MySql集群-PXC(简单安装)

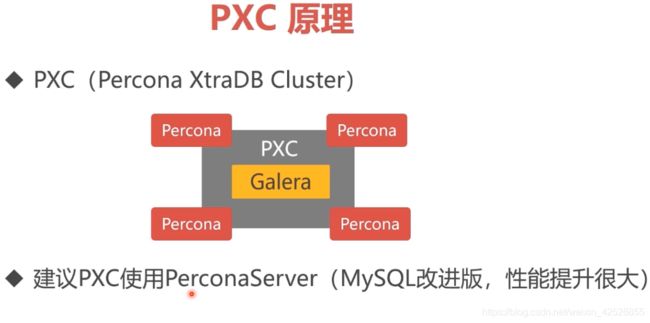
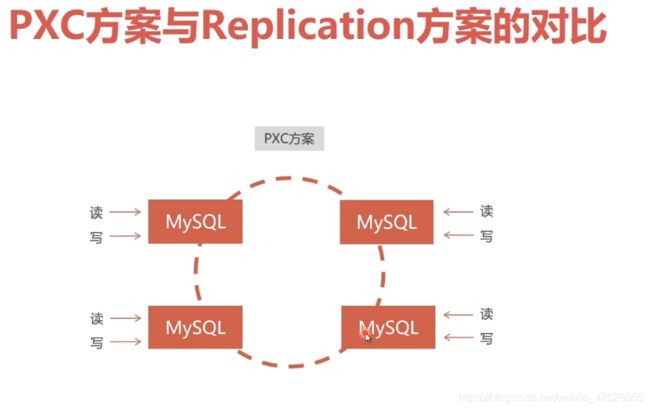
pxc集群的 结点是双向的,在 A结点的操作在 B结点也能看到,
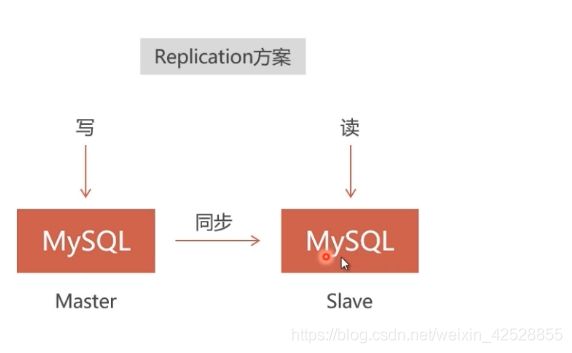
在 Slave结点进行写操作,在 Master 结点 是读取不到的。
是单向的。
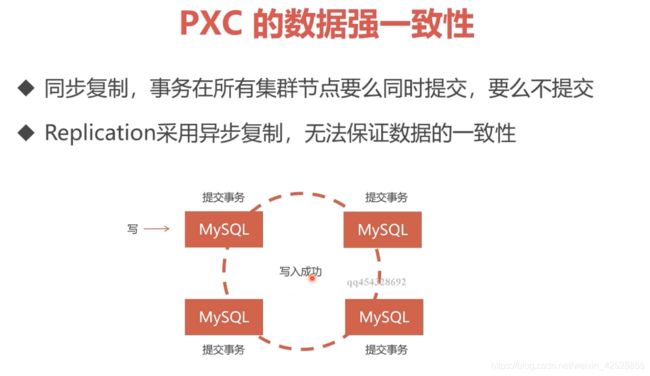
pxc:在全部结点上写入数据,才算一次 写入的成功。
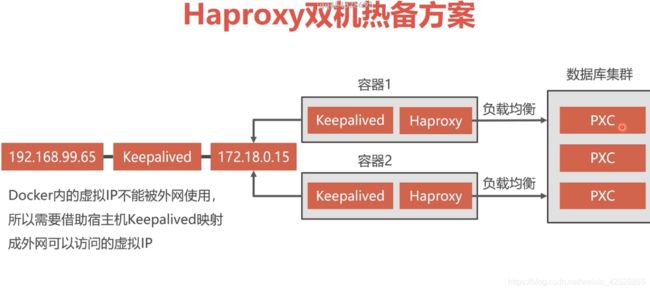
在本地服务器上 创建 Pxc集群:
需要创建 :
一个docker容器,
一个docker内部网络,
一群pxc,
两个 haproxy 容器,
三个 keepalived【两个分别在两个haproxy 容器中,一个在宿主机上】
目录
1.安装PXC镜像
2.创建内部网段:
3.创建 Docker卷:
4.创建PXC容器:
5.总结 创建pxc集群:
5.1 创建一个docker内部网络:
5.2 创建 多个 docker 卷:
5.3 创建pxc结点
6.删除pxc集群:
7.数据库负载均衡:
7.1 安装 Haproxy 镜像:
7.2 创建 Haproxy 配置文件:
在 /home/soft/haproxy/ 目录下
haproxy配置文件(haproxy.cfg):
7.3 创建 Haproxy容器(创建两个):
关闭pxc结点:
创建第二个 haproxy:
双机热备:
利用 Keepalived实现双机热备:
安装 Keepalived :
Keepalived 配置文件:
启动 keepalived:
在宿主机上创建 Keepalived :
封装好的Haproxy:
5.PXC节点闪退:
1.安装PXC镜像
PXC只能在Linux或docker上安装。

