高可用galera集群 mongo数据库基本操作增删减改查
1.MySQL高可用解决方案Galera Cluster 集群
MySQL Galera Cluster介绍
Galera Cluster不同于常规的MySQL Server软件,安装了额外的插件,也需要额外的配置
Galera Cluster要求最少3个节点,即3台MySQL服务器主机
Galera Cluster复制仅仅支持支持事务的InnoDB存储引擎
任何写入其他引擎的表, 包括mysql.*表 将不会复制,但是DDL语句会被复制的,因此创建用户将会被复制,但是insert into mysql.user…将不会被复制的
DELETE操作不支持没有主键的表
整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件。
Galera Cluster优势和适用场景
多节点写入和读取需求
数据库节点数据一致性要求高的业务
数据高可用性要求高的业务
2.案例: 安装配置Galera Cluster
| IP |
主机名 |
角色 |
操作系统(最小安装) |
MySQL |
| 192.168.20.11 |
host21 |
主库 |
Centos 7 |
Galera Cluster for MySQL 5.7.2x rpm包安装版 |
| 192.168.20.12 |
host22 |
主库 |
Centos 7 |
Galera Cluster for MySQL 5.7.2x rpm包安装版 |
| 192.168.20.13 |
host23 |
主库 |
Centos 7 |
Galera Cluster for MySQL 5.7.2x rpm包安装版 |
1.安装前准备 关闭selinux 和防火墙 上传安装包
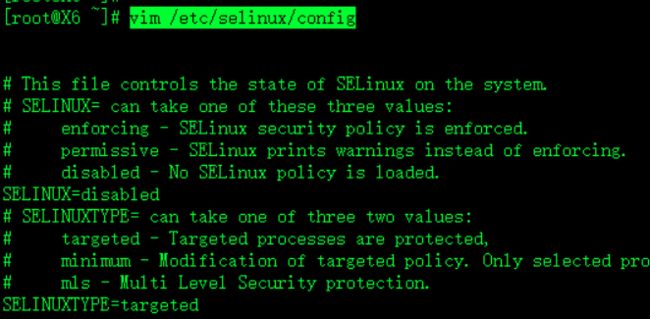
关闭selinux
vim /etc/selinux/config
关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
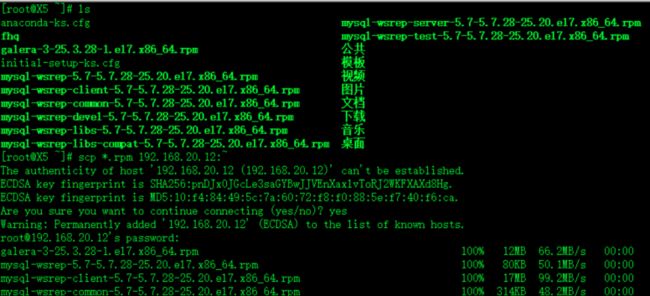
每个节点上传Galera Cluster for MySQL rpm包 8个
scp *.rpm 192.168.20.12:~上传到一个机器 然后发送到其他机器上即可
galera-3-25.3.24-2.el7.x86_64.rpm
mysql-wsrep-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-common-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-client-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-libs-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-libs-compat-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-server-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-test-5.7-5.7.28-25.20.el7.x86_64.rpm 测试用的 可删除
2.yum安装 每个节点的rpm软件包
rm -rf mysql-wsrep-test-5.7-5.7.28-25.20.el7.x86_64.rpm 这个是测试文件 test 可删除
yum -y install *.rpm安装上传的安装包
yum install rsync
yum install galera-3-25.3.24-2.el7.x86_64.rpm
yum install mysql-wsrep-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-client-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-common-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-libs-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-libs-compat-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-server-5.7-5.7.23-25.15.el7.x86_64.rpm

先去配置节点 node 在 启动mysqld服务 注意顺序
3.配置第一个节点NODE1
vim /etc/my.cnf#添加以下内容
[mysqld]
user=mysql
binlog_format=ROW#日志格式
bind-address=0.0.0.0#不限制ip,可在然后ip上使用
default_storage_engine=innodb#缺省的存储引擎,可不加
innodb_autoinc_lock_mode=2#必须改 为2 缺省情况下为1
innodb_flush_log_at_trx_commit=0#节点
innodb_buffer_pool_size=122M#innodb 缓存大小
wsrep_provider=/usr/lib64/galera-3/libgalera_smm.so#指的是提供的动态库
wsrep_provider_options="gcache.size=300M; gcache.page_size=300M"#提供的选项 必须的 整数倍关系
wsrep_cluster_name="test-cluster"#集群名称
wsrep_cluster_address="gcomm://192.168.20.11,192.168.20.12,192.168.20.13"#集群 节点 的ip地址(最少三个)
wsrep_sst_method=rsync#传输机制 软件
wsrep_node_name=node1#节点的名字
wsrep_node_address="192.168.20.11"#节点 IP地址


查看是否存在
初始化mysql 获取临时密码 启动服务 更改密码
/usr/bin/mysqld_bootstrap初始化服务
cat /var/log/mysqld.log | grep temporary获取临时密码
mysql -uroot -p 登录mysql
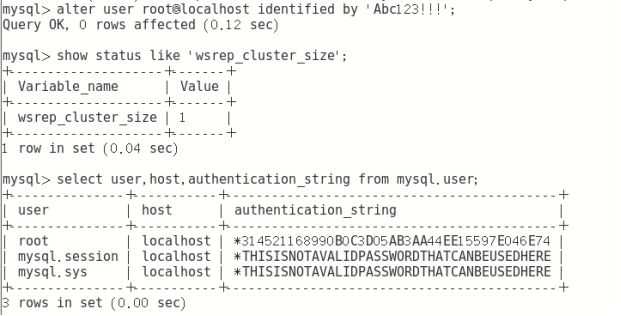
alter user root@localhost identified by 'Abc123!!!';修改密码

查看集群状态变量
show status like 'wsrep_cluster_size';查看节点
select user,host,authentication_string from mysql.user;
查看端口

