Android架构组件(2)LifecycleRegistry 源码分析
文章目录
- 属性介绍
- 增加Observer
- ObserverWithState的工作原理
- FastSafeIterableMap的工作原理
- 删除Observer
- 更新状态
- 对于嵌套事件的处理
- 小结
这一节我们来学习
LifecycleRegistry的实现。
属性介绍
先来看一下LifecycleRegistry拥有的属性:
- mObserverMap:
FastSafeIterableMap类型,FastSafeIterableMap是androidx包里面的一个容器类,这个类的特点是实现了在遍历过程中的安全增删元素。LifecycleObserver是订阅者,ObserverWithState则是对订阅者的封装。 - mState:
State类型,记录了被订阅者LifecycleOwner的当前状态。 - mLifecycleOwner:
WeakReference类型,对应的LifecycleOwner的引用,并且特意被生命成了弱引用类型,这保证了当Lifecycle被泄漏之后,对应的LifecycleObserver不会被泄漏。
除此之外,LifecycleRegistry还有四个变量:mAddingObserverCounter(int)、mHandlingEvent(boolean)、mNewEventOccurred(boolean)、mParentStates(ArrayList;这四个变量都用于维护事件嵌套(在更新订阅者的过程中新增订阅者或者发送新事件)发生时LifecycleRegistry的状态维护,具体实现原理后面会有一节来详细说明,但需要先提到的是,LifecycleRegistry在所有订阅者之间维护了一个规则,我将其称之为状态有序性:
Invariant: at any moment of time for observer1 & observer2:
if addition_order(observer1) < addition_order(observer2), then
state(observer1) >= state(observer2),
也就是说,在任意时刻(无论是更新状态中还是更新之后),都有:新的订阅者的状态小于等于所有之前订阅的订阅者。首先解释一下,状态的大小是什么意思,Lifecycle用enum的形式定义了所有state:
public enum State {
DESTROYED,
INITIALIZED,
CREATED,
STARTED,
RESUMED;
}
所以state的大小关系是:DESTROYED < INITIALIZED < CREATED < STARTED < RESUMED;
那么,为什么所有订阅者之间的状态会不一致呢?这是因为在一个事件发生之后、LifecycleRegistry将事件通知给所有订阅者之前,存在一个同步的过程。这个同步的过程中,前面的订阅者已经通知到了,后面的订阅者还没被通知,于是所有订阅者之间的状态就不一致了;而这个情况下所有订阅者仍然满足这个规则。这个规则的含义就是这样,它的作用和影响我们留到后面的小节具体的场景中再谈。
下面就增加Observer、 删除Observer和发送事件三条线分析LifecycleRegistry的实现。
增加Observer
LifecycleRegistry增加Observer的方法如下:
@Override
public void addObserver(@NonNull LifecycleObserver observer) {
//1
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
ObserverWithState statefulObserver = new ObserverWithState(observer, initialState);
//2
ObserverWithState previous = mObserverMap.putIfAbsent(observer, statefulObserver);
if (previous != null) {
return;
}
LifecycleOwner lifecycleOwner = mLifecycleOwner.get();
if (lifecycleOwner == null) {
return;
}
//3
boolean isReentrance = mAddingObserverCounter != 0 || mHandlingEvent;
State targetState = calculateTargetState(observer);
mAddingObserverCounter++;
while ((statefulObserver.mState.compareTo(targetState) < 0
&& mObserverMap.contains(observer))) {
pushParentState(statefulObserver.mState);
statefulObserver.dispatchEvent(lifecycleOwner, upEvent(statefulObserver.mState));
popParentState();
targetState = calculateTargetState(observer);
}
if (!isReentrance) {
sync();
}
mAddingObserverCounter--;
}
像代码中标示的,addObserver这个方法可以分为三个部分:
- 第一步,将传入参数
observer封装成一个ObserverWithState对象;这层封装有两个用处,第一,LifecycleObserver和它的子类有的是用注解,有的是用继承,ObserverWithState统一了它们的接口,方便调用。第二,ObserverWithState内部也保存了state,用于记录这个observer已经回调到的状态,防止重复调用; - 第二步,将封装后的
statefulObserver保存进以原始参数observer为key的map中去,同时判断是否这个observer之前已经添加过了,如果previous不为null,表示之前已经添加过了,就直接退出流程;如果lifecycleOwner为null,说明lifecycleOwner已经死亡了,那么也可以直接退出。 - 第三步,将新的订阅者加进订阅者列表之后,需要将它的状态同步到最新的状态
mState。upEvent的返回值是传入state的下一个事件,这说明新的订阅者仍然会连续收到从INITIALIZED到当前状态之间的所有状态。除此之外,还有几个方法calculateTargetState和pushParentState和popParentState值得注意,这些方法用来保存和计算转换的状态。具体作用和实现留到后面统一来讲。
addObserver的运行逻辑大致如上所述。还有两点值得一提,订阅者封装类ObserverWithState是如何封装的,以及订阅者队列
mObserverMap作为一个map是怎么维护订阅者的状态有序性的。
