python爬虫使用 requests-html爬取网页信息以及常用方法
目录
安装
使用
常用方法:
requests-html
获取a链接
获取img链接
操作列表两种写法
python处理数据常用方法
数组追加
obiect转str类型
arr转字符串->(仅限['xxxxxxxxxxxx'])
获取标签下文本
自定义保存页面图片
字符串去空格
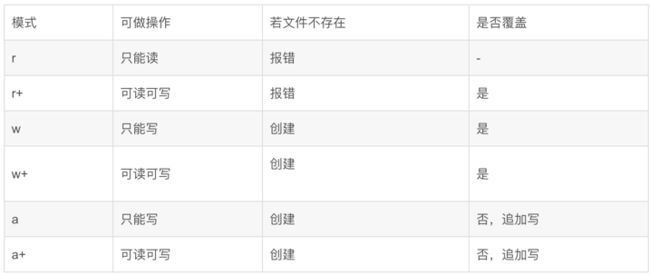
python 文件读写(追加、覆盖)
toString且' 转 "
int拼接组装
字符串拼接组装,并用符号分割
python类型转换
删除多余标签内的内容
html转字符串:
对象转json:
python json.dumps() 中文乱码问题
安装
pip install requests-html使用
from requests_html import HTMLSession # 获取请求对象 session = HTMLSession() sina = session.get('https://news.sina.com.cn/') sina.encoding = 'utf-8' print(sina.text)常用方法:
requests-html
获取a链接
# 绝对链接,全路径 sina.html.xpath('/html/body/div[3]/ul/li/a').absolute_links # links 相对链接 sina.html.xpath('/html/body/div[3]/ul/li/a').links # 得到的是{'http://xxxxxx'}的参数,需要转一下 obj.__str__().replace("{'", "").replace("'}", "")
获取img链接
# 获取链接地址 detail.html.xpath('/html/body/div/img/@src') # 获取到的是['xxxxxxx.jpg']格式 img.__str__().replace("['", "").replace("']", "")
操作列表两种写法
循环需要从0开始,node[i] == "node{}".format(i+1),因为xpath内没有下标0,所以format取元素下标加1
for i in range(0, len(lis)): name = sina.html.xpath('/html/body//span/text()')[i] list = sina.html.xpath('/html/body//li/div/a/span/text()'.format(i+1))python处理数据常用方法
数组追加
list2 = [] ... list2.append(node) node = {}
obiect转str类型
object.__str__().replace("{'", "").replace("'}", "")
arr转字符串->(仅限['xxxxxxxxxxxx'])
['xxxxxxxxxxxx'].__str__().replace("['", "").replace("']", "")
获取标签下文本
# /text()标签下的文本 detail.html.xpath('/html/body/a/text()') # //text() 标签下和子标签内容 detail.html.xpath('/html/body//text()')
自定义保存页面图片
def loadPage(img_url): response = requests.get(img_url) return response.content # 自定义保存页面图片函数 def getImage(image_url): # print("image_url= {}".format(image_url)) if image_url is None: return "" if len(image_url) <= 10: return "" name = image_url.split("/")[len(image_url.split("/"))-1] fth = "image/{}".format(name) img = loadPage(image_url) with open(fth, "wb") as f: f.write(img) return fth
字符串去空格
def strStrip(string): string = string.replace('\n', '').replace('\r', '').replace('\t', '').strip() string = string.replace("'", "").replace('\\n', '').replace('\\r', '').replace('\\t', '') return string
python 文件读写(追加、覆盖)
- 写json到本地write_json a持续写入
def write_json(content): with open('XueWei.txt', 'a', encoding='utf-8') as fObj: split = ",\n" json.dump(content, fObj, ensure_ascii=False) fObj.write(split) fObj.close()