4.配置第二个节点NODE2
vim /etc/my.cnf#添加以下内容
[mysqld]
user=mysql
binlog_format=ROW
bind-address=0.0.0.0
default_storage_engine=innodb
innodb_autoinc_lock_mode=2
innodb_flush_log_at_trx_commit=0
innodb_buffer_pool_size=122M
wsrep_provider=/usr/lib64/galera-3/libgalera_smm.so
wsrep_provider_options="gcache.size=300M; gcache.page_size=300M"
wsrep_cluster_name="test-cluster"
wsrep_cluster_address="gcomm://192.168.20.11,192.168.20.12,192.168.20.13"
wsrep_sst_method=rsync
wsrep_node_name=node2
wsrep_node_address="192.168.20.12"
初始化mysql
systemctl start mysqld 拷贝第一个节点的东西
登录mysql
密码 为节点1密 码 Abc123!!!
mysql -uroot -p
查看集群状态变量 第一个机器
show status like 'wsrep_cluster_size';查看集群
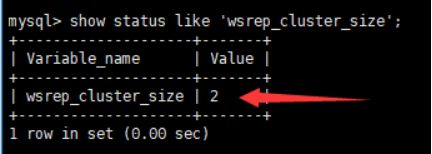
select user,host,authentication_string from mysql.user;查看mysql 用户
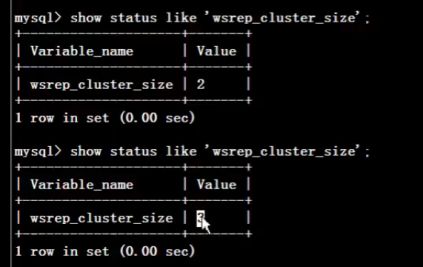
5.配置第三个节点NODE3
vim /etc/my.cnf#添加以下内容
[mysqld]
user=mysql
binlog_format=ROW
bind-address=0.0.0.0
default_storage_engine=innodb
innodb_autoinc_lock_mode=2
innodb_flush_log_at_trx_commit=0
innodb_buffer_pool_size=122M
wsrep_provider=/usr/lib64/galera-3/libgalera_smm.so
wsrep_provider_options="gcache.size=300M; gcache.page_size=300M"
wsrep_cluster_name="test-cluster"
wsrep_cluster_address="gcomm://192.168.20.11,192.168.20.12,192.168.20.13"
wsrep_sst_method=rsync
wsrep_node_name=node3
wsrep_node_address="192.168.20.13"
初始化mysql
systemctl start mysqld
测试登录mysql
密码为节点1密码Abc123!
mysql -uroot -p
查看集群状态变量
show status like 'wsrep_cluster_size';
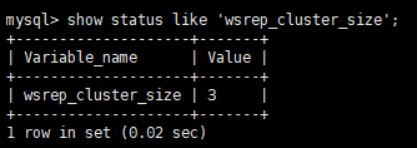
select user,host,authentication_string from mysql.user;
6.测试 多主复制 数据库
任意节点操作:
mysql> source /root/world.sql上传world.sql到/root
其他节点查看:
mysql> show databases;
mysql> use world;
mysql> show tables;
mysql> select * from country;
7.开启和 关闭集群 先开启节点 再启动服务
systemctl stop mysqld每个节点
开启集群
第一个节点(11或12或13):
/usr/bin/mysqld_bootstrap必须用这个命令启动第一个节点
其余节点:
systemctl start mysqld
8.假如 启动报错处理 方法
先关闭实例:
systemctl stop mysqld关闭服务
rm /var/lib/mysql/grastate.dat删除故障节点/var/lib/mysql/grastate.dat删除这个文件

注意:如果启动第一个节点使用 /usr/bin/mysqld_bootstrap (官方文档说明:针对Centos7 和 galera mysql5.7)
3.MongoDB 的简介 和使用场景 优点与弊端
1.MongoDB简介
MongoDB是由10gen公司(现已改名为MongoDB Inc.)用C++语言研发的一款数据库,于2009年开源
MongoDB按照类似于JSON的格式存储数据,称作BSON (binary json),由成对的field和value构成,value除了数值和字符之外也可以包括数组([ ]),其他文档等

每一条数据称作一个文档(document)
相对传统关系型数据库,文档之间可以有不一样的格式(字段field),因此更加灵活
可以为数据创建索引,使用特定查询方式来分析统计数据
MongoDB开源免费,遵从GNU GPL协定
2.MongoDB使用的业务场景
适用于: 没有结构化的数据
1.存储表结构不确定或经常变换的业务数据
2.数据量很大,但价值较低的数据
3.数据实时性要求高的数据,MongoDB批量插入性能非常高(并发量)
不适用于:
对事务要求高的业务;和传统关系型数据库比较,MongoDB对事务的支持较差
需要使用SQL的业务场景
4.CentOS7安装MongoDB社区版rpm包 联网下载或者上传安装包
1.关闭selinux关闭防火墙 上传安装包 或者 配置yum下载
vim /etc/selinux/config关闭selinux

或者配置yum源 下载安装mongodb
vi /etc/yum.repos.d/mongodb-org-4.0.repo#添加以下内容 联网下载
[mongodb-org-4.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.0/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc
2.安装MongoDB软件包 配置文件路径 日志 数据 参数文件
yum install -y mongodb-org
初始化配置(rpm包安装)
/etc/mongod.conf参数文件位置
/var/lib/mongo数据文件位置
/var/log/mongodb/mongod.log默认日志文件位置
3.允许远程连接
vim /etc/mongod.conf
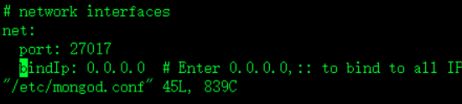
默认为本机登录 可以修改为0.0.0.0 或者指定网段
systemctl restart mongod重启服务
systemctl stop mongod关闭mongodb服务
systemctl start mongod启动数据库
4.使用MongoShell连接MongoDB
mongo --host 127.0.0.1:27017本地连接 27017为端口号
或
mongo

