太赞了!这或许是腾讯一线最真实的Android面试资料了吧
都说金三银四青铜五,这几个月份是程序员最好的跳槽时间。作为求职这来说,面试是一道坎,很多人会恐惧面试,即使是工作很多年的老鸟,可能仍存在面试的焦虑。
所以今天小编就在这面分享一波大厂面试题及技术知识点福利,不多说直接上干货。
以下是本文的知识清单:
- SparseArray
- atomic包
- Android埋点
- Java基础之注解
- 一点小感悟
在这里由于文字较多,小编总结了一份高阶Android技术大纲和学习资料免费分享给大家,文末有领取!
1. SparseArray
当新建一个key为整型的HashMap时,会出现如下的提示信息,推荐使用SparseArray来替代HashMap:

接下来就来介绍下SparseArray:
a.数据结构:又称稀疏数组,内部通过两个数组分别存储key和value,并用压缩的方式来存储数据
b.优点:可替代key为int、value为Object的HashMap,相比于HashMap
-
能更节省存储空间
-
由于key指定为int,能节省int和Integer的装箱拆箱操作带来的性能消耗
-
扩容时只需要数组拷贝工作,而不需重建哈希表
c.适用场景:数据量不大(千以内)、空间比时间重要、需要使用Map且key为整型;不适合存储大容量数据,此时性能将退化至少50%
d.使用
添加:public void put(int key, E value)
删除:
-
public void delete(int key)
-
public void remove(int key)实际上内部会调用delete方法
查找:
-
public E get(int key)
-
public E get(int key, E valueIfKeyNotFound)可设置假设key不存在时默认返回的value
-
public int keyAt(int index)获取相应的key
-
public E valueAt(int index)获取相应的value
e.get/put过程:元素会按照key从小到大进行存储,先使用二分法查询key对应在数组中的下标index,然后通过该index进行增删查。源码分析见SparseArray解析
2. atomic包
a.原子操作类:
与采取悲观锁策略的synchronized不同,atomic包采用乐观锁策略去原子更新数据,并使用CAS技术具体实现
//保证自增线程安全的两种方式
public class Sample {
private static Integer count = 0;
synchronized public static void increment() {
count++;
}
}
public class Sample {
private static AtomicInteger count = new AtomicInteger(0);
public static void increment() {
count.getAndIncrement();
}
}
基础知识:Java并发问题--乐观锁与悲观锁以及乐观锁的一种实现方式-CAS
b.类型
原子更新基本类型:
-
AtomicInteger:原子更新Integer
-
AtomicLong:原子更新Long
-
AtomicBoolean:原子更新boolean
以AtomicInteger为例,常用方法:
-
getAndAdd(int delta):取当前值,再和delta值相加
-
addAndGet(int delta) :先和delta值相加,再取相加后的最终值
-
getAndIncrement():取当前 值,再自增
-
incrementAndGet() :先自增,再取自增后的最终值
-
getAndSet(int newValue):取当前值,再设置为newValue值
原子更新数组:
-
AtomicIntegerArray:原子更新整型数组中的元素
-
AtomicLongArray:原子更新长整型数组中的元素
-
AtomicReferenceArray:原子更新引用类型数组中的元素
以AtomicIntegerArray为例,常用方法:
-
addAndGet(int i, int delta):先将数组中索引为i的元素与delta值相加,再取相加后的最终值
-
getAndIncrement(int i):取数组中索引为i的元素的值,再自增
-
compareAndSet(int i, int expect, int update):如果数组中索引为i的元素的值和expect值相等,则更新为update值
原子更新引用类型:
-
AtomicReference:原子更新引用类型
-
AtomicReferenceFieldUpdater:原子更新引用类型里的字段
-
AtomicMarkableReference:原子更新带有标记位的引用类型
//这几个类提供的方法基本一致,以AtomicReference为例
public class AtomicDemo {
private static AtomicReference reference = new AtomicReference<>();
public static void main(String[] args) {
User user1 = new User("a", 1);
reference.set(user1);
User user2 = new User("b",2);
User user = reference.getAndSet(user2);
System.out.println(user);
//输出
User{userName='a', age=1} System.out.println(reference.get());
//输出
User{userName='b', age=2}}static class User { private String userName;
private int age; public User(String userName, int age) { this.userName = userName; this.age = age;
} @Override public String toString() {
return "User{" +"userName='" + userName + '\'' +", age=" + age + '}';
}
}
}
原子更新字段:
-
AtomicIntegeFieldUpdater:原子更新整型字段
-
AtomicLongFieldUpdater:原子更新长整型字段
-
AtomicStampedReference:原子更新带有版本号的引用类型
使用方法:由于原子更新字段类是抽象类,因此需要先通过其静态方法newUpdater创建一个更新器,并设置想更新的类和属性
注意:被更新的属性必须用public volatile修饰
//这几个类提供的方法基本一致,以AtomicIntegeFieldUpdater为例
public class AtomicDemo {
private static AtomicIntegerFieldUpdater updater = AtomicIntegerFieldUpdater.newUpdater(User.class,"age");
public static void main(String[] args) { User user = new User("a", 1);
int oldValue = updater.getAndAdd(user, 5);
System.out.println(oldValue);
//输出1
System.out.println(updater.get(user));
//输出6
}static class User { private String userName;
public volatile int age;
public User(String userName, int age) {
this.userName = userName;
this.age = age;
} @Override public String toString() { return "User{" +"userName='" + userName + '\'' +", age=" + age +'}';
}
}
}
c.优点:
可以避免多线程的优先级倒置和死锁情况的发生,提升在高并发处理下的性能,相比于synchronized ,在非激烈竞争的情况下,开销更小,速度更快
3. Android埋点
a.含义:预先在目标应用采集数据,对特定用户行为或事件进行捕获、处理,并以一定方式上报至服务器,便于后续进行数据分析
b.方式
代码埋点:在某个事件发生时通过预先写好的代码来发送数据
-
优点:控制精准,采集灵活性强,可自由选择何时发送自定义数据
-
缺点:开发、测试成本高,需要等发版才能修改线上埋点、更新代价大
无埋点/全埋点:在端上自动采集并上报尽可能多的数据,在计算时筛选出可用的数据
-
优点:很大程度上减少开发、测试的重复劳动,数据可回溯且覆盖全面
-
缺点:采集信息不够灵活,数据量大,后端筛选分析工作量大
可视化埋点:通过可视化工具选择需要收集的埋点数据,下发配置给客户端,终端点击时获取当前点击的控件根据配置文件进行选择上报
-
优点:很大程度上减少开发、测试的重复劳动,数据量可控且相对精确,可在线上动态埋点、而无需等待App发版
-
缺点:采集信息不够灵活,无法解决数据回溯的问题
几个实践:51信用卡(https://mp.weixin.qq.com/s/svzwQkAy0favp0Ty3NtoLA)、网易(https://mp.weixin.qq.com/s/0dHKu5QIBL_4S7Tum-qW2Q)、58同城(https://mp.weixin.qq.com/s/rP7PiN7lsnUxcY1BAhB_5Q)
4.Java基础之注解(Annotation)
a.含义:是附加在代码中的一些元数据,在JDK1.5 版本开始引入,与类、接口、枚举在同一个层次
b.作用:
声明在包、类、字段、方法、局部变量、方法参数等前面,用来对这些元素进行说明和注释
注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用,比如编译时进行格式检查、简化操作进而降低代码量
c.使用
以下代码展示了注解的定义、属性和使用的方法:
//1.注解的定义:
通过@interface关键字//以下表示创建了一个名为TestAnnotation的注解public @interface TestAnnotation {
//2.注解的属性:
//声明:采用“无形参的方法”形式,方法名表示属性名,返回值表示属性类型
//类型:必须是8种基本数据类型,或者类、接口、注解及对应数组
//默认值:用default关键值,在赋值时可以省略
//以下表示注解TestAnnotation中有id和msg两个属性,且msg默认值为hiint id();String msg() default "hi";}
//3.注解的使用://对属性赋值:在注解使用打个括号,以value=""形式,多个属性之前用逗号隔开;若注解只有一个属性,则赋值时value=可以省略;如果没有属性,括号都可以省略//以下表示对Test类进行标识,并对注解的适两个属性进行赋值@TestAnnotation(id=1,msg="hello")public class Test {}
d.类型:
元注解:是一种基本注解,用于解释注解,注意其描述对象是注解而非代码,包含类型如下表:

来段代码感受下这些注释的使用效果:
//表示TestAnnotation注释是对类描述的、保留到运行时、被添加到Javadoc、有继承性值的
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inheritedpublic
@interface
TestAnnotation {}
//由于B类是A类的子类,且B类没被任何注解应用,则B类继承了A类的TestAnnotation注解@TestAnnotationpublic class A {}public class B extends A {}
接下来用单独一个例子来解释可重复注解
//1.定义一个注解容器(此处指@Persons):
//作用:存放其他注解(此处指@Person),其本身也是个注解
//注意:需要有个value属性,类型就是被@Repeatable解释的注解数组(此处指Person[])@interface Persons { Person[] value();
//注解属性}
//2.使用@Repeatable解释(此处指@Person),括号中是注解容器类(此处指Persons)@Repeatable(Persons.class)@interface Person { String role default "";
//注解属性}
//3.使用@Repeatable解释的注释时,可以取多个注解值来解释代码@Person(role="coder")@Person(role="PM")public class SuperMan {
//SuperMan既是程序员又是产品经理}
Java内置注解:下表展示了几个常用的内部已实现注解

自定义注解:在之前已经介绍了注解的定义、属性和使用的具体方法,还差一步,注解的提取,需要通过Java的反射技术获取类方法和字段的注解信息,常用方法:
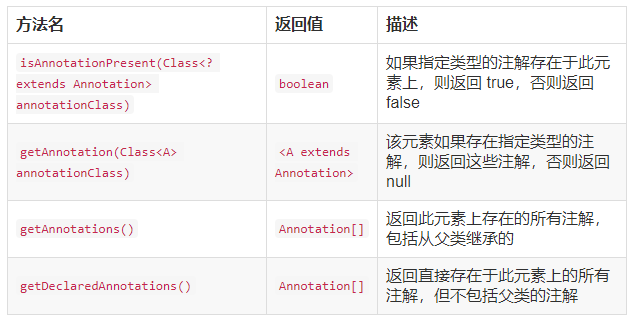
在之前的Test类里就可以添加以下代码,来获取在类上给@TestAnnotation设置的属性值了:
boolean hasAnnotation = Test.class.isAnnotationPresent(TestAnnotation.class);
if (hasAnnotation) { TestA
结尾
如何才能让我们在面试中对答如流呢?
答案当然是平时在工作或者学习中多提升自身实力的啦,那如何才能正确的学习,有方向的学习呢?有没有免费资料可以借鉴。为此我整理了一份Android学习资料路线:

好啦,如此文章到这里就结束了,如果你觉得不错就给个赞呗?如果你觉得那里值得改进的,请给我留言。一定会认真查询,修正不足。谢谢。
希望读到这的您能转发分享和关注一下我,以后还会更新技术干货,谢谢您的支持!
最后这里是关于我自己的Android 学习,面试文档,视频收集大整理,有兴趣的伙伴们可以看看~