【JavaSE8 高级编程 集合框架】集合框架入门系列①框架概览 2019_8_29
Java 集合框架
- Java 集合框架
- 记忆简记(最后看)
- Collection体系【聚集,单一集合】
- Collection顶级接口
- List 子接口详解
- List接口总结
- Set 子接口详解
- Set接口总结
- Queue子接口详解
- Queue接口总结
- Deque子接口
- Deque接口总结
- Collection体系总结
- Map体系【映射,两集合关联】
- Map顶级接口
- Map成员接口Entry接口
- Map接口总结
- 集合框架总结
Java 集合框架
功能:用于存储数量不等的多个对象(Object[]),还可保存具有映射关系的两对象(Key-Value)
体系:Java 集合框架分为 Collection 和 Map 两种体系。
提问:为什么会有2种体系?
本质上是——混沌生一,一生二,二生三,三生万物。
一群对象,以规则聚/分类在一起——称呼为集合。
而集合与集合间又会出现2种情况——独立存在的单一集合,以及不独立存在相互关联的集合s。
这就是,上面说的,混沌生一,一生二。
从而在Java集合框架中的具体实现就是——Collection体系(顶级接口),Map体系(顶级接口)
记忆简记(最后看)
Collection【无·改函数】
5 4 2 2 2
删查增 转换 迭代器
删5:删单个,删交集,删差集,条件删,全删
查4:查对象,查交集,查空,查总数
增2:增单个,增聚集
转换2:数组Object[],T[]
迭代器2:普通Iterator,Spliterator
List(在Collection基础上增加概念,索引,顺序)
2 1 2 4 2 1
增删改查 迭代器 排序
增2:【索引】索引插单,索引插聚集
删1:【索引】索引删单
改2:【索引】索引改单,替换全部(UneryOperator)【独1】
查4:【索引】索引查单,前向后对象查索引,后向前对象查索引,获取SubList【独2】
迭代器2:listIterator(),listIterator(index)【list特适迭代器】
排序1:【顺序】sort
Queue(在Collection基础上增加概念,单向队列)
1 1 1 *2 = 6
尾增 首删 首查 抛出异常/返回特殊值
Collection体系【聚集,单一集合】
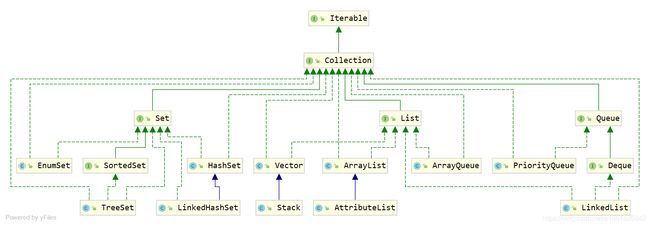
Collection顶级接口
Collection 接口是 List、Set 、Queue 接口的父接口,该接口定义的方法既可用于操作 Set 集合,也可用于 List 和 Queue。顺带一提这个几个接口的关系:
Collection【根基】聚集:基础函数的统一抽象 无序,集合
List【增强】列表:在Collection基础上扩展了 索引,顺序 这两个概念
Set【就是Collection】:继承Collection全部无扩展。无序 集合
Queue【特定顺序规则】:在Collection基础上扩展了 单向 队列 这两个概念
Deque【特定顺序规则】:在Collection+Queue基础上扩展了 双端 队列 单端 栈 这四个概念
Java 5 之后对Collection增加了泛型支持即——Java 聚集可以记住容器中对象的数据类型。
【本文为区分集合框架与Collection,简称Collection为 “聚集” ——物以类聚,同类物聚在一起的集合:聚集】
【List集合简称为:List或List集合,Set集合简称为:Set 或 Set集合,Queue集合简称为:队列】
| Collection | 功能 | 函数名 |
|---|---|---|
| 增*2 | +1 | boolean add(E e) |
| +1聚集 | boolean addAll(Collection c) | |
| 删*5 | -1 | boolean remove(Object obj) |
| -1聚集 | boolean removeAll(Collection coll) | |
| -x满足条件 | default boolean removeIf(Predicate filter) | |
| -x不在集合c | boolean retainAll(Collection c) | |
| 全部清空 | void clear() | |
| 查*4 | is null? | boolean isEmpty() |
| 包含某个? | boolean contains(Object obj) | |
| 包含聚集c? | boolean containsAll(Collection c) | |
| 获取聚集元素个数 | int size() | |
| 转换*2 | 转换为Object数组 | Object[] toArray() |
| 转换为T类型数组 | |
|
| 迭代器*2 | 获取普通迭代器 | Iterator |
| 获取可分割迭代器 | default Spliterator |
注1:contains通过元素的equals方法来判断是否 是同一个对象
