;
@Override
public void flatMap(Tuple3 value, Collector> out) throws Exception {
if (value.f1.equals("buy")) {
// 更新算子状态本地变量值
opUserBehaviorCnt += 1;
Long keyedCount = keyedCntState.value();
// 更新keyedstate的状态 ,判断状态是否为null,否则空指针异常
keyedCntState.update(keyedCount == null ? 1L : keyedCount + 1 );
// 结果输出
out.collect(Tuple3.of(value.f0, keyedCntState.value(), opUserBehaviorCnt));
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// 使用opUserBehaviorCnt本地变量更新operator state
opCntState.clear();
opCntState.add(opUserBehaviorCnt);
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
// 通过KeyedStateStore,定义keyedState的StateDescriptor描述符
ValueStateDescriptor valueStateDescriptor = new ValueStateDescriptor("keyedCnt", TypeInformation.of(new TypeHint() {
}));
// 通过OperatorStateStore,定义OperatorState的StateDescriptor描述符
ListStateDescriptor opStateDescriptor = new ListStateDescriptor("opCnt", TypeInformation.of(new TypeHint() {
}));
// 初始化keyed state状态值
keyedCntState = context.getKeyedStateStore().getState(valueStateDescriptor);
// 初始化operator state状态
opCntState = context.getOperatorStateStore().getListState(opStateDescriptor);
// 初始化本地变量operator state
for (Long state : opCntState.get()) {
opUserBehaviorCnt += state;
}
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 模拟数据源[userId,behavior,product]
DataStreamSource> userBehaviors = env.fromElements(
Tuple3.of(1L, "buy", "iphone"),
Tuple3.of(1L, "cart", "huawei"),
Tuple3.of(1L, "buy", "logi"),
Tuple3.of(1L, "fav", "oppo"),
Tuple3.of(2L, "buy", "huawei"),
Tuple3.of(2L, "buy", "onemore"),
Tuple3.of(2L, "fav", "iphone"));
userBehaviors
.keyBy(0)
.flatMap(new UserBehaviorCnt())
.print();
env.execute("CheckpointFunctionExample");
}
}
什么是状态后端
上面使用的状态都需要存储到状态后端(StateBackend),然后在checkpoint触发时,将状态持久化到外部存储系统。Flink提供了三种类型的状态后端,分别是基于内存的状态后端(MemoryStateBackend、基于文件系统的状态后端(FsStateBackend)以及基于RockDB作为存储介质的RocksDB StateBackend。这三种类型的StateBackend都能够有效地存储Flink流式计算过程中产生的状态数据,在默认情况下Flink使用的是MemoryStateBackend,区别见下表。下面分别对每种状态后端的特点进行说明。
状态后端的类别
MemoryStateBackend
MemoryStateBackend将状态数据全部存储在JVM堆内存中,包括用户在使用DataStream API中创建的Key/Value State,窗口中缓存的状态数据,以及触发器等数据。MemoryStateBackend具有非常快速和高效的特点,但也具有非常多的限制,最主要的就是内存的容量限制,一旦存储的状态数据过多就会导致系统内存溢出等问题,从而影响整个应用的正常运行。同时如果机器出现问题,整个主机内存中的状态数据都会丢失,进而无法恢复任务中的状态数据。因此从数据安全的角度建议用户尽可能地避免在生产环境中使用MemoryStateBackend。Flink将MemoryStateBackend作为默认状态后端。
MemoryStateBackend比较适合用于测试环境中,并用于本地调试和验证,不建议在生产环境中使用。但如果应用状态数据量不是很大,例如使用了大量的非状态计算算子,也可以在生产环境中使MemoryStateBackend.