退出MongoDB客户端:
>quit()
或
>exit;

5.MongoDB术语 与 传统数据库 对照
| 传统RDBMS (MySQL) |
MongoDB术语 |
说明 |
| DATABASE |
DATABASE |
数据库 |
| TABLE |
COLLECTION |
表/集合 |
| ROW |
DOCUMENT |
行/文档 |
| COLUMN |
FIELD |
列(字段)/ 字段(域) |
| INDEX |
INDEX |
索引 |
| TABLE JOIN |
|
连接运算;MongoDB不支持集合间连接运算 |
| PRIMARY KEY |
PRIMARY KEY |
主键,MongoDB默认使用_id field作为主键,如果文档中没有指定_id会自动创建 |
MongoDB中一个数据库包含多个集合(类似于关系型数据中的表)
MongoDB中一个集合包含多个文档,文档以BSON格式存储数据
6.MongoDB数据库 与集合 管理命令 创建删除 查看
1.查看所有数据库: show dbs
Mongo
> show dbs;
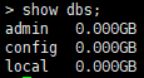
2.创建新数据库newdb:隐形创建数据库格式
>use newdb; newdb不存在
>db; 查看当前所在数据库
>db.myCollection.insertOne( { x: 1 } ); 创建新数据库,其下创建一个叫做myCollection的集合即可
> show dbs;
> use newdb;
> show collections;
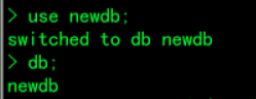

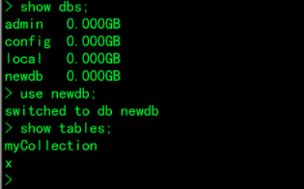
3.创建新数据库newdb1:隐形创建数据库
> use newdb1;
> db;显示当前数据库
> db.x.insertOne({name:"zhangsan"});数据库newdb1 集合为x 创建张三的文档
> show collections;
> db.x.find();查看x集合 的文档 的字段
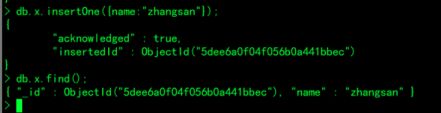
4.创建数据库总结:
切换到 一个不存在的数据库
往数据库中 存入数据,产生一个集合 包含一个文档
数据库创建成功
例如:
use test
db.c1.insertOne( { x: 1 } )
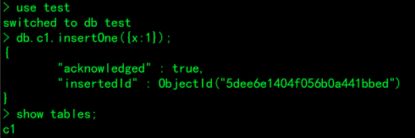
show tables;查看集合(表)
db.c1.find()查看表c1的内容
insertOne() 语句创建test数据库 和c1集合(表)
5.使用数据库: 查看当前数据库 删除集合(表) 和数据库
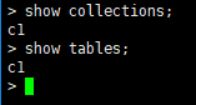
>use test;查看当前使用数据库
> db;
>show collections;查看当前数据库有哪些集合
或
>show tables;
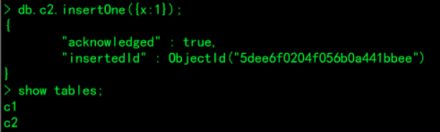
1.隐式创建集合:如果第一次向一个不存在的集合中存储数据,就会创建一个集合
> use test;
> db;
> db.c2.insertOne({x:1});
> show collections;
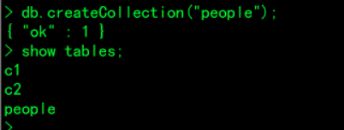
2.明确创建集合(表)
> db.createCollection("people");创建集合
> show tables;查看集合
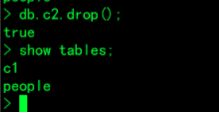
3.删除集合(表):
> db.c2.drop();删除c2表
> show collections;
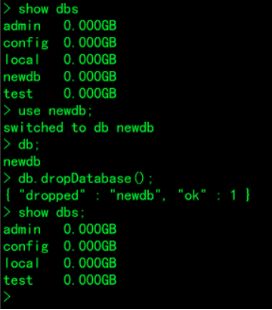
4.删除数据库newdb1: 进去数据库 在删除数据库
> show dbs;
> use newdb1;
> db;
> db.dropDatabase();
> show dbs;
7.MongoDB增删改查 操作 相关命令
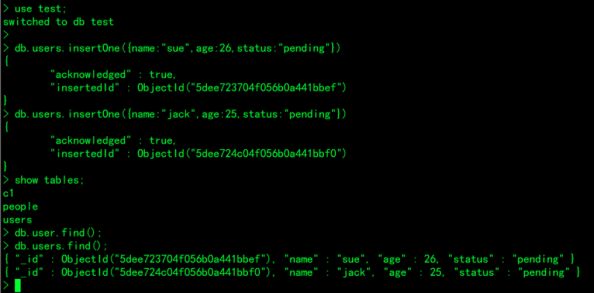
1.test数据库的 users集合中 插入一个文档:
insertOne 插入一行文档

> use test;
> db.users.insertOne(
{
name:"sue",数值类型不用加双引号
age:26,
status:"pending"
}
)
> db.users.insertOne(
{
name:"jack",
age:25,
status:"pending"
}
)
db.users.find();查看users集合(表)的内容
2.查看 users集合(表)中的 内容:相当于 select * from users;
> db.users.find();

3.查看 users集合(表)中的 指定field字段内容 只显示field name和age
> db.users.find({},{name:1,age:1});前面有空的大括号所有文档符合条件 后面的值为非0 0表示不显示

4.查询users集合中的所有文档指定过滤条件age大于等于26:
> db.users.find({age:{$gte:26}})gte大于等于

5.查询users集合中的所有文档指定过滤条件age大于等于26,仅显示name和age: limit指定显示几行
> db.users.find({age:{$gte:26}},{name:1,age:1})