ObserverWithState的工作原理
ObserverWithState的代码如下:
static class ObserverWithState {
State mState;
LifecycleEventObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer);
mState = initialState;
}
void dispatchEvent(LifecycleOwner owner, Event event) {
State newState = getStateAfter(event);
mState = min(mState, newState);
mLifecycleObserver.onStateChanged(owner, event);
mState = newState;
}
}
static State min(@NonNull State state1, @Nullable State state2) {
return state2 != null && state2.compareTo(state1) < 0 ? state2 : state1;
}
可以看到在构造函数中调用来Lifecycling类的lifecycleEventObserver方法来封装订阅者,这个方法的实现大致如下:
static LifecycleEventObserver lifecycleEventObserver(Object object) {
boolean isLifecycleEventObserver = object instanceof LifecycleEventObserver;
boolean isFullLifecycleObserver = object instanceof FullLifecycleObserver;
if (isLifecycleEventObserver && isFullLifecycleObserver) {
return new FullLifecycleObserverAdapter((FullLifecycleObserver) object,
(LifecycleEventObserver) object);
}
if (isFullLifecycleObserver) {
return new FullLifecycleObserverAdapter((FullLifecycleObserver) object, null);
}
if (isLifecycleEventObserver) {
return (LifecycleEventObserver) object;
}
...
if (type == GENERATED_CALLBACK) {
...
return new CompositeGeneratedAdaptersObserver(adapters);
}
return new ReflectiveGenericLifecycleObserver(object);
}
省略了一些代码后,还是可以清楚的看到,lifecycleEventObserver方法是根据传入参数的类型来调用不同的具体封装类,通过适配器、APT、反射等等手段来获得封装后的LifecycleEventObserver 对象:
public interface LifecycleEventObserver extends LifecycleObserver {
void onStateChanged(@NonNull LifecycleOwner source, @NonNull Lifecycle.Event event);
}
这样所有的订阅者的调用接口就一致了,LifecycleRegistry发送事件时,调用ObserverWithState的dispatchEvent方法发送event,ObserverWithState根据event获得对应的state,再调用LifecycleEventObserver的onStateChanged方法。还值得注意的是,在ObserverWithState的dispatchEvent中,调用LifecycleEventObserver的onStateChanged方法之前,将内部的mState更新成了旧状态和新状态中较小的这个,这也是为了维护状态有序性,后面会再次提到。
FastSafeIterableMap的工作原理
前面已经提到保存所有订阅者的容器mObserverMap类型是FastSafeIterableMap,一个map是怎么维护订阅者的状态有序性的呢?
FastSafeIterableMap继承自 SafeIterableMap,它的数据结构如下:
public class SafeIterableMap<K, V> implements Iterable<Map.Entry<K, V>> {
Entry<K, V> mStart;
private Entry<K, V> mEnd;
private WeakHashMap<SupportRemove<K, V>, Boolean> mIterators = new WeakHashMap<>();
...
static class Entry<K, V> implements Map.Entry<K, V> {
final K mKey;
final V mValue;
Entry<K, V> mNext;
Entry<K, V> mPrevious;
}
}
问题的答案就是它的两个变量mStart,mEnd,这两个变量维护了一个链表,当SafeIterableMap增加一个数据的时候,就会把这个变量加入到链表的末尾,这样就保存了订阅者订阅时间的先后顺序信息:
protected Entry<K, V> put(@NonNull K key, @NonNull V v) {
Entry<K, V> newEntry = new Entry<>(key, v);
mSize++;
if (mEnd == null) {
mStart = newEntry;
mEnd = mStart;
return newEntry;
}
mEnd.mNext = newEntry;
newEntry.mPrevious = mEnd;
mEnd = newEntry;
return newEntry;
}
另外之所以SafeIterableMap可以在遍历中安全增删数据,也是因为这种链表结构,当遍历时,SafeIterableMap会生成一个指向mStart,mEnd两个端点的Iterator对象,再把这个对象保存在mIterators中,有数据删除的时候,就更新mIterators中的所有Iterator:
public V remove(@NonNull K key) {
Entry<K, V> toRemove = get(key);
if (toRemove == null) {
return null;
}
mSize--;
if (!mIterators.isEmpty()) {
for (SupportRemove<K, V> iter : mIterators.keySet()) {
iter.supportRemove(toRemove);
}
}
...