FsStateBackend
FsStateBackend是基于文件系统的一种状态后端,这里的文件系统可以是本地文件系统,也可以是HDFS分布式文件系统。创建FsStateBackend的构造函数如下:
FsStateBackend(Path checkpointDataUri, boolean asynchronousSnapshots)
其中path如果为本地路径,其格式为“file:///data/flink/checkpoints”,如果path为HDFS路径,其格式为“hdfs://nameservice/flink/checkpoints”。FsStateBackend中第二个Boolean类型的参数指定是否以同步的方式进行状态数据记录,默认采用异步的方式将状态数据同步到文件系统中,异步方式能够尽可能避免在Checkpoint的过程中影响流式计算任务。如果用户想采用同步的方式进行状态数据的检查点数据,则将第二个参数指定为True即可。
相比于MemoryStateBackend, FsStateBackend更适合任务状态非常大的情况,例如应用中含有时间范围非常长的窗口计算,或Key/value State状态数据量非常大的场景,这时系统内存不足以支撑状态数据的存储。同时FsStateBackend最大的好处是相对比较稳定,在checkpoint时,将状态持久化到像HDFS分布式文件系统中,能最大程度保证状态数据的安全性。
RocksDBStateBackend
与前面的状态后端不同,RocksDBStateBackend需要单独引入相关的依赖包。RocksDB 是一个 key/value 的内存存储系统,类似于HBase,是一种内存磁盘混合的 LSM DB。当写数据时会先写进write buffer(类似于HBase的memstore),然后在flush到磁盘文件,当读取数据时会现在block cache(类似于HBase的block cache),所以速度会很快。
RocksDBStateBackend在性能上要比FsStateBackend高一些,主要是因为借助于RocksDB存储了最新热数据,然后通过异步的方式再同步到文件系统中,但RocksDBStateBackend和MemoryStateBackend相比性能就会较弱一些。
需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。不过 RocksDB 支持增量的 Checkpoint,也是目前唯一增量 Checkpoint 的 Backend,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单 Key最大 2G,总大小不超过配置的文件系统容量即可。对于超大状态的作业,例如天级窗口聚合等场景下可以使会用该状态后端。
配置状态后端
Flink默认使用的状态后端是MemoryStateBackend,所以不需要显示配置。对于其他的状态后端,都需要进行显性配置。在Flink中包含了两种级别的StateBackend配置:一种是在程序中进行配置,该配置只对当前应用有效;另外一种是通过 flink-conf.yaml进行全局配置,一旦配置就会对整个Flink集群上的所有应用有效。
- 应用级别配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
如果使用RocksDBStateBackend则需要单独引入rockdb依赖库,如下:
org.apache.flink
flink-statebackend-rocksdb_2.11
1.10.0
provided
使用方式与FsStateBackend类似,如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints"));
- 集群级别配置
具体的配置项在flink-conf.yaml文件中,如下代码所示,参数state.backend指明StateBackend类型,state.checkpoints.dir配置具体的状态存储路径,代码中使用filesystem作为StateBackend,然后指定相应的HDFS文件路径作为state的checkpoint文件夹。
# 使用filesystem存储
state.backend: filesystem
# checkpoint存储路径
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
如果想用RocksDBStateBackend配置集群级别的状态后端,可以使用下面的配置:
# 操作RocksDBStateBackend的线程数量,默认值为1
state.backend.rocksdb.checkpoint.transfer.thread.num: 1