Find 前面是条件 后面是查找的字段 limit表示显示文档数量
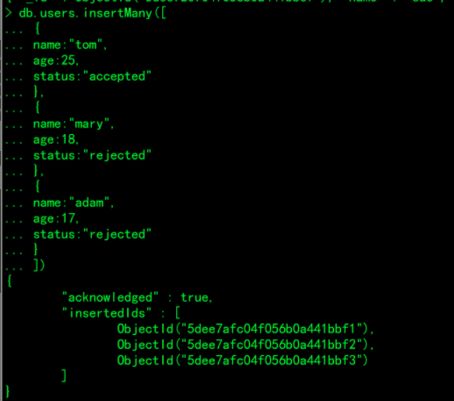
6.test数据库的users集合中插入多个文档:
db.users.insertMany([
{
name:"tom",
age:25,
status:"accepted"
},
{
name:"mary",
age:18,
status:"rejected"
},
{
name:"adam",
age:17,
status:"rejected"
}
])
> db.users.find();

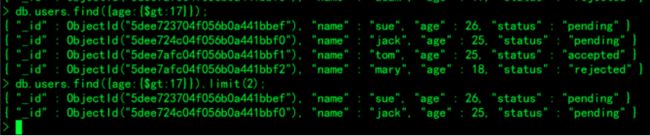
db.users.find({age:{$gt:17}});
db.users.find({age:{$gt:17}}).limit(2);
7.test数据库users集合更新文档内容:
修改 姓名为adam的年龄为27岁:limit修改文档中的几个
> db.users.updateOne({name:"adam"},{$set:{age:27}})
> db.users.find({name:"adam"})
![]()
![]()
db.users.updateOne({status:"rejected"},{$set:{age:22}}) 修改status为rejected 年龄改为22

db.users.updateMany({status:"rejected"},{$set:{age:20}})将status为rejected的 所有年龄改为10
db.users.find()

修改所有人的status为“rejected”
> db.users.updateMany({},{$set:{status:"rejected"}})
> db.users.find()
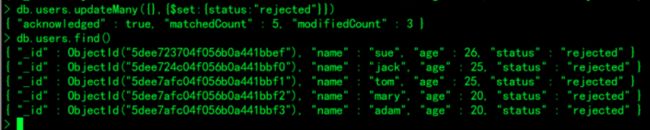
修改年龄大于20岁的人的status为“accepted”
> db.users.updateMany({"age":{$gte:20}},{$set:{status:"accepted"}})
> db.users.find()

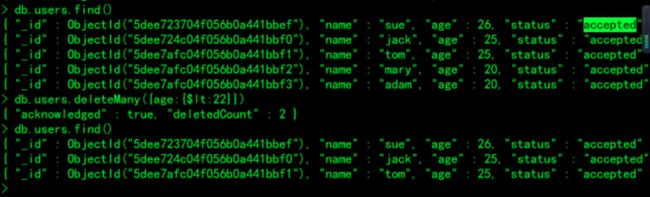
8.test数据库users集合删除指定文档:
删除年龄小于20岁的人
> db.users.deleteMany({age:{$lt:20}})
> db.users.find()
db.users.deleteMany({name:"tom"})
db.users.find()
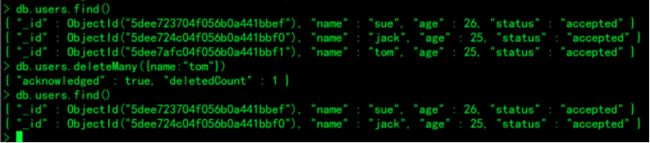
删除users集合中的所有文档
> db.users.deleteMany({})

8.常用比较运算符
| 运算符 |
说明 |
| $eq |
等于指定值 |
| $gt |
大于指定值 |
| $gte |
大于等于指定值 |
| $in |
in 指定的数组的值列表中 |
| $lt |
小于指定的值 |
| $lte |
小于指定的值 |
| $ne |
不等于指定的值 |
| $nin |
not in 指定的数组的值列表中 |
举例 增加案例users表
>db.users.insertMany( [ { name:"sue", age:20, status:"pending" }, { name:"jack", age:25, status:"accepted" }, { name:"tom", age:30, status:"accepted" }, { name:"mary", age:18, status:"rejected" }, { name:"adam", age:17, status:"rejected" }, { name:"use", age:20, status:"pending" }, { name:"jack", age:25, status:"accepted" } ])
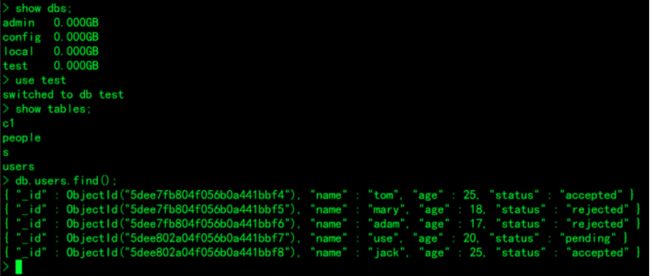
年龄等于20岁,显示姓名和年龄:
> db.users.find({age:{$eq:20}},{name:1,age:1});
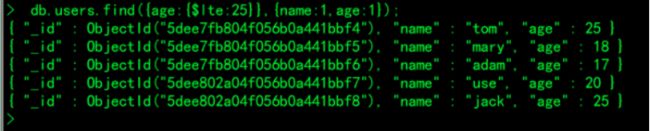
年龄小于等于25岁,显示姓名和年龄:
> db.users.find({age:{$lte:25}},{name:1,age:1});
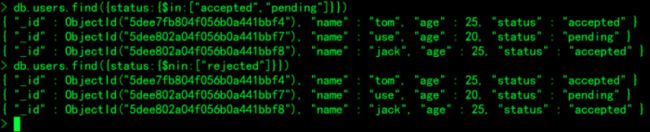
状态为”pending”或”accepted”:
> db.users.find({status:{$in:["accepted","pending"]}})
状态不为”rejected”:
> db.users.find({status:{$nin:["rejected"]}})
9.常用逻辑运算符
| 运算符 |
说明 |
| $and |
与运算符; { $and: [ { |
| $not |
非运算符;{ field: { $not: { |
| $or |
或运算符;{ $or: [ { |
举例
年龄在20和30岁之间的文档:
> db.users.find({$and:[{age:{$gte:20}},{age:{$lte:30}}]})