注2:如果聚集内元素个数大于Integer.MAX,则返回Integer.MAX【最大容量也是IntergerMAX】
注3:Collection类 在 Java 8 新增的Stream流特性函数:
default Stream
返回以该集合为源的序列流。
default Spliterator
切割器,用于将大数据进行切割做成一个个短流,然后以多核并行处理流。
default Stream
返回一个可能并行的流,并将此集合作为其源。该方法允许返回顺序流。
注4:iterator.remove实例
Iterator iter = coll.iterator();//每获得迭代器,游标均是从0开始
while(iter.hasNext()){
Object obj = iter.next(); //调用next()(next()本身只能被调用一次)
if(obj.equals("Tom"))
iter.remove(); //调用remove()(在调用完next()后调用,也只可调用一次)
}
注5:Java 5 后新增 foreach循环迭代访问Collection类对象和数组对象,底层实现就是Iterator类。
List 子接口详解
Array数组存储数据的局限性:
数组在内存存储方面的特点:
数组初始化以后,长度就定死了。【不能动态扩展】
数组声明的类型,就决定了内部存储的元素类型。【单一】
数组存储的元素是有存放顺序的,且可重复的。【有序,可重复】
数组是对象,但是它太简陋了,只有Object父类方法【无复杂的功能方法(增删改查)】
鉴于Array本身的局限性,我们通常使用List来代替Array
List本质——是对Array的增强:
【有序可重复】,【只能存储单一类型的元素】,【可动态扩展】,【有复杂功能方法】
| List | 功能 | 函数名 |
|---|---|---|
| 增*4 | 末尾+1 | boolean add(E e) |
| 【新】 | 中插+1 | void add(int index, E element); |
| 末尾+x聚集 | boolean addAll(Collection c) | |
| 【新】 | 中插+x聚集 | boolean addAll(int index, Collection c) |
| 删*6 | 根据对象-1 | boolean remove(Object o) |
| 【新】 | 根据索引-1 | E remove(int index) |
| 根据聚集-x | boolean removeAll(Collection c) | |
| 满足条件-x | default boolean removeIf(Predicate filter) | |
| 不在聚集c-x | boolean retainAll(Collection c) | |
| 全部清空 | void clear() | |
| 改*2【新】 | 改指定索引元素 | E set(int index, E element) |
| 【新】 | 改每个元素但类型不变 | void replaceAll(UnaryOperator operator) |
| 查*8【新】 | 查指定索引的元素 | E get(int index) |
| 【新】 | 前查指定元素的索引 | int indexOf(Object o) |
| 【新】 | 后查指定元素的索引 | int lastIndexOf(Object o) |
| 【新】 | 获取 子List 聚集 | List |
| is null? | boolean isEmpty() | |
| 包含某个? | boolean contains(Object obj) | |
| 包含聚集c? | boolean containsAll(Collection c) | |
| 获取聚集元素个数 | int size() | |
| 迭代器*4 | 获取普通迭代器 | Iterator |
| 获取可分割迭代器 | default Spliterator |
|
| 【新】 | 获取有序list迭代器 | ListIterator |
| 【新】 | ~从指定索引处开始 | ListIterator |
| 转换*2 | 转换为Object数组 | Object[] toArray() |
| 转换为T类型数组 | |
|
| 排序*1 | 根据比较器排序 | default void sort(Comparator c) |
List接口总结
List接口很厉害,增加了很多新的方法——增函数+2【插入增】,删函数+1【索引减】,改函数+2【改单个、整体】,查询函数+4【索引查,前向、后向查索引,获取子List对象】,迭代器+2【有序list迭代器】
Set 子接口详解
| Collection | 功能 | 函数名 |
|---|---|---|
| 增*2 | +1 | boolean add(E e) |
| +1聚集 | boolean addAll(Collection c) | |
| 删*4 | -1 | boolean remove(Object obj) |
| -1聚集 | boolean removeAll(Collection coll) | |