# 指定RocksDB存储状态数据的本地文件路径
state.backend.rocksdb.localdir: /var/rockdb/checkpoints
# 用于指定定时器服务的工厂类实现类,默认为“HEAP”,也可以指定为“RocksDB”
state.backend.rocksdb.timer-service.factory: HEAP
什么是Checkpoint(检查点)
上面讲解了Flink的状态以及状态后端,状态是存储在状态后端。为了保证state容错,Flink提供了处理故障的措施,这种措施称之为checkpoint(一致性检查点)。checkpoint是Flink实现容错的核心功能,主要是周期性地触发checkpoint,将state生成快照持久化到外部存储系统(比如HDFS)。这样一来,如果Flink程序出现故障,那么就可以从上一次checkpoint中进行状态恢复,从而提供容错保障。另外,通过checkpoint机制,Flink可以实现Exactly-once语义(Flink内部的Exactly-once,关于端到端的exactly_once,Flink是通过两阶段提交协议实现的)。下面将会详细分析Flink的checkpoint机制。
检查点的生成

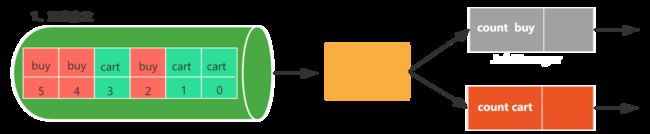
如上图,输入流是用户行为数据,包括购买(buy)和加入购物车(cart)两种,每种行为数据都有一个偏移量,统计每种行为的个数。
第一步:JobManager checkpoint coordinator 触发checkpoint。
第二步:假设当消费到[cart,3]这条数据时,触发了checkpoint。那么此时数据源会把消费的偏移量3写入持久化存储。
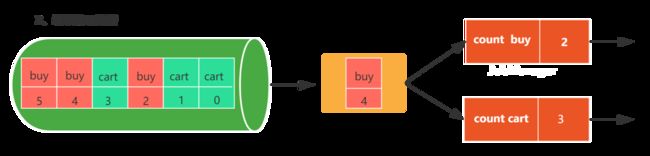
第三步:当写入结束后,source会将state handle(状态存储路径)反馈给JobManager的checkpoint coordinator。
第四步:接着算子count buy与count cart也会进行同样的步骤
第五步:等所有的算子都完成了上述步骤之后,即当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件,那么整个checkpoint也就完成了,如果中间有一个不成功,那么本次checkpoin就宣告失败。
检查点的恢复
通过上面的分析,或许你已经对Flink的checkpoint有了初步的认识。那么接下来,我们看一下是如何从检查点恢复的。
- 任务失败

- 重启作业
- 恢复检查点

- 继续处理数据
上述过程具体总结如下:
- 第一步:重启作业
- 第二步:从上一次检查点恢复状态数据
- 第三步:继续处理新的数据
Flink内部Exactly-Once实现
Flink提供了精确一次的处理语义,精确一次的处理语义可以理解为:数据可能会重复计算,但是结果状态只有一个。Flink通过Checkpoint机制实现了精确一次的处理语义,Flink在触发Checkpoint时会向Source端插入checkpoint barrier,checkpoint barriers是从source端插入的,并且会向下游算子进行传递。checkpoint barriers携带一个checkpoint ID,用于标识属于哪一个checkpoint,checkpoint barriers将流逻辑是哪个分为了两部分。对于双流的情况,通过barrier对齐的方式实现精确一次的处理语义。
关于什么是checkpoint barrier,可以看一下CheckpointBarrier类的源码描述,如下:
/**
* Checkpoint barriers用来在数据流中实现checkpoint对齐的.
* Checkpoint barrier由JobManager的checkpoint coordinator插入到Source中,
* Source会把barrier广播发送到下游算子,当一个算子接收到了其中一个输入流的Checkpoint barrier时,
* 它就会知道已经处理完了本次checkpoint与上次checkpoint之间的数据.
*
* 一旦某个算子接收到了所有输入流的checkpoint barrier时,
* 意味着该算子的已经处理完了截止到当前checkpoint的数据,
* 可以触发checkpoint,并将barrier向下游传递
*
* 根据用户选择的处理语义,在checkpoint完成之前会缓存后一次checkpoint的数据,
* 直到本次checkpoint完成(exactly once)
*
* checkpoint barrier的id是严格单调递增的
*
*/
public class CheckpointBarrier extends RuntimeEvent {...}