状态为“rejected”或者年龄小于等于20岁的文档:
> db.users.find({$or:[{status:"rejected"},{age:{$lte:20}}]})

状态不是“rejected”的文档:
> db.users.find({status:{$not:{$eq:"rejected"}}})

10.MongoDB变更文档结构
传统关系型数据库使用DDL语句变更表结构,MongoDB使用update(updateOne()或updateMany())方法变更文档结构
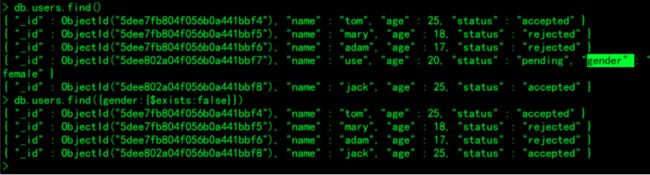
1.为“use”添加gender(性别) field,值为“female”
> db.users.find();

db.users.updateOne({name:"use"},{$set:{gender:"female"}})


2.查找不包括“gender”field的文档:
> db.users.find({gender:{$exists:false}})
3.给不包含“gender”的文档添加字段,默认值为“”
> db.users.updateMany({gender:{$exists:false}},{$set:{gender:""}})
> db.users.find();
> db.users.find({gender:{$eq:""}});

4.设置jack和tom的gender为“male”
> db.users.updateMany({name:{$in:["jack","tom"]}},{$set:{gender:"male"}})
> db.users.find({name:{$in:["jack","tom"]}})

5.去掉gender为空字符串的文档的gender列
> db.users.updateMany({gender:{$eq:""}},{$unset:{gender:""}})
> db.users.find();


6.分组统计
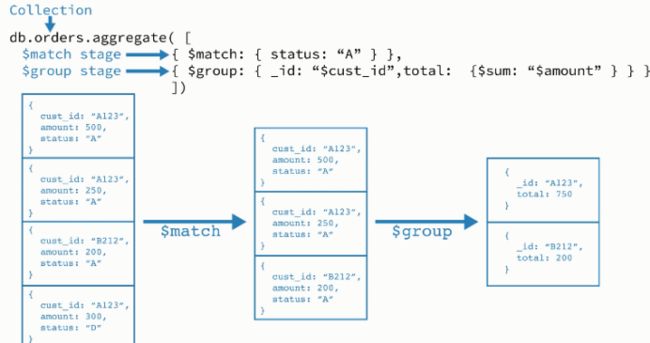
navicat导入stu.json到test集合
下一步下一步 然后开始导入 关闭即可
查看表
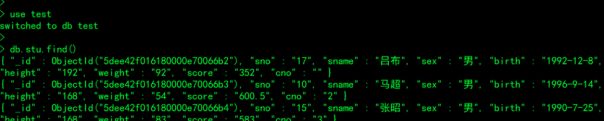
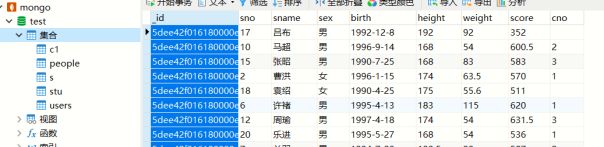
db.stu.find({},{_id:0})去掉id字段查看

#不分组,统计最高分
db.stu.aggregate([{$match:{}},{$group:{ _id:"",maxscore:{$max:"$score"}}}])
或者改为最高分 更清楚
db.stu.aggregate([{$match:{}},{$group:{ _id:"",最高分:{$max:"$score"}}}])

或者
db.stu.aggregate([{$match:{}},{$group:{ _id:"",maxscore:{$max:"$score"}}},{$project:{maxscore:1,_id:0}}])progect显示需要的结果
![]()
#按照cno分组,统计最高分 去掉空值
db.stu.aggregate([{$match:{}},{$group:{ _id:"$cno",maxscore:{$max:"$score"}}}])

#去掉cno=""的,再按照cno分组,统计最高分
db.stu.aggregate([{$match:{cno:{$ne:""}}},{$group:{ _id:"$cno",maxscore:{$max:"$score"}}}])

#统计1班,男女生人数
db.stu.aggregate([{$match:{cno:"1"}},{$group:{_id:"$sex",cnt:{$sum:1}}}]);

#统计每个班人数
db.stu.aggregate([{$match:{cno:{$ne:0}}},{$group:{_id:"$cno",zcnt:{$sum:1}}}])

#统计每个班人数,按照分组列排序
db.stu.aggregate([{$match:{cno:{$ne:0}}},{$group:{_id:"$cno",cnt:{$sum:1}}},{$sort:{_id:1}}])

#统计人数超过5人的班
db.stu.aggregate([{$match:{cno:{$ne:0}}},{$group:{_id:"$cno",cnt:{$sum:1}}},{$match:{cnt:{$gt:5}}}])

