CentOS7上安装 percona 数据库3 主架构
我没有去下载 Percona-XtraDB-Cluster ,而是通过更新yum源的方式:
rpm -Uvh https://www.percona.com/redir/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm另外,请注意:pxc集群各节点之间不需要配ssh免密互信。
一 准备工作
1. 准备三台机器:
192.168.158.144
192.168.158.145
192.168.158.146
2. 关闭三台机器上的selinux校验
setenforce 0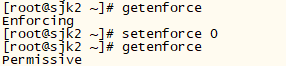
3. 在三台机器上分别更新percona-release的yum源:
rpm -Uvh https://www.percona.com/redir/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm
更新过yum源后,会在 /etc/yum.repos.d/ 下生成 percona-release.repo,如图:

此时,

二 在3台机器上安装 Percona-XtraDB-Cluster
1 先查看有哪些可用Percona-XtraDB-Cluster包,
yum list | grep percona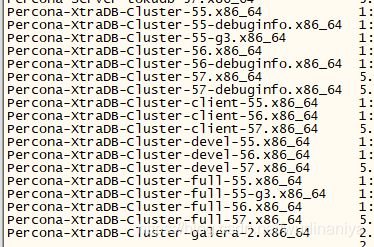
percona 安装包依赖关系:
Percona-XtraDB-Cluster-57-5.7.23-31.31.1.el7.x86_64.rpm 依赖于:
Percona-XtraDB-Cluster-server-57 = 5.7.23-31.31.1.el7
Percona-XtraDB-Cluster-client-57 = 5.7.23-31.31.1.el7Percona-XtraDB-Cluster-client-57-5.7.23-31.31.1.el7.x86_64.rpm 依赖于:
perl-DBIPercona-XtraDB-Cluster-server-57-5.7.23-31.31.1.el7.x86_64.rpm 依赖于:
Percona-XtraDB-Cluster-client-57 = 5.7.23-31.31.1.el7
Percona-XtraDB-Cluster-shared-57 = 5.7.23-31.31.1.el7
percona-xtrabackup-24 >= 2.4.12
perl(Data::Dumper)
perl-DBD-MySQL
perl-DBI
qpress
socatpercona-xtrabackup-80-8.0.6-1.el7.x86_64.rpm 依赖于:
libev.so.4()(64bit)
perl(DBD::mysql)
perl(Digest::MD5)Percona-XtraDB-Cluster-shared-57-5.7.23-31.31.1.el7.x86_64.rpm 有一个冲突:
error: Failed dependencies:
mariadb-libs >= 5.5.37 is obsoleted by Percona-XtraDB-Cluster-shared-57-5.7.23-31.31.1.el7.x86_64
因此,安装顺序:
移除的依赖:
[root@sjk2 ~]# rpm -qa|grep mariadb
mariadb-libs-5.5.56-2.el7.x86_64
yum -y remove mariadb-libs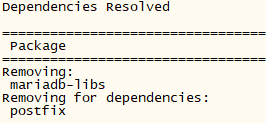
移除依赖 mariadb-libs 后,
![]()
同时,/etc/ 下也不再有 ![]()
安装依赖1:
yum -y install socat安装依赖2:
yum -y install libev安装依赖3:
yum -y install perl-Digest-MD5或者你多安几个也无所谓:
yum -y install perl-Digest-MD5 perl-Digest-SHA perl-Digest-SHA1
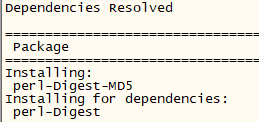