}
删除Observer
增加Observer的过程很复杂,但删除就很简单了,直接根据对应的observer作为key,从map中将对应订阅者删除:
@Override
public void removeObserver(@NonNull LifecycleObserver observer) {
mObserverMap.remove(observer);
}
更新状态
更新状态的方法是setCurrentState:
public void setCurrentState(@NonNull State state) {
moveToState(state);
}
在moveToState会调用sync()方法更新状态:
private void moveToState(State next) {
if (mState == next) { return; }
mState = next;
if (mHandlingEvent || mAddingObserverCounter != 0) { //如果正在处理上一次的事件,就标记mNewEventOccurred 为true,先推出
mNewEventOccurred = true;
return;
}
mHandlingEvent = true; //更新 mHandlingEvent 状态为 true
sync();
mHandlingEvent = false;
}
sync()方法会通过 while循环 + isSynced() 的方法来将所有订阅者都更新到最新的状态:
private void sync() {
...
while (!isSynced()) {
mNewEventOccurred = false;
if (mState.compareTo(mObserverMap.eldest().getValue().mState) < 0)
backwardPass(lifecycleOwner);
Entry<LifecycleObserver, ObserverWithState> newest = mObserverMap.newest();
if (!mNewEventOccurred && newest != null && mState.compareTo(newest.getValue().mState) > 0)
forwardPass(lifecycleOwner);
}
mNewEventOccurred = false;
}
isSynced()内部通过判断最新和最老的订阅者的状态是否都等于当前状态mState来判断是否已经同步完毕的,如果没有,就通过订阅者状态和当前状态的大小比较来通过backwardPass或者forwardPass来更新订阅者状态。
sync()里这个判断状态的方式就是依赖了订阅队列的状态有序性:判断订阅队列存在状态大于当前状态的订阅者不需要检查整个队列,只需要跟订阅队列中状态最大的也就是最先订阅的订阅者比较;同样的判断订阅队列存在状态小于于当前状态的订阅者也只需要跟最新订阅的订阅者比较。
backwardPass或者forwardPass用于更新状态,其中backwardPass的作用是将订阅队列中所有状态大于当前状态的订阅者同步到当前状态。而forwardPass就是将订阅队列中的所有状态小于当前状态的订阅者同步到当前状态。用图说话就是:
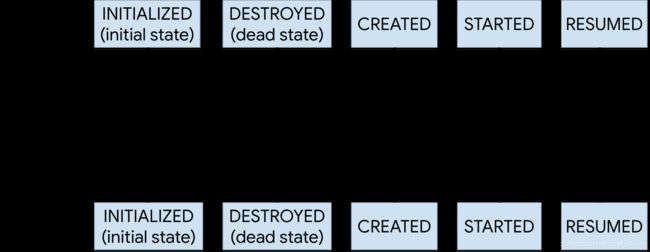 状态往
状态往INITIALIZED->RESUMED方向变化时,调用forwardPass方法。
状态往RESUMED->DESTROYED方向变化时,调用backwardPass方法。
这两个方法的实现相似,所以接下来只看一个forwardPass方法:
private void forwardPass(LifecycleOwner lifecycleOwner) {
Iterator<Entry<LifecycleObserver, ObserverWithState>> ascendingIterator =
mObserverMap.iteratorWithAdditions(); //获得从mStart到mEnd的Iterator
while (ascendingIterator.hasNext() && !mNewEventOccurred) { //遍历订阅队列
Entry<LifecycleObserver, ObserverWithState> entry = ascendingIterator.next();
ObserverWithState observer = entry.getValue();
while ((observer.mState.compareTo(mState) < 0 && !mNewEventOccurred
&& mObserverMap.contains(entry.getKey()))) {
pushParentState(observer.mState);
observer.dispatchEvent(lifecycleOwner, upEvent(observer.mState)); //调用订阅者回调。
popParentState();
}
}
}
这个方法的逻辑很简单,就是遍历队列,更新状态。唯一值得注意的是upEvent方法,这个方法返回值是传入state的下一个事件,这意味着无论LifecycleOwner更新状态是不是‘跳跃’的,每个订阅者收到的回调都是连续的。
对于嵌套事件的处理
看完上面的小节,我们对LifecycleRegistry的运行逻辑已经有了一个整体的了解,但是还有一些细节问题需要分析。
现在我们知道LifecycleRegistry只会在两个过程中对订阅队列进行状态同步:新订阅者的订阅和新状态的更新。在状态同步的时候,LifecycleRegistry会更新很多标志位以及对订阅者状态值的保存:
- mHandlingEvent:为true时,表示正在更新新状态的同步过程中。
- mAddingObserverCounter: >0时,表示正在同步新订阅者的状态过程中。
- mNewEventOccurred:在mHandlingEvent为true,或者mAddingObserverCounter>0,即正在进行状态同步时,这个标志位会设置为true,表示又有更新的状态需要同步,同步方法检测到这个值为true时,会中断正在进行的同步,以基于新状态再进行同步。
- mParentStates:这是一个通过popParentState和pushParentState更新的栈,在同步过程中,执行订阅者的回调前,先将订阅者当前状态pushParentState压入栈,在回调结束之后,popParentState出栈。
可以看出,LifecycleRegistry对同时有多个状态需要更新的冲突进行了完备的处理。但是有一点,LifecycleRegistry设计时是只能在主线程里调用的,它的大部分接口都标注了@MainThread注解。既然都是在一个线程里面运行,那么这种冲突显然不是来源于多线程。
mParentStates这个栈揭露了这种冲突的来源:在订阅者的事件回调中又产生了新的事件,这个问题可以被称为事件嵌套。
事件嵌套又可以分成两个部分:
- 在回调中,增加了新的订阅者。
- 在回调中,发送了新的事件。
为了解决事件嵌套带来的对订阅队列的同步机制的破坏,LifecycleRegistry使用了mNewEventOccurred标志,以中断当前同步再进行新的同步。
而为了解决事件嵌套增加的新订阅者对订阅队列的状态有序性的破坏,LifecycleRegistry在addObserver方法中同步新订阅者状态中计算最终状态targetState的方法calculateTargetState是这么设计的:
private State calculateTargetState(LifecycleObserver observer) {
Entry<LifecycleObserver, ObserverWithState> previous = mObserverMap.ceil(observer);
State siblingState = previous != null ? previous.getValue().mState : null;
State parentState = !mParentStates.isEmpty() ? mParentStates.get(mParentStates.size() - 1)
: null;
return min(min(mState, siblingState), parentState);
}
方法中的previous 表示新的订阅者前面的那个订阅者,也就是原来的订阅队列的队尾(现在的队尾是新订阅者了),calculateTargetState方法返回值取LifecycleRegistry当前状态,previous 当前状态,parentState栈顶状态的最小值,这样就保证了新的订阅者的状态不会大于之前的订阅者的状态。
也许看到这里的朋友,还有没有明白mParentStates这个栈是干什么用的,因为如果要维护状态有序性,只需要previous就够了,为什么还需要mParentStates呢?
这里就需要再回到mParentStates这个栈的运行规则了:mParentStates栈内的元素都是在同步过程中,订阅者执行回调前将当前状态进栈,回调结束后,将当前状态出栈,也就是在正常(即没有发送事件嵌套)的情况下,这个栈是没用的。因为添加新的订阅者时这个栈是空的,而如果在calculateTargetState方法中,这个栈非空,那就说明发生了事件嵌套,此时这个栈内存的状态正是导致添加新的订阅者的、也就是这个previous代表订阅者的当前状态。此时,如果previous存在,这个栈仍然没有起作用。
那么,如果previous已经不存在了呢?mParentStates的注释中举了一个例子,比如在这种情况下:
void onStart() {
mRegistry.removeObserver(this);
mRegistry.add(newObserver);
....
}
一个订阅者在ON_START的回调中,先将自己从订阅队列中移除了,再注册了一个新的回调,如果队列中原本就只有这个订阅者,那么当新订阅者注册时,订阅队列就是空的,这样在calculateTargetState方法中如果没有mParentStates,就会导致新的订阅者直接更新到LifecycleRegistry当前状态STARTED,但要注意,此时这个订阅者(指移除的订阅者)的ON_START回调还没有执行完,新的订阅者的ON_START回调就执行完了,这显然会带来一种逻辑上面的矛盾,因为LifecycleRegistry设计上是要求订阅队列的同步是按顺序执行的,所以这种情况下mParentStates就派上用场了,它限制了新的订阅者的状态更新晚于前面的订阅者。
小结
到这里,LifecycleRegistry就分析完了,总体而言,Lifecycles是一个特殊的订阅者模型,它的特殊之处在于它的每种事件的发生顺序是固定并且粘性(当你注册之后,会把之前的事件也发送)的,Lifecycles的使用很简单,因为它的实现已经被androidx库集成进了Activity和Fragment中。Lifecycles的实现大部分在LifecycleRegistry中,如果我们要构建自己的带有生命周期的组件,也可以直接使用这个类,但是要注意,LifecycleRegistry,包括Lifecycles这个框架,都不是线程安全的,一定要只在主线程中调用。