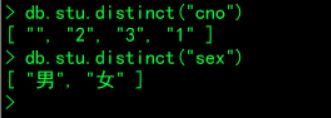
7.去重
db.stu.distinct("cno")
db.stu.distinct("sex")
高可用galera集群 mongo数据库基本操作增删减改查
1.MySQL高可用解决方案Galera Cluster 集群
MySQL Galera Cluster介绍
Galera Cluster不同于常规的MySQL Server软件,安装了额外的插件,也需要额外的配置
Galera Cluster要求最少3个节点,即3台MySQL服务器主机
Galera Cluster复制仅仅支持支持事务的InnoDB存储引擎
任何写入其他引擎的表, 包括mysql.*表 将不会复制,但是DDL语句会被复制的,因此创建用户将会被复制,但是insert into mysql.user…将不会被复制的
DELETE操作不支持没有主键的表
整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件。
Galera Cluster优势和适用场景
多节点写入和读取需求
数据库节点数据一致性要求高的业务
数据高可用性要求高的业务
2.案例: 安装配置Galera Cluster
| IP |
主机名 |
角色 |
操作系统(最小安装) |
MySQL |
| 192.168.20.11 |
host21 |
主库 |
Centos 7 |
Galera Cluster for MySQL 5.7.2x rpm包安装版 |
| 192.168.20.12 |
host22 |
主库 |
Centos 7 |
Galera Cluster for MySQL 5.7.2x rpm包安装版 |
| 192.168.20.13 |
host23 |
主库 |
Centos 7 |
Galera Cluster for MySQL 5.7.2x rpm包安装版 |
1.安装前准备 关闭selinux 和防火墙 上传安装包
关闭selinux
vim /etc/selinux/config
关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
每个节点上传Galera Cluster for MySQL rpm包 8个
scp *.rpm 192.168.20.12:~上传到一个机器 然后发送到其他机器上即可
galera-3-25.3.24-2.el7.x86_64.rpm
mysql-wsrep-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-common-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-client-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-libs-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-libs-compat-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-server-5.7-5.7.23-25.15.el7.x86_64.rpm
mysql-wsrep-test-5.7-5.7.28-25.20.el7.x86_64.rpm 测试用的 可删除
2.yum安装 每个节点的rpm软件包
rm -rf mysql-wsrep-test-5.7-5.7.28-25.20.el7.x86_64.rpm 这个是测试文件 test 可删除
yum -y install *.rpm安装上传的安装包
yum install rsync
yum install galera-3-25.3.24-2.el7.x86_64.rpm
yum install mysql-wsrep-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-client-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-common-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-libs-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-libs-compat-5.7-5.7.23-25.15.el7.x86_64.rpm mysql-wsrep-server-5.7-5.7.23-25.15.el7.x86_64.rpm
先去配置节点 node 在 启动mysqld服务 注意顺序
3.配置第一个节点NODE1
vim /etc/my.cnf#添加以下内容
[mysqld]
user=mysql
binlog_format=ROW#日志格式
bind-address=0.0.0.0#不限制ip,可在然后ip上使用
default_storage_engine=innodb#缺省的存储引擎,可不加
innodb_autoinc_lock_mode=2#必须改 为2 缺省情况下为1
innodb_flush_log_at_trx_commit=0#节点
innodb_buffer_pool_size=122M#innodb 缓存大小
wsrep_provider=/usr/lib64/galera-3/libgalera_smm.so#指的是提供的动态库
wsrep_provider_options="gcache.size=300M; gcache.page_size=300M"#提供的选项 必须的 整数倍关系
wsrep_cluster_name="test-cluster"#集群名称
wsrep_cluster_address="gcomm://192.168.20.11,192.168.20.12,192.168.20.13"#集群 节点 的ip地址(最少三个)
wsrep_sst_method=rsync#传输机制 软件
wsrep_node_name=node1#节点的名字
wsrep_node_address="192.168.20.11"#节点 IP地址
查看是否存在
初始化mysql 获取临时密码 启动服务 更改密码
/usr/bin/mysqld_bootstrap初始化服务
cat /var/log/mysqld.log | grep temporary获取临时密码
mysql -uroot -p 登录mysql
alter user root@localhost identified by 'Abc123!!!';修改密码
查看集群状态变量
show status like 'wsrep_cluster_size';查看节点
select user,host,authentication_string from mysql.user;
查看端口
4.配置第二个节点NODE2
vim /etc/my.cnf#添加以下内容
[mysqld]
user=mysql
binlog_format=ROW
bind-address=0.0.0.0
default_storage_engine=innodb
innodb_autoinc_lock_mode=2
innodb_flush_log_at_trx_commit=0
innodb_buffer_pool_size=122M
wsrep_provider=/usr/lib64/galera-3/libgalera_smm.so
wsrep_provider_options="gcache.size=300M; gcache.page_size=300M"
wsrep_cluster_name="test-cluster"
wsrep_cluster_address="gcomm://192.168.20.11,192.168.20.12,192.168.20.13"
wsrep_sst_method=rsync
wsrep_node_name=node2
wsrep_node_address="192.168.20.12"
初始化mysql
systemctl start mysqld 拷贝第一个节点的东西
登录mysql
密码 为节点1密 码 Abc123!!!
mysql -uroot -p
查看集群状态变量 第一个机器
show status like 'wsrep_cluster_size';查看集群
select user,host,authentication_string from mysql.user;查看mysql 用户
5.配置第三个节点NODE3
vim /etc/my.cnf#添加以下内容
[mysqld]
user=mysql
binlog_format=ROW
bind-address=0.0.0.0
default_storage_engine=innodb
innodb_autoinc_lock_mode=2
innodb_flush_log_at_trx_commit=0
innodb_buffer_pool_size=122M
wsrep_provider=/usr/lib64/galera-3/libgalera_smm.so