可以看出checkpoint barrier主要功能是实现checkpoint对齐的,从而可以实现Exactly-Once处理语义。
下面将会对checkpoint过程进行分解,具体如下:
图1,包括两个流,每个任务都会消费一条用户行为数据(包括购买(buy)和加购(cart)),数字代表该数据的偏移量,count buy任务统计购买行为的个数,coun cart统计加购行为的个数。
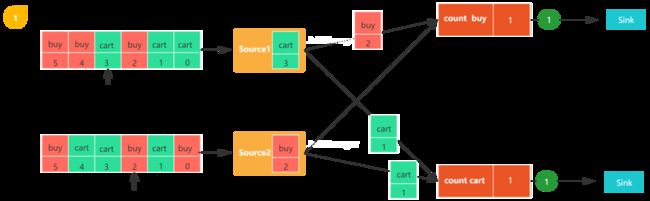
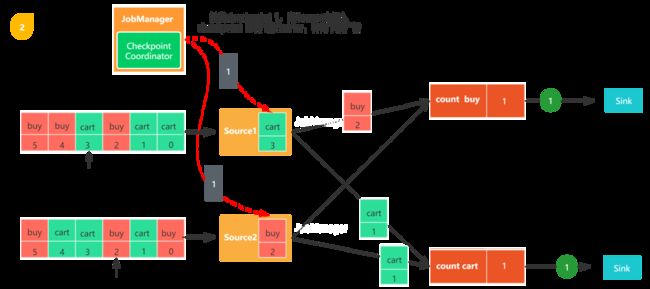
图2,触发checkpoint,JobManager会向每个数据源发送一个新的checkpoint编号,以此来启动检查点生成流程。
-
图3,当Source任务收到消息后,会停止发出数据,然后利用状态后端触发生成本地状态检查点,并把该checkpoint barrier以及checkpoint id广播至所有传出的数据流分区。状态后端会在checkpoint完成之后通知任务,随后任务会向Job Manager发送确认消息。在将checkpoint barrier发出之后,Source任务恢复正常工作。
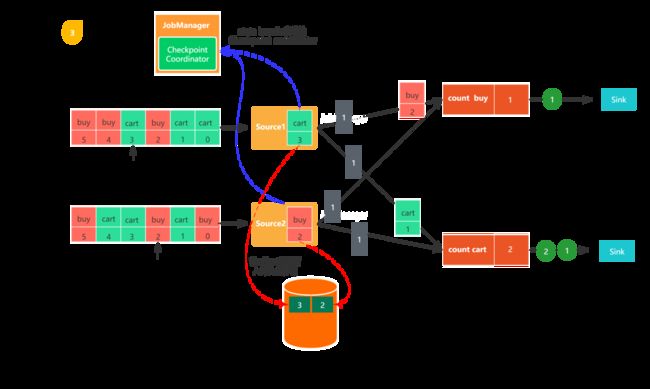
- 图4,Source任务发出的checkpoint barrier会发送到与之相连的下游算子任务,当任务收到一个新的checkpoint barrier时,会继续等待其他输入分区的checkpoint barrier到来,这个过程称之为barrier 对齐,checkpoint barrier到来之前会把到来的数据线缓存起来。

- 图5,任务收齐了全部输入分区的checkpoint barrier之后,会通知状态后端开始生成checkpoint,同时会把checkpoint barrier广播至下游算子。

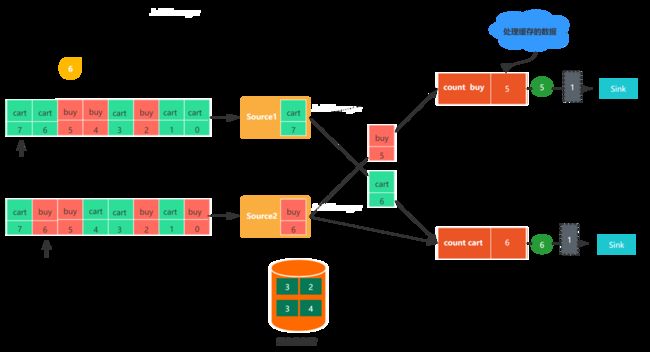
- 图6,任务在发出checkpoint barrier之后,开始处理因barrier对齐产生的缓存数据,在缓存的数据处理完之后,就会继续处理输入流数据。
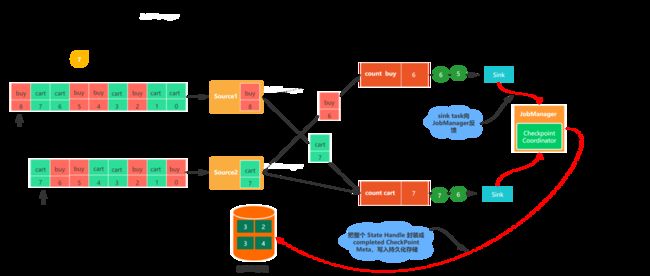
- 图7,最终checkpoint barrier会被传送到sink端,sink任务接收到checkpoint barrier之后,会向其他算子任务一样,将自身的状态写入checkpoint,之后向Job Manager发送确认消息。Job Manager接收到所有任务返回的确认消息之后,就会将此次检查点标记为完成。
使用案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// checkpoint的时间间隔,如果状态比较大,可以适当调大该值
env.enableCheckpointing(1000);
// 配置处理语义,默认是exactly-once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 两个checkpoint之间的最小时间间隔,防止因checkpoint时间过长,导致checkpoint积压
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// checkpoint执行的上限时间,如果超过该阈值,则会中断checkpoint
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 最大并行执行的检查点数量,默认为1,可以指定多个,从而同时出发多个checkpoint,提升效率
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 设定周期性外部检查点,将状态数据持久化到外部系统中,
// 使用该方式不会在任务正常停止的过程中清理掉检查点数据
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// allow job recovery fallback to checkpoint when there is a more recent savepoint
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
总结
本文首先从Flink的状态入手,通过Spark的WordCount和Flink的Work Count进行说明什么是状态。接着对状态的分类以及状态的使用进行了详细说明。然后对Flink提供的三种状态后端进行讨论,并给出了状态后端的使用说明。最后,以图解加文字的形式详细解释了Flink的checkpoint机制,并给出了使用Checkpoint时的程序配置。
- 关注公众号:大数据技术与数仓
- 免费领取百G大数据资料