安装依赖4:
[root@sjk1 ~]# yum -y install qpress
qpress 来自于 percona-release-x86_64 这个yum 库
有可能出现问题:
The GPG keys listed for the "Percona-Release YUM repository - x86_64" repository are already installed but they are not correct for this package.
Check that the correct key URLs are configured for this repository.
Failing package is: Percona-Server-shared-56-5.6.44-rel86.0.el7.x86_64
GPG Keys are configured as: file:///etc/pki/rpm-gpg/RPM-GPG-KEY-Percona
解决方案:
yum -y install qpress --nogpgcheck遇到这种问题,解决方案同此,加 --nogpgcheck 。下同。
这个问题往往源于用户仓库中的rpm包有时候是用户自己制作的,或者从第三方获取,这个时候问题就会出现。从字面上理解,是“为“***”源码仓库出示的GPG密钥已经安装,但不正确”。
首先,GPG密钥存在的目的是处于安全和规范考虑,RedHat在发布软件包的时候会根据软件包生成对应密钥,当用户安装软件包的时候会根据密钥校验软件包。
若是用yum安装,当/etc/yum.conf文件有如下配置项目时。
gpgcheck=1
yum安装的时候就会校验软件包是否是官方发布的。当然可以给yum添加--nogpgcheck来强制安装。
sudo yum install *** --nogpgcheck
安装 percona 组件:
安装percona组件1 Percona-XtraDB-Cluster-shared-57
yum -y install Percona-XtraDB-Cluster-shared-57 --nogpgcheck
安装percona组2 Percona-XtraDB-Cluster-shared-compat-57
yum -y install Percona-XtraDB-Cluster-shared-compat-57 --nogpgcheck
安装percona组件3 percona-xtrabackup-24
yum -y install percona-xtrabackup-24 --nogpgcheck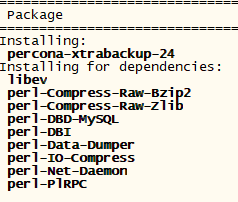
安装percona组件4 Percona-XtraDB-Cluster-client-57
yum -y install Percona-XtraDB-Cluster-client-57 --nogpgcheck
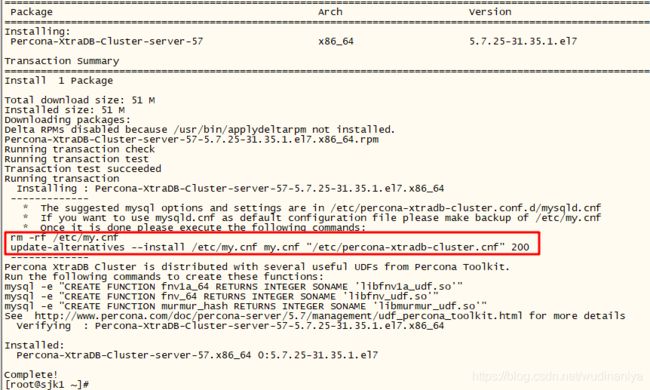
安装percona组件5 Percona-XtraDB-Cluster-server-57
yum -y install Percona-XtraDB-Cluster-server-57 --nogpgcheck
yum 安装时会提示UDFs功能,根据需要可以在mysql启动后执行以下语句:
Percona XtraDB Cluster is distributed with several useful UDFs from Percona Toolkit.
Run the following commands to create these functions:
mysql -e "CREATE FUNCTION fnv1a_64 RETURNS INTEGER SONAME 'libfnv1a_udf.so'"
mysql -e "CREATE FUNCTION fnv_64 RETURNS INTEGER SONAME 'libfnv_udf.so'"
mysql -e "CREATE FUNCTION murmur_hash RETURNS INTEGER SONAME 'libmurmur_udf.so'"
安装 Percona-XtraDB-Cluster-server-57 后,会删除旧的 /etc/my.cnf(如果有的话),并生成新的
![]() 和
和 ![]()
新的 my.cnf 内容如下:

安装percona组件6 Percona-XtraDB-Cluster-57
yum -y install Percona-XtraDB-Cluster-57 --nogpgcheck
yum 安装 Percona组件 顺序汇总:

三 配置mysql及集群配置文件
默认主配置文件 /etc/my.cnf 文件内容如下:
[root@sjk1 ~]# more /etc/my.cnf
#
# The Percona XtraDB Cluster 5.7 configuration file.
#
#
# * IMPORTANT: Additional settings that can override those from this file!
# The files must end with '.cnf', otherwise they'll be ignored.
# Please make any edits and changes to the appropriate sectional files
# included below.
#
!includedir /etc/my.cnf.d/
!includedir /etc/percona-xtradb-cluster.conf.d/而 /etc/my.cnf.d/ 下为空的,/etc/percona-xtradb-cluster.conf.d/下有3个配置文件:
[root@sjk1 ~]# ls /etc/my.cnf.d
[root@sjk1 ~]# ls /etc/percona-xtradb-cluster.conf.d/
mysqld.cnf mysqld_safe.cnf wsrep.cnf所以,mysql及集群的配置文件修改,主要包括3个配置文件内容的修改:mysqld.cnf、mysqld_safe.cnf、wsrep.cnf
下面我将采用直接改动主配置文件my.cnf,而不去改动mysqld.cnf、mysqld_safe.cnf、wsrep.cnf
其中 mysqld_safe.cnf的默认内容如下:
[root@sjk1 percona-xtradb-cluster.conf.d]# more mysqld_safe.cnf
#
# The Percona Server 5.7 configuration file.
#
# One can use all long options that the program supports.
# Run program with --help to get a list of available options and with
# --print-defaults to see which it would actually understand and use.
#
# For explanations see
# http://dev.mysql.com/doc/mysql/en/server-system-variables.html
[mysqld_safe]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/lib/mysql/mysql.sock
nice = 0
以第一个节点的 my.cnf 举例。内容更改如下:
[root@sjk1 etc]# cat my.cnf
[mysqld]
#cluster parameters
#wsrep lib
wsrep_provider=/usr/lib64/libgalera_smm.so
#cluster address,first time using blank,then fill with the real node ips
wsrep_cluster_address=gcomm://192.168.158.144,192.168.158.145,192.168.158.146
#wsrep_cluster_address=gcomm://
#must be row
binlog_format=ROW
#only support innodb
default_storage_engine=InnoDB
#must to 2
innodb_autoinc_lock_mode=2
#this node ip address
wsrep_node_address=192.168.158.144
#our cluster name,must be unique in the whole cluster
wsrep_cluster_name=honor-production
wsrep_node_name=honor_node1
#sst syc method
wsrep_sst_method=xtrabackup-v2
#sst user and password
wsrep_sst_auth="sstuser:s3cret"
#transaction cache for Galera replication,larger size,bigger chance to use ist
wsrep_provider_options="gcache.size=300M;gcache.page_size=300M"
#replication transactions threads for client
wsrep_slave_threads=6
#change it to RSU,when big change like alter table ,change column name, add index happened, otherwise it will infute the whole cluster,
wsrep_OSU_method=TOI
#db parameters
log-slave-updates = 1
server-id=144
log-bin=bin-log
expire_logs_days = 7
skip-name-resolve
skip-host-cache
character-set-server=utf8
#the data files go to
datadir=/mysql
#men cache,up tp 60% of whole physical memory,change it when deploy to production env
innodb_buffer_pool_size=200M
#each log file
innodb_log_file_size=256M
#each table in a seprate storage file
innodb_file_per_table=1
#log buffer
innodb_flush_log_at_trx_commit=2
#too small will cause commit error
max_allowed_packet=20M
#it will first read cache,then go to open table
table_open_cache=1024
#increase sort by
sort_buffer_size=4M
join_buffer_size=8M
#increase table sequence scan
read_buffer_size=10M
#1g->8
thread_cache_size=320
tmp_table_size=512M
wait_timeout=108000
max_connections = 5000
query_cache_type=1
query_cache_limit=2M
query_cache_size=512M
slow_query_log=ON
general_log=ON
long_query_time=2my.cnf简化后的通用配置如下(上面的配置不通用,硬件配置低的话会出问题):
#
# The Percona XtraDB Cluster 5.7 configuration file.
#
#
# * IMPORTANT: Additional settings that can override those from this file!
# The files must end with '.cnf', otherwise they'll be ignored.
# Please make any edits and changes to the appropriate sectional files
# included below.
#
[mysqld]
datadir=/mysql
port=3306
#socket=/mysql/mysql-node1.sock #socket不要指定,配了反而会出问题,让它自己去生成 /var/lib/mysql/mysql.sock
### 可以不指定pid-file路径,默认生成路径为 $datadir/$hostname.pid ####
pid-file=/mysql/mysql-node1.pid
### 建议指定log-error路径,不指定log-error的话,也会生成一个 $datadir/$hostname.err,但该文件中是没有临时密码的,导致无法登录数据库 ####
log-error=/mysql/mysql-node1.err
default_storage_engine=InnoDB
character-set-server=utf8
log_timestamps=SYSTEM #默认是UTC,需要我们指定为SYSTEM
max_connections=5000
#server-id 服务器唯一ID,默认是1,一般取IP最后一段
server-id=144
#启用二进制日志
log-bin=bin-log
binlog_format=ROW
#主键自增长不锁表,只能设置为2,设置为0或1时会无法正确处理死锁问题
innodb_autoinc_lock_mode=2
expire_logs_days=7
log-slave-updates=1
#跳过DNS解析
#跳过DNS主机名查找,提高响应速度
skip-name-resolve
#跳过主机名缓存
skip-host-cache
wsrep_provider=/usr/lib64/libgalera_smm.so
wsrep_cluster_name=pxc-cluster
wsrep_node_name=node1
# Galera不指定端口的话,默认 4567
wsrep_cluster_address=gcomm://192.168.158.144:5020,192.168.158.145:5020,192.168.158.146:5020
wsrep_provider_options="base_port=5020;"
wsrep_node_address=192.168.158.144:5020
wsrep_slave_threads=6
#sst syc method
wsrep_sst_method=xtrabackup-v2
#wsrep_sst_method=rsync
#sst user and password
wsrep_sst_auth="sstuser:s3cret"
#开启普通的sql日志(如果是集群,只开启一个节点即可,保证能有日志查就行了,其他节点可开可不开)
general_log=on #默认为off 关闭 ,开启后会生成 $datadir/$hostname.log 文件,记录执行的每一条sql,就连commit这种sql语句都会记录下来
#添加慢查询日志
#log_output=file #不写的话默认是file.如果想将mysql慢查询日志写入表,则必须明确指定 log_output=table
slow_query_log=on #开启慢查询 #默认是不开启 off
#slow_query_log_file=/mysql/mysql-slow.log #不指定的话,默认值是 $datadir/$hostname-slow.log #指定的话,路径必须指定在 $datadir 目录下,否则设置slow_query_log=on无效
long_query_time=2 # 所有超过2s的sql都被记录下来
########如果需要还可以开启查询缓存query_cache,默认是不开启##########
四 启动PXC集群
1 启动第一个节点