pxc官方镜像的主页:https://hub.docker.com/r/percona/percona-xtradb-cluster
第一个命令:是从docker中下载:
docker pull percona/percona-xtradb-cluster:5.7.21【最稳定】
第二个命令:是镜像已在本地,直接用镜像
安装好镜像后,将其名字进行修改:
docker tag docker.io/percona/percona-xtradb-cluster pxc

这样就有两个了,将原先的删除
docker rmi docker.io/percona/percona-xtradb-clus ter
ter
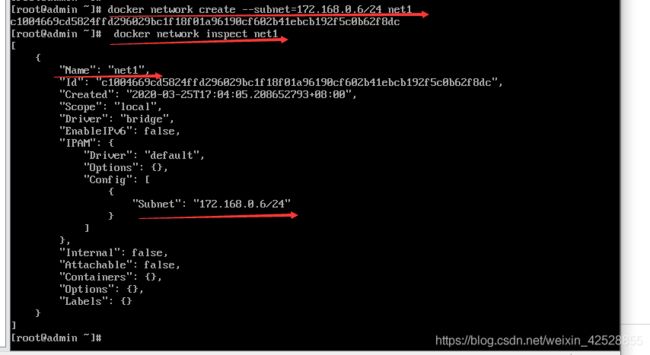
2.创建内部网段:

1.创建网段
2.查看相关信息: docker network inspect net1
3.删除:docker network rm net1
自己指定网段IP:
docker network create --subnet=172.168.0.6/24 net1
net1(网段名称)
172.168.0.6(IP)
24(24位的子网掩码)
创建成功:
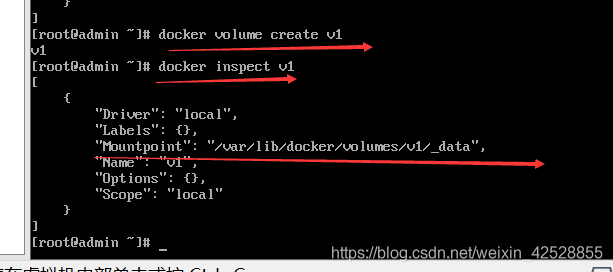
3.创建 Docker卷:
docker 使用原则:不要将 运行数据存放到 docker容器中,要使用 映射目录技术,映射到宿主机上,这样容器发生故障,
就删除该容器,重新创建一个,再次映射原先的宿主机上的数据目录即可。
但是pxc在docker容器中无法直接使用 映射目录(会直接闪退),所以使用 docker卷技术