| -x不在集合c | boolean retainAll(Collection c) | |
| 全部清空 | void clear() | |
| 查*4 | is null? | boolean isEmpty() |
| 包含某个? | boolean contains(Object obj) | |
| 包含聚集c? | boolean containsAll(Collection c) | |
| 获取聚集元素个数 | int size() | |
| 转换*2 | 转换为Object数组 | Object[] toArray() |
| 转换为T类型数组 | |
|
| 迭代器*2 | 获取普通迭代器 | Iterator |
| 获取可分割迭代器 | default Spliterator |
Set接口总结
Set集合,只要求不重复的极简Collection对象。【连存入顺序都不存储——不支持索引】
Queue子接口详解
Queue特点:【单向队列】【先进先出,尾进,首出】【无索引】【可扩展】
Queue接口是实现数据结构中队列这一概念的存在。队列=先进先出——队尾进(添加),队首出(删除)。
我们也可以简单的认为——Queue就是对元素进出做了特殊约束。Queue对象就是符合约束行为的一个聚集。
可以基于Array,Link数据结构实现。
除了基本的Collection接口操作外,Queue还提供额外的insertion, extraction, inspection操作。
增添,删除,检索操作都以两种形式存在:一种方法在操作失败时抛出异常,另一种方法返回一个特殊值(null或false)
插入操作的后一种形式专门用于容量受限的队列实现;在大多数实现中,插入操作不能失败(抛出异常)。
| Queue | 失败抛出异常 | 失败返回指定的值 | ||
|---|---|---|---|---|
| 增添 | boolean add(E e) | 增添队尾,队满异常 | boolean offer(E e) | 队满,false |
| 删除 | E remove() | 检索并删除队首,队空异常 | E poll() | 队空,null |
| 检索 | E element() | 检索队首,队空异常 | E peek() | 队空,null |
注1:此处做文字性规约,【增添】一般是指代——队尾/双向队首。而【插入】一般指代——中间插入/单端队首。
注2:Queue的聚集操作都是,具有镜像成对的特性。offer:提供,poll:剪断,peek:一瞥
Queue接口总结
Queue为单向队列,先进先出。队尾只进,队首只出,并且不对队列中间元素操作,描述拥有队列(生活中排队行为)行为的对象,不支持List集合中的索引概念。
Deque子接口
Deque特点:【双端队列】【首进出,尾进出】【无索引】【可扩展】

支持在两 / 双端插入和删除元素的线性集合。全称为:“double ended queue”。
支持有限容量,也可实现为无限容量。
| Deque | 失败 异常× | 失败 指定值√ | ||
|---|---|---|---|---|
| 双端函数 | 首出进,尾出进 | |||
| 增添首尾 | void addFirst(E e) | 首增,满异 | boolean offerFirst(E e) | 队满,false |
| void addLast(E e) | 尾增,满异 | boolean offerLast(E e) | 队满,false | |
| 删除首尾 | E removeFirst() | 首删,空异 | E pollFirst() | 队空,null |
| E removeLast() | 尾删,空异 | E pollLast() | 队空,null | |
| 检索首尾 | E getFirst() | 查首,空异 | E peekFirst() | 队空,null |
| E getLast() | 查尾,空异 | E peekLast() | 队空,null | |
| 单向队列 | 首出,尾进 | |||
| 增尾 | boolean add(E e) | 尾增,满异 | boolean offer(E e) | 队满,false |
| 删头 | E remove() | 首删,空异 | E poll() | 队空,null |
| 查头 | E element() | 查首,空异 | E peek() | 对空,null |
| 中间元素删除 | ||
|---|---|---|
| Collection | boolean remove(Object o) | 删除 first->last 第一次出现的o对象 |
| Deque | boolean removeFirstOccurrence(Object o) | 等价于上面的remove(Object o) |
| Deque | boolean removeLastOccurrence(Object o) | 删除 last->first 第一次出现的o对象 |
| 栈函数Stack | 完全等价Deque | |
|---|---|---|
| void push(E e) | void addFirst(E e) | |