第一个节点启动必须用下面这种方式:
systemctl start [email protected][root@sjk1 ~]# systemctl start [email protected]
注意:启动第一个节点前要先 setenforce 0
官网解释:
The SELinux security module can constrain access to data for Percona XtraDB cluster. The best solution is to change the mode from enforcing to permissive by running to following command:
setenforce 0
This only changes the mode at runtime. To run SELinux in permissive mode after a reboot, set SELINUX=permissive in the /etc/selunux/config configuration file.
sed -i "s/^SELINUX\=enforcing/SELINUX\=disabled/g" /etc/selinux/config
启动第一个节点后,
在$datadir 目录下生成如下文件和文价夹:

查看mysql进程信息如下:

从进程信息,可知
错误日志文件是mysql-node1.err
定位错误日志文件位置:
![]()
从错误日志文件 xxxx.err 中找到临时登录密码:
怎么找到这个临时密码呢?
使用命令:
grep 'temporary password' /mysql/mysql-node1.err即可查询到类似于如下的一条日志记录:
[root@sjk1 ~]# grep 'temporary password' /mysql/mysql-node1.err
2019-08-16T09:56:01.517698Z 1 [Note] A temporary password is generated for root@localhost: #+UC&*K7pHrE#+UC&*K7pHrE即为登录密码。使用这个随机密码登录进去,然后修改密码,使用命令:
mysql -uroot -p
[root@sjk2 ~]# mysql -uroot -p
Enter password: # 在这里输入密码
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9
Server version: 5.7.25-28-57-log
......
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>更改root本地密码,否则不能执行其他sql语句:比如创建sstuser用户
![]()
更改本地root密码:
mysql> alter user root@localhost identified by 'sdbrk';
Query OK, 0 rows affected (0.10 sec)创建用于节点直接同步数据的sstuser用户并赋权(用户名和密码要和my.cnf中配置的一致:wsrep_sst_auth="sstuser:s3cret",该账户只需在节点1创建即可,且账户的host为localhost):
![]()

mysql> create user 'sstuser'@'localhost' identified by 's3cret';
Query OK, 0 rows affected (0.01 sec)
mysql> grant reload,lock tables,process,replication client on *.* to sstuser@localhost;
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> quit
Bye查看pxc集群当前状态
To make sure that the cluster has been initialized,run the following:
mysql> show status like 'wsrep%';
+----------------------------------+--------------------------------------+
| Variable_name | Value |
+----------------------------------+--------------------------------------+
| wsrep_local_state_uuid | 6cb10f99-c3c2-11e9-a912-e6a1e0e11c9f |
| wsrep_protocol_version | 9 |
| wsrep_last_applied | 4 |
| wsrep_last_committed | 4 |
| wsrep_replicated | 4 |
......
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
......
| wsrep_incoming_addresses | 192.168.158.144:3306 |
| wsrep_cluster_weight | 1 |
| wsrep_desync_count | 0 |
| wsrep_evs_delayed | |
| wsrep_evs_evict_list | |
| wsrep_evs_repl_latency | 0/0/0/0/0 |
| wsrep_evs_state | OPERATIONAL |
| wsrep_gcomm_uuid | 6caede01-c3c2-11e9-8eac-f32a75f0b367 |
| wsrep_cluster_conf_id | 1 |
| wsrep_cluster_size | 1 |
| wsrep_cluster_state_uuid | 6cb10f99-c3c2-11e9-a912-e6a1e0e11c9f |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 0 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy |
| wsrep_provider_version | 3.35(rddf9876) |
| wsrep_ready | ON |
+----------------------------------+--------------------------------------+
71 rows in set (0.00 sec) 参数 wsrep_cluster_size 的值为1,显示当前pxc集群只有一个节点。在初始化集群过程中,要注意第一个节点的服务的启动方式。下一步就是启动其他节点将其他节点加入集群。
2 启动其他节点
启动第二、三个节点:
其余两个节点按照正常启动mysql方式即可,不需要按照节点1的bootstrap启动方式:
systemctl start mysqld启动后,将自动创建/mysql/目录并生成相应mysql文件,密码自动和第一个节点的密码同步,因此第二、第三个节点可以直接用 root/sdbrk 进行登录。
第一个节点$datadir目录下将多出一个文件 innobackup.backup.log
![]()
第二、三个节点自动创建$datadir目录,不过相对第一个节点略有不同,少个mysql_safe.pid文件,多出了如下红线圈起的文件