命令:docker volume create v1
4.创建PXC容器:

-d:是在后台运行,【创建docker容器时,-it 表示:交互界面,但是pxc只能在后台运行,否则怎样创建其他的pxc容器】。
-p:端口的映射,前一个端口是 宿主机的,后一个是容器的。
-v:映射Docker卷到容器的mysql数据目录【v1就是上面创建的数据卷】
MYSQL_ROOT_PASSWORD:表示创建的数据库密码
CLUSTER_NAME: 表示创建出的集群名字
XTRABACKUP_PASSWORD:表示集群通信密码
--privileged:表示分配最高权限
--net:指定网段
-
--ip:指定IP
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=123456 -v v1:/var/lib/mysql --privileged --name=node1 --net=net1 --ip 172.168.0.7 pxc
容器创建会很快,但是容器里面的MySQL数据库的初始化,会需要几分钟,如果,你要创建pxc集群,要等第一个MySQL数据库初始化完,才创建,否则后面的容器启动后会闪退。
所以要耐心地将第一个MySQL数据库连接成功后,才创建第二个pxc容器
5.总结 创建pxc集群:
5.1 创建一个docker内部网络:
docker network create --subnet=172.168.0.6/24 net1
5.2 创建 多个 docker 卷:
docker volume create v1
docker volume create v2
docker volume create v3
docker volume create v4
docker volume create v5
5.3 创建pxc结点
注意:只有创建第一个pxc节点的 MySQL 数据库初始化较慢,其他的都很快
创建第一个pxc结点:
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=123456 -v v1:/var/lib/mysql --privileged --name=node1 --net=net1 --ip 172.168.0.7 pxc
后面的命令和第一个有所不同:
后面的多了:CLUSTER_JOIN=node1,
映射到宿主机的端口号不同: -p 3307:3306,
IP地址不同:--ip 172.168.0.7
创建node2:
docker run -d -p 3307:3306 -v v2:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=node1 --privileged --name=node2 --net=net1 --ip 172.168.0.8 pxc
创建node3:
docker run -d -p 3308:3306 -v v3:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=node1 --privileged --name=node3 --net=net1 --ip 172.168.0.9 pxc
创建node4:
docker run -d -p 3309:3306 -v v4:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=node1 --privileged --name=node4 --net=net1 --ip 172.168.0.10 pxc
创建node5:
docker run -d -p 3310:3306 -v v5:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=123456 -e CLUSTER_JOIN=node1 --privileged --name=node5 --net=net1 --ip 172.168.0.11 pxc
查看当前有哪些运行容器:
[root@hongshaorou ~]# docker ps -a
这样pxc集群就简单创建出来了。
安装在本地的服务器如果关闭,会导致pxc集群挂掉,简单的做法就是删除集群,再重新创建,因为数据保存在宿主机上,
所以不用担心删除数据。
6.删除pxc集群:
直接通过docker start node1 或者任何一个节点是启动不了的,原因是集群之前的同步机制造成的,启动任何一个节点,该节点都会去其它节点同步数据,其它节点仍处于宕机状态,所以该节点启动失败,这也是pxc集群的强一致性的表现。
解决方式是:
1.删除所有节点: docker rm node1 node2 node3 node4 node5
2.和数据卷中的grastate.dat文件
rm -rf /var/lib/docker/volumes/v1/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v2/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v3/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v4/_data/grastate.dat
rm -rf /var/lib/docker/volumes/v5/_data/grastate.dat
3.重新执行集群创建的命令即可,因为数据都在数据卷中,所有放心,集群重新启动都数据仍然都在.。
7.数据库负载均衡:

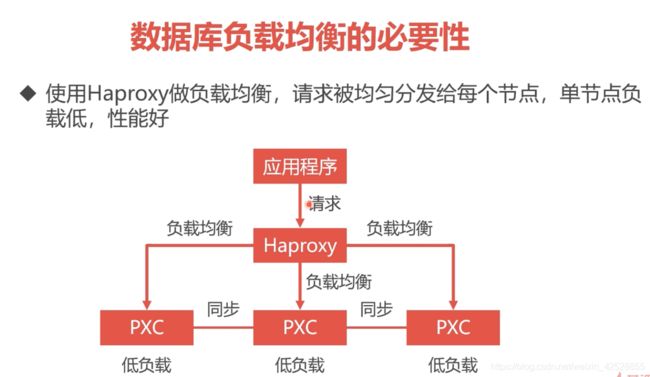
Haproxy 是一个转发器
7.1 安装 Haproxy 镜像:

命令:docker pull haproxy
haproxy镜像不包含配置文件。
7.2 创建 Haproxy 配置文件:

参考haproxy配置文件 网址 :https://zhangge.net/5125.html
在 /home/soft/haproxy/ 目录下
haproxy配置文件(haproxy.cfg):
##############################################
#configure haproxy.cfg
global
log 127.0.0.1 local5 info
maxconn 4096 #最大连接数
chroot /usr/local/etc/haproxy #安装目录
daemon #守护进程运行
nbproc 1 #进程数量
defaults
log global
mode http #7层 http;4层tcp 如果要让haproxy支持虚拟主机,mode 必须设为http
option httplog #http 日志格式
log 127.0.0.1 local6
option httpclose #主动关闭http通道
option redispatch #serverId对应的服务器挂掉后,强制定向到其他健康的服务器
retries 1
option dontlognull
maxconn 2000 #最大连接数
timeout connect 3600000 #连接超时(毫秒)
timeout client 3600000 #客户端超时(毫秒)
timeout server 3600000 #服务器超时(毫秒)
#监控界面
listen admin_stats
bind 0.0.0.0:8888
mode http
stats uri /dbs
stats realm Global\ statistics
stats auth admin:123456
#数据库负载均衡
listen proxy-mysql
#访问的IP和端口
bind 0.0.0.0:3306
#网络协议
mode tcp
#轮询算法
balance roundrobin
#日志格式
option tcplog
# option mysql-check user haproxy #在mysql中创建无任何权限用户haproxy,且无密码
server MySQL1 172.168.0.7:3306 check weight 1 maxconn 2000
server MySQL2 172.168.0.8:3306 check weight 1 maxconn 2000
server MySQL3 172.168.0.9:3306 check weight 1 maxconn 2000
server MySQL4 172.168.0.10:3306 check weight 1 maxconn 2000
server MySQL5 172.168.0.11:3306 check weight 1 maxconn 2000
option tcpka
##############################################
7.3 创建 Haproxy容器(创建两个):

在 /home/soft/haproxy 目录下执行该命令:
docker run -it -d -p 4001:8888 -p 4002:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name h1 --privileged --net=net1 --ip 172.168.0.6 haproxy

haproxy已经创建成功,在后台运行
进入后台程序,启动 haproxy
命令:docker exec -it h1 bash

启动 haproxy:
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
在 pxc的第一个结点上创建一个账号:
CREATE USER 'haproxy'@'%' IDENTIFIED BY '';
创建一个用户名为:haproxy,任何IP都可以登陆,密码为空的用户账号
然后就可以登录监控画面了:
http://自己宿主机IP:4001/dbs
登陆账号:admin
登陆密码:123456
这是在 haproxy的配置文件中设置的
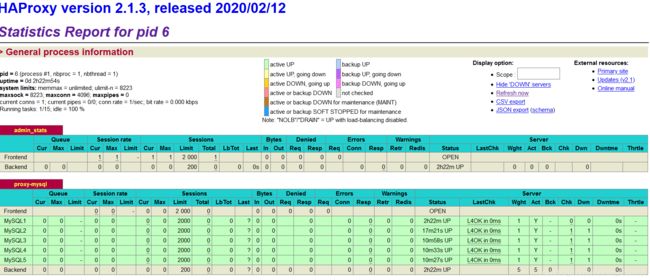
关闭pxc结点:
docker stop node1
再次观察监控:
node1结点变红了,其余结点正常