| E pop() | E removeFirst() | |
| E peek() | E peekFirst() | |
| 栈顶增,删,查【数组竖立看】 | 队首增,删,查【数组横躺看】 |
Deque也可以用作后进先出,实现堆栈【单端队列】【栈顶进出】
注1:**Iterator descendingIterator()**是Deque特有的迭代器。也有普通迭代器Collection.Iterator()
注2:虽然Deque实现并不严格要求禁止插入null元素,但是强烈建议这样做。强烈建议使用任何允许空元素的Deque实现的用户不要利用插入空元素的能力。因为null被各种方法用作一个特殊的返回值来表示deque是空的。
Deque接口总结
虽然看起来,函数很多,但其实主要分为3个体系的函数。
①首先是Deque继承了单向队列Queue接口,也就是单向队列函数共计6个
(3类函数增删查,又可由返回值分为2组:抛异常组,返回false/null组——>3*2=6)
②其次是自身双端队列Deque接口函数,共计12个
(3类函数增删查,分别对2端队首,队尾操作,又可由返回值…分为2组:——>3*2*2=12)
③最后是单端栈实现,共计3个
(3类函数增删查——>3)
④你以为这就玩完了?不,还有我们的顶级接口Collection。哈哈哈我就不写了 。看上面
Collection体系总结
从接口设计上来看,Collection作为顶级接口,只是用于高级抽象,而底层抽象则是List Set Queue接口。
这三个接口下面就是具体的抽象类,在被抽象类实现了部分方法后,根据不同的现实使用情况进行实现类派生。
List是较为功能丰富复杂的聚集,而Set则是简约到极致的极简聚集。Queue就是被特殊规则约束了的聚集。
Map体系【映射,两集合关联】
【本文为区分集合框架与Map,简称Map为 “映射” ——两个集合具有关联性,即具有4种映射关系的两集合视为一整体】

注:ConcurrentMap也是Map的子接口,这里未列出,会在单独的一章及其实现类进行详解。
Map顶级接口
| Map |
功能 | 函数名 |
|---|---|---|
| 增*3 | 增加一对k-v | V put(K key, V value) |
| 增加一个映射 | void putAll(Map m) | |
| 不存在key才增加 | default V putIfAbsent(K key, V value) | |
| 删*3 | 由Key删除 | V remove(Object key) |
| 删除指定k-v | default boolean remove(Object key, Object value) | |
| 清空所有 | void clear() | |
| 改*9【重】 | 当k存在时修改v | V put(K key, V value) |
| 【重】 | = n次put(k,v) | void putAll(Map m) |
| 仅当k存在时替换v | default V replace(K key, V value) | |
| 替换指定k-v的v | default boolean replace(K key, V oldValue, V newValue) | |
| 替换整个映射 | default void replaceAll(BiFunction function) | |
| 根据k对v计算并替换v 不论key存不存在 |
default V compute(K key, BiFunction remappingFunction) |
|
| k不存在计算并存储v 如果存在k返回v |
default V computeIfAbsent(K key, Function mappingFunction) |
|
| k存在计算并替换v 不存在k不操作 |
default V computeIfPresent(K key, BiFunction remappingFunction) |
|
| 合并v与oldV,如果合并值 为null,则删除key |
default V merge(K key, V value, BiFunction remappingFunction) |
|
| 查*6 | 查单个v / null通过k | V get(Object key) |
| 查单个v通过k 若k不存在返回默认v |
default V getOrDefault(Object key, V defaultValue) | |
| 查单个k是否在映射中 | boolean containsKey(Object key) | |
| 查单个v是否在映射中 | boolean containsValue(Object value) | |
| 是否为空映射 | boolean isEmpty() | |
| 查映射中的k-v数量 | int size() | |
| 转换*3 | 获取映射的keys动态视图 | Set keySet() |
| 获取映射的values动态视图 | Collection |
|
| 获取entry对象的Set集合 | Set |
|
| 迭代*1 | 对整个映射进行遍历消费 | default void forEach(BiConsumer action) |