wsrep_provider_options="gcache.size=300M; gcache.page_size=300M"
wsrep_cluster_name="test-cluster"
wsrep_cluster_address="gcomm://192.168.20.11,192.168.20.12,192.168.20.13"
wsrep_sst_method=rsync
wsrep_node_name=node3
wsrep_node_address="192.168.20.13"
初始化mysql
systemctl start mysqld
测试登录mysql
密码为节点1密码Abc123!
mysql -uroot -p
查看集群状态变量
show status like 'wsrep_cluster_size';
select user,host,authentication_string from mysql.user;
6.测试 多主复制 数据库
任意节点操作:
mysql> source /root/world.sql上传world.sql到/root
其他节点查看:
mysql> show databases;
mysql> use world;
mysql> show tables;
mysql> select * from country;
7.开启和 关闭集群 先开启节点 再启动服务
systemctl stop mysqld每个节点
开启集群
第一个节点(11或12或13):
/usr/bin/mysqld_bootstrap必须用这个命令启动第一个节点
其余节点:
systemctl start mysqld
8.假如 启动报错处理 方法
先关闭实例:
systemctl stop mysqld关闭服务
rm /var/lib/mysql/grastate.dat删除故障节点/var/lib/mysql/grastate.dat删除这个文件
注意:如果启动第一个节点使用 /usr/bin/mysqld_bootstrap (官方文档说明:针对Centos7 和 galera mysql5.7)
3.MongoDB 的简介 和使用场景 优点与弊端
1.MongoDB简介
MongoDB是由10gen公司(现已改名为MongoDB Inc.)用C++语言研发的一款数据库,于2009年开源
MongoDB按照类似于JSON的格式存储数据,称作BSON (binary json),由成对的field和value构成,value除了数值和字符之外也可以包括数组([ ]),其他文档等
每一条数据称作一个文档(document)
相对传统关系型数据库,文档之间可以有不一样的格式(字段field),因此更加灵活
可以为数据创建索引,使用特定查询方式来分析统计数据
MongoDB开源免费,遵从GNU GPL协定
2.MongoDB使用的业务场景
适用于: 没有结构化的数据
1.存储表结构不确定或经常变换的业务数据
2.数据量很大,但价值较低的数据
3.数据实时性要求高的数据,MongoDB批量插入性能非常高(并发量)
不适用于:
对事务要求高的业务;和传统关系型数据库比较,MongoDB对事务的支持较差
需要使用SQL的业务场景
4.CentOS7安装MongoDB社区版rpm包 联网下载或者上传安装包
1.关闭selinux关闭防火墙 上传安装包 或者 配置yum下载
vim /etc/selinux/config关闭selinux
或者配置yum源 下载安装mongodb
vi /etc/yum.repos.d/mongodb-org-4.0.repo#添加以下内容 联网下载
[mongodb-org-4.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.0/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc
2.安装MongoDB软件包 配置文件路径 日志 数据 参数文件
yum install -y mongodb-org
初始化配置(rpm包安装)
/etc/mongod.conf参数文件位置
/var/lib/mongo数据文件位置
/var/log/mongodb/mongod.log默认日志文件位置
3.允许远程连接
vim /etc/mongod.conf
默认为本机登录 可以修改为0.0.0.0 或者指定网段
systemctl restart mongod重启服务
systemctl stop mongod关闭mongodb服务
systemctl start mongod启动数据库
4.使用MongoShell连接MongoDB
mongo --host 127.0.0.1:27017本地连接 27017为端口号
或
mongo
退出MongoDB客户端:
>quit()
或
>exit;
5.MongoDB术语 与 传统数据库 对照
| 传统RDBMS (MySQL) |
MongoDB术语 |
说明 |
| DATABASE |
DATABASE |
数据库 |
| TABLE |
COLLECTION |
表/集合 |
| ROW |
DOCUMENT |
行/文档 |
| COLUMN |
FIELD |
列(字段)/ 字段(域) |
| INDEX |
INDEX |
索引 |
| TABLE JOIN |
|
连接运算;MongoDB不支持集合间连接运算 |
| PRIMARY KEY |
PRIMARY KEY |
主键,MongoDB默认使用_id field作为主键,如果文档中没有指定_id会自动创建 |
MongoDB中一个数据库包含多个集合(类似于关系型数据中的表)
MongoDB中一个集合包含多个文档,文档以BSON格式存储数据
6.MongoDB数据库 与集合 管理命令 创建删除 查看
1.查看所有数据库: show dbs
Mongo
> show dbs;
2.创建新数据库newdb:隐形创建数据库格式
>use newdb; newdb不存在
>db; 查看当前所在数据库
>db.myCollection.insertOne( { x: 1 } ); 创建新数据库,其下创建一个叫做myCollection的集合即可
> show dbs;
> use newdb;
> show collections;
3.创建新数据库newdb1:隐形创建数据库
> use newdb1;
> db;显示当前数据库
> db.x.insertOne({name:"zhangsan"});数据库newdb1 集合为x 创建张三的文档
> show collections;
> db.x.find();查看x集合 的文档 的字段
4.创建数据库总结:
切换到 一个不存在的数据库
往数据库中 存入数据,产生一个集合 包含一个文档
数据库创建成功
例如:
use test
db.c1.insertOne( { x: 1 } )
show tables;查看集合(表)
db.c1.find()查看表c1的内容
insertOne() 语句创建test数据库 和c1集合(表)
5.使用数据库: 查看当前数据库 删除集合(表) 和数据库
>use test;查看当前使用数据库
> db;
>show collections;查看当前数据库有哪些集合
或
>show tables;
1.隐式创建集合:如果第一次向一个不存在的集合中存储数据,就会创建一个集合
> use test;
> db;
> db.c2.insertOne({x:1});
> show collections;
2.明确创建集合(表)
> db.createCollection("people");创建集合
> show tables;查看集合
3.删除集合(表):
> db.c2.drop();删除c2表
> show collections;
4.删除数据库newdb1: 进去数据库 在删除数据库
> show dbs;
> use newdb1;
> db;
> db.dropDatabase();
> show dbs;
7.MongoDB增删改查 操作 相关命令
1.test数据库的 users集合中 插入一个文档:
insertOne 插入一行文档
> use test;
> db.users.insertOne(
{
name:"sue",数值类型不用加双引号
age:26,
status:"pending"
}
)
> db.users.insertOne(
{
name:"jack",
age:25,
status:"pending"
}
)
db.users.find();查看users集合(表)的内容
2.查看 users集合(表)中的 内容:相当于 select * from users;
> db.users.find();
3.查看 users集合(表)中的 指定field字段内容 只显示field name和age
> db.users.find({},{name:1,age:1});前面有空的大括号所有文档符合条件 后面的值为非0 0表示不显示
4.查询users集合中的所有文档指定过滤条件age大于等于26:
> db.users.find({age:{$gte:26}})gte大于等于