进行 haproxy数据库连接:
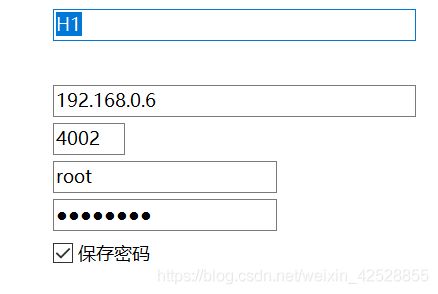
端口号 4002 是在创建haproxy容器时创建的,
这里用的用户名和密码是填写的5个数据库的用户名和密码
密码为:123456

haproxy数据库不进行数据的增删改查操作,而是将操作分发给pxc集群,起到负载均衡的作用
创建第二个 haproxy:
docker run -it -d -p 4001:8888 -p 4002:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name h1 --privileged --net=net1 --ip 172.168.0.6 haproxy
注意:两个容器的映射的宿主机的端口不能重复,docker 网络是一样的,对应的 IP 不能一样,映射目录可以不一样
haproxy.cfg 配置文件可以一样。
haproxy已经创建成功,在后台运行
进入后台程序,启动 haproxy
命令:docker exec -it h3 bash
启动 haproxy:
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
双机热备:
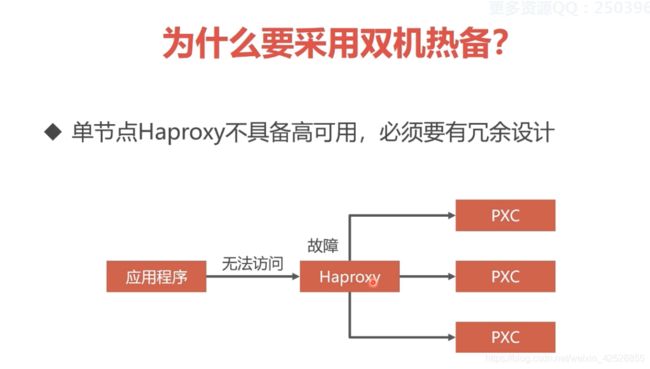
双机热备方案离不开 虚拟IP技术:
利用 Keepalived实现双机热备:
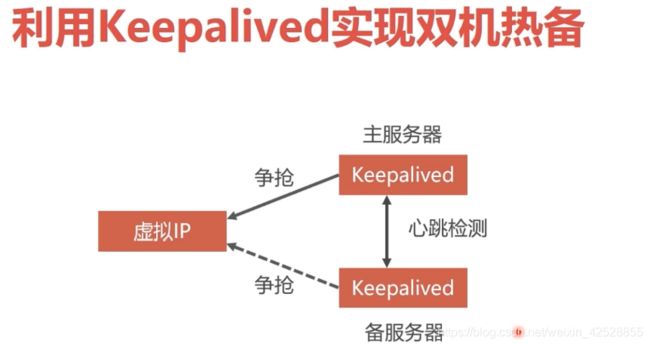
这就意味着要:在两个 haproxy容器分别创建 keepalived:
安装 Keepalived :

不要将 apt换成国内的,不好用。国外的慢就慢点,但是能用啊
Keepalived 配置文件:
注意: /etc/keepalived/keepalived.conf 是在 haproxy容器的目录,
要使用 目录映射技术