- 写文本到本地 a持续写入
def write(content): split = "\n" f = open(file_path, 'a', encoding='utf-8') # 写入数据 f.write(content) f.write(split) # 关闭文件 f.close()
toString且' 转 "
# ' 转 " def toString(obj): return obj.__str__().replace("'", "\"")
int拼接组装
# return int 11 + 11 = 1111 def addInt(first, end): return int(first.__str__() + end.__str__())
字符串拼接组装,并用符号分割
# return String addStr("第一部", ",", "第二部") def addStr(first, sp, end): if len(first.__str__()) <= 0: return end.__str__() return first.__str__() + sp + end.__str__()
python类型转换
type("21") 获取类型int("23") 字符串转换成int数字- item['name'] 取对象里key为name的值
- num=322
str='%d'%num 数字转换成字符串# int(x[, base]) 将x转换为一个整数,base为进制,默认十进制 # # long(x[, base] ) 将x转换为一个长整数 # # float(x) 将x转换到一个浮点数 # # complex(real[, imag]) 创建一个复数 # # str(x) 将对象 x 转换为字符串 # # repr(x) 将对象 x 转换为表达式字符串 # # eval(str) 用来计算在字符串中的有效Python表达式, 并返回一个对象 # # tuple(s) 将序列 s 转换为一个元组 # # list(s) 将序列 s 转换为一个列表 # # set(s) 转换为可变集合 # # dict(d) 创建一个字典。d 必须是一个序列(key, value) 元组。 # # frozenset(s) 转换为不可变集合 # # chr(x) 将一个整数转换为一个字符 # # unichr(x) 将一个整数转换为Unicode字符 # # ord(x) 将一个字符转换为它的整数值 # # hex(x) 将一个整数转换为一个十六进制字符串 # # oct(x) 将一个整数转换为一个八进制字符串
删除多余标签内的内容
# 删除某个属性 doc('.article-t style').remove() # 清楚多余的标签,只保留纯文本 from w3lib.html import remove_tags a = 'ai工程师' print(remove_tags(a))html转字符串:
html.__str__().replace('"', "'")对象转json:
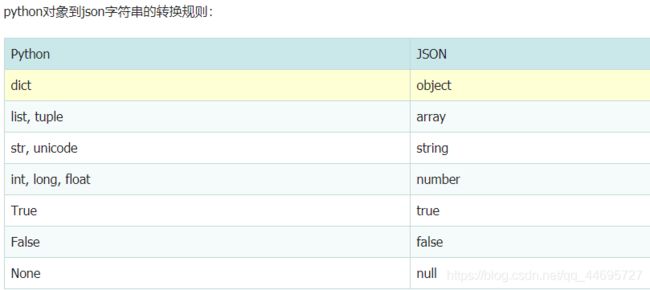
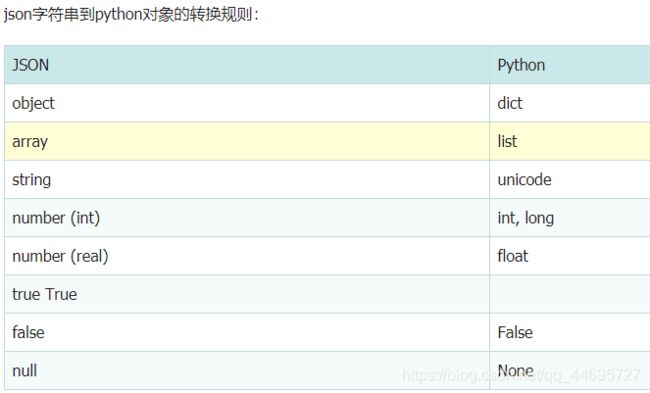
import json json.loads() 将json转换为dict json.dumps() 将dict转换为json json.load() 将json文件转换为dict json.dump() 将dict转换为json文件 person.json # 类对象转换为json person_json = json.dumps(person.__dict__) # 或者 # 第二个参数传递转换函数,或者使用default=lambda o: o.__dict__ person_json = json.dumps(person, default=convert2json) # 将person转换为dict def convert2json(person): return { 'name': person.name, 'age': person.age, 'email': person.email } # dict/对象转换为json文件 with open('person.json', 'w') as f: json.dump(person, f) # 将json文件转换为dict/对象 import json with open('person.json', 'r') as f: print(json.load(f))python json.dumps() 中文乱码问题
json.dumps 序列化时默认使用的ascii编码,想输出真正的中文需要指定ensure_ascii=False:更深入分析,是应为
dJSONobject 不是单纯的unicode实现,而是包含了混合的unicode编码以及已经用utf-8编码之后的字符串。写法:
Python2 :json.dumps(odata, ensure_ascii=False).decode('utf8') json.dumps(odata,ensure_ascii=False).decode('utf8').encode('gb2312') Python3 :json.dumps(odata, ensure_ascii=False)