5.查询users集合中的所有文档指定过滤条件age大于等于26,仅显示name和age: limit指定显示几行
> db.users.find({age:{$gte:26}},{name:1,age:1})
Find 前面是条件 后面是查找的字段 limit表示显示文档数量
6.test数据库的users集合中插入多个文档:
db.users.insertMany([
{
name:"tom",
age:25,
status:"accepted"
},
{
name:"mary",
age:18,
status:"rejected"
},
{
name:"adam",
age:17,
status:"rejected"
}
])
> db.users.find();
db.users.find({age:{$gt:17}});
db.users.find({age:{$gt:17}}).limit(2);
7.test数据库users集合更新文档内容:
修改 姓名为adam的年龄为27岁:limit修改文档中的几个
> db.users.updateOne({name:"adam"},{$set:{age:27}})
> db.users.find({name:"adam"})
db.users.updateOne({status:"rejected"},{$set:{age:22}}) 修改status为rejected 年龄改为22
db.users.updateMany({status:"rejected"},{$set:{age:20}})将status为rejected的 所有年龄改为10
db.users.find()
修改所有人的status为“rejected”
> db.users.updateMany({},{$set:{status:"rejected"}})
> db.users.find()
修改年龄大于20岁的人的status为“accepted”
> db.users.updateMany({"age":{$gte:20}},{$set:{status:"accepted"}})
> db.users.find()
8.test数据库users集合删除指定文档:
删除年龄小于20岁的人
> db.users.deleteMany({age:{$lt:20}})
> db.users.find()
db.users.deleteMany({name:"tom"})
db.users.find()
删除users集合中的所有文档
> db.users.deleteMany({})
8.常用比较运算符
| 运算符 |
说明 |
| $eq |
等于指定值 |
| $gt |
大于指定值 |
| $gte |
大于等于指定值 |
| $in |
in 指定的数组的值列表中 |
| $lt |
小于指定的值 |
| $lte |
小于指定的值 |
| $ne |
不等于指定的值 |
| $nin |
not in 指定的数组的值列表中 |
举例 增加案例users表
>db.users.insertMany( [ { name:"sue", age:20, status:"pending" }, { name:"jack", age:25, status:"accepted" }, { name:"tom", age:30, status:"accepted" }, { name:"mary", age:18, status:"rejected" }, { name:"adam", age:17, status:"rejected" }, { name:"use", age:20, status:"pending" }, { name:"jack", age:25, status:"accepted" } ])
年龄等于20岁,显示姓名和年龄:
> db.users.find({age:{$eq:20}},{name:1,age:1});
年龄小于等于25岁,显示姓名和年龄:
> db.users.find({age:{$lte:25}},{name:1,age:1});
状态为”pending”或”accepted”:
> db.users.find({status:{$in:["accepted","pending"]}})
状态不为”rejected”:
> db.users.find({status:{$nin:["rejected"]}})
9.常用逻辑运算符
| 运算符 |
说明 |
| $and |
与运算符; { $and: [ { |
| $not |
非运算符;{ field: { $not: { |
| $or |
或运算符;{ $or: [ { |
举例
年龄在20和30岁之间的文档:
> db.users.find({$and:[{age:{$gte:20}},{age:{$lte:30}}]})
状态为“rejected”或者年龄小于等于20岁的文档:
> db.users.find({$or:[{status:"rejected"},{age:{$lte:20}}]})
状态不是“rejected”的文档:
> db.users.find({status:{$not:{$eq:"rejected"}}})
10.MongoDB变更文档结构
传统关系型数据库使用DDL语句变更表结构,MongoDB使用update(updateOne()或updateMany())方法变更文档结构
1.为“use”添加gender(性别) field,值为“female”
> db.users.find();
db.users.updateOne({name:"use"},{$set:{gender:"female"}})
2.查找不包括“gender”field的文档:
> db.users.find({gender:{$exists:false}})
3.给不包含“gender”的文档添加字段,默认值为“”
> db.users.updateMany({gender:{$exists:false}},{$set:{gender:""}})
> db.users.find();
> db.users.find({gender:{$eq:""}});
4.设置jack和tom的gender为“male”
> db.users.updateMany({name:{$in:["jack","tom"]}},{$set:{gender:"male"}})
> db.users.find({name:{$in:["jack","tom"]}})
5.去掉gender为空字符串的文档的gender列
> db.users.updateMany({gender:{$eq:""}},{$unset:{gender:""}})
> db.users.find();
6.分组统计
navicat导入stu.json到test集合
下一步下一步 然后开始导入 关闭即可
查看表
db.stu.find({},{_id:0})去掉id字段查看
#不分组,统计最高分
db.stu.aggregate([{$match:{}},{$group:{ _id:"",maxscore:{$max:"$score"}}}])
或者改为最高分 更清楚
db.stu.aggregate([{$match:{}},{$group:{ _id:"",最高分:{$max:"$score"}}}])
或者
db.stu.aggregate([{$match:{}},{$group:{ _id:"",maxscore:{$max:"$score"}}},{$project:{maxscore:1,_id:0}}])progect显示需要的结果
#按照cno分组,统计最高分 去掉空值
db.stu.aggregate([{$match:{}},{$group:{ _id:"$cno",maxscore:{$max:"$score"}}}])
#去掉cno=""的,再按照cno分组,统计最高分
db.stu.aggregate([{$match:{cno:{$ne:""}}},{$group:{ _id:"$cno",maxscore:{$max:"$score"}}}])
#统计1班,男女生人数
db.stu.aggregate([{$match:{cno:"1"}},{$group:{_id:"$sex",cnt:{$sum:1}}}]);
#统计每个班人数
db.stu.aggregate([{$match:{cno:{$ne:0}}},{$group:{_id:"$cno",zcnt:{$sum:1}}}])
#统计每个班人数,按照分组列排序
db.stu.aggregate([{$match:{cno:{$ne:0}}},{$group:{_id:"$cno",cnt:{$sum:1}}},{$sort:{_id:1}}])
#统计人数超过5人的班
db.stu.aggregate([{$match:{cno:{$ne:0}}},{$group:{_id:"$cno",cnt:{$sum:1}}},{$match:{cnt:{$gt:5}}}])
7.去重
db.stu.distinct("cno")
db.stu.distinct("sex")