如果在宿主机上编辑文件,就不用上面的命令
配置信息:
######################################################
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
172.168.0.201
}
}
######################################################
1.Keepalived的身份(MASTER主服务 , BACKUP备服务器)。主服务要抢占虚拟IP 备用服务器不会抢占IP.
2.interface eth0 :网卡设备,定义一个虚拟IP,这个IP保存在eth0这个网卡中。eht0是docker虚拟机的一个网卡,
其在局域网上是看不见的,所以将IP写到网卡里,在宿主机上能访问这个网卡,但是在其他电脑上看不到该网卡,
所以需要在宿主机上把eth0这个网卡里的虚拟IP映射到局域网的一个虚拟IP上。所以还要再宿主机上安装Keepalived。
3. priority 100:MASTER权重要高于BACKUP,数字越大优选级越高
4.virtual ipaddress: 虚拟IP,可以设置多个虚拟IP地址,每行一个
172.168.0. :数据库集群(pxc)网段
启动 keepalived:

service keepalived start
ping 172.168.0.201
在宿主机上创建 Keepalived :
由于本人是centos7系统,命令是:
yum install -y keepalived
在宿主机上的Keepalived 配置文件
配置文件在 宿主机的 /etc/keepalived 目录下
###########################################
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.150
}
}
virtual_server 192.168.0.150 8888 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
real_server 172.168.0.201 8888 {
weight 1
}
}
virtual_server 192.168.0.150 3306 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
real_server 172.168.0.201 3306 {
weight 1
}
}
################################################
VMware虚拟机必须是桥接模式才能用虚拟IP
映射的 docker keepalived都是 haproxy上的端口
在 宿主机的 /etc/keepalived 目录下启动
service keepalived start
ping 192.168.0.150
监控:http://192.168.0.150:8888/dbs
封装好的Haproxy:
当虚拟机从挂起再次启动时,docker这个进程是得不到网络的,
所以 需要更改宿主机的配置文件,让宿主机从挂起恢复到 运行状态,
能为 docker 分配网络服务

vi /etc/sysctl.conf
在最后添加:net.ipv4.ip_forward=1
然后需要重启网络服务: systemctl restart network
启动Linux服务器后:
1. 如果关机先重启
docker:service docker restart
docker容器:
2.启动haproxy容器:
命令:docker start h1
命令:docker start h3
然后启动 haproxy服务 :
命令: docker exec -it h1 bash
命令:exit 【退出交互界面,不停止服务】
命令:docker exec -it h3 bash
命令:exit
3. 启动 docker里的 keepalived:
service keepalived start 【不是在haproxy容器里面 ,在宿主机,这是启动的是docker里的keepalived 】
访问:http://宿主机IP:4001/dbs
4.启动宿主机上的keepalived:
在 宿主机的 /etc/keepalived 目录下启动
cd /etc/keepalived
service keepalived start
ping 192.168.0.150
监控:http://192.168.0.150:8888/dbs
5.PXC节点闪退:
###如果PXC集群在运行的状态下,在宿主机上直接关机,或者停止Docker服务,为什么下次启动哪个PXC节点都会闪退?
这个要从PXC集群的节点管理说起,PXC节点的数据目录是/var/lib/mysql,好在这个目录被我们映射到数据卷上了。比如你访问v1数据卷就能看到node1的数据目录。这其中有个grastate.dat的文件,它里面有个safe_to_bootstrap参数被PXC用来记载谁是最后退出PXC集群的节点。比如node1是最后关闭的节点,那么PXC就会在把safe_to_bootstrap设置成1,代表node1节点最后退出,它的数据是最新的。下次启动必须先启动node1,然后其他节点与node1同步。
如果你在PXC节点都正常运行的状态下关闭宿主机Docker服务或者电源,那么PXC来不及判断谁是最后退出的节点,所有PXC节点一瞬间就都关上了,哪个节点的safe_to_boostrap参数就都是0。解决这个故障也很好办,那就是挑node1,把该参数改成1,然后正常启动node1,再启动其他节点就行了
修改:/var/lib/docker/volumes/v1/_data/grastate.dat 文件
safe_to_bootstrap设置成1
然后 依次启动 node结点:
docker start node1