注1:putAll(Map<> m)执行时,如果映射m被操作了,会导致putAll()函数undefined——不知何处的中断 put*n 操作。
注2:keySet()、values()、entrySet()生成映射的keys/values/entrys集合视图,此类集合由映射支持,因此对映射的更改将反映在集合中,反之亦然。如果此类Set集合在迭代时,其对应的map映射被修改,那么将会中断迭代。此类集合不支持元素增添操作add(),addAll(),支持元素删除:Iterator.remove(), Collection.remove(), removeAll(), retainAll(),clear()。
注3:虽然看起来put、replace、compute、merge函数功能上差不太多,但还是有一定的差异性,特适用于不同情况。之后根据具体的实现类进行详解。
注4:可以把一个Collection集合看做一列,两个Collection集合就是两列,两个集合对应元素c1.k——c2.v,通过一根直线连接组成一个Map对象。而如果以行来看我们又可以将两列两个集合,看成一列一个集合即——装载entry对象的Collection集合。
注5:replace方法仅当key存在时,使用newValue替换oldValue并返回oldValue,若不存在返回null。
Map成员接口Entry接口
| Entry | 功能 | 函数名 |
|---|---|---|
| 改*1 | 替换当前entry.v | V setValue(V value) |
| 查*2 | 获取当前entry.k | K getKey() |
| 获取当前entry.v | V getValue() | |
| 非抽象方法,以下均已实现 | ||
| 比较器*4 | 获取Key比较器,当K实现可比较接口时 | static |
| 获取Value比较器,当V实现可比较接口时 | static |
|
| 获取Key比较器,K未实现可比较接口 | static |
|
| 获取Value比较器,V未实现可比较接口 | static |
注:解析获取比较器函数举例2个:
1.Key类实现Comparable
static
| static | 静态方法修饰符 |
|---|---|
| 泛型方法的泛型描述 | |
| Comparator |
返回值类型 |
| comparingByKey() | 函数签名 |
2.Key类未实现Comparable
static
| static | 静态方法修饰符 |
|---|---|
| 泛型方法的泛型描述 | |
| Comparator |
返回值类型 |
| comparingByKey(Comparator cmp) | 函数签名 |
源码解析
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
/*类型强转:
(Comparator> & Serializable)
可以理解为强转后面的接口类型变量——Lambda表达式的匿名内部类对象,实际上是定义了lambda在运行时构建的类型。
有一个LambdaMetaFactory类,它在运行时获得该类型,如果该类型包含Serializable,则生成额外的代码。
关于能否强转/定义为其他类型的Lambda匿名内部类对象?
是可以的,必要条件是:存在的对象。在这个函数及其上下文中,只能强转cast为Comparator
lambda可以初始化为任何FunctionalInterface,基于所有接口都适合该lambda。*/
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
//同上
Map接口总结
Map类型对象可以被视为 并且 实质上也可以转换为两个(key、value)Collection聚集【keySet(),values()】,或者横向视为一个(Entry
Map接口的大量函数聚集在改函数以put,replace,compute,merge为代表的映射更改函数。
其他与Collection接口相差不多,Map没有迭代器,但也有foreach函数对Map进行遍历消费。
参考:Java lambda expressions, casting, and Comparators
集合框架总结
Java集合框架指代的是——一组Java接口,由Collection,Map两个顶级接口及其子接口组成,再由其实现类进行实现。当然根据不同情景下的使用需求,实现类会再实现一些常见接口,例如:Cloneable可克隆的,Serializable可序列化的等等。
需要注意的是,入门级别我们不需要熟悉Java集合框架的所有实现类
只需要掌握入门实现类——四大集合类+工具类+Properties即可
HashMap,TreeSet,ArrayList,LinkedList,Arrays,Collections,Properties
注1:HashTable是老的HashMap,HashSet底层实现是HashMap,Vector是老的ArrayList
注2:List、Set接口的4个常用实现类,在检索、插入上的优缺点