三个节点的进程状态:
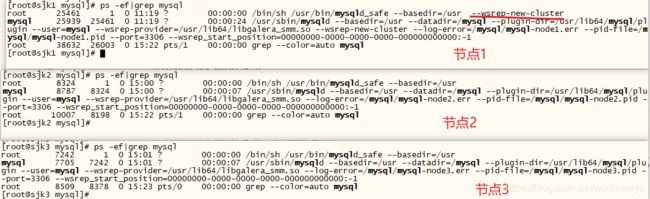
After the server starts, it should receive SST automatically. To check the status of the second node, run the following:
mysql> show status like 'wsrep%';节点都启动完后,若在一个节点上进行sql操作,其他节点也会同步更新。比如在任一个节点更改本地root密码,其他节点也自动更新自己的root密码。
三个节点都启动后,在任一个节点上再次查看集群状态:
mysql> show status like 'wsrep%';
+----------------------------------+----------------------------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------------------------+
| wsrep_local_state_uuid | 6cb10f99-c3c2-11e9-a912-e6a1e0e11c9f |
| wsrep_protocol_version | 9 |
| wsrep_last_applied | 4 |
| wsrep_last_committed | 4 |
| wsrep_replicated | 4 |
......
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
......
| wsrep_incoming_addresses | 192.168.158.145:3306,192.168.158.144:3306,192.168.158.146:3306 |
| wsrep_cluster_weight | 3 |
| wsrep_desync_count | 0 |
| wsrep_evs_delayed | |
| wsrep_evs_evict_list | |
| wsrep_evs_repl_latency | 0/0/0/0/0 |
| wsrep_evs_state | OPERATIONAL |
| wsrep_gcomm_uuid | 6caede01-c3c2-11e9-8eac-f32a75f0b367 |
| wsrep_cluster_conf_id | 4 |
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | 6cb10f99-c3c2-11e9-a912-e6a1e0e11c9f |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 1 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy |
| wsrep_provider_version | 3.35(rddf9876) |
| wsrep_ready | ON |
+----------------------------------+----------------------------------------------------------------+
71 rows in set (0.00 sec)
其中
wsrep_incoming_addresses的值为 192.168.158.145:3306,192.168.158.144:3306,192.168.158.146:3306
wsrep_cluster_size 的值为 3 ,说明此时的集群节点数为3
如果在这个过程中,节点2或者节点3的mysql服务无法启动,可以从以下几个方向着手:
(1)配置文件错误
(2)防火墙没有开放相应的端口,比如默认的4567端口(我这里指定的5020)
(3)忘记进行授权账号
(4)xtrabackup没有安装或者安装有问题。
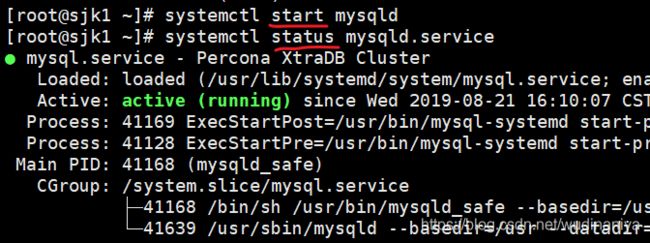
两个节点按正常方式启动mysql后,会按照配置文件自动加入PXC集群。当所有节点添加完毕后,将节点1的mysql服务关闭,然后再以正常方式启动mysql服务:
systemctl stop [email protected]
systemctl start mysqld
systemctl status mysqld执行命令的相关截图如下:


再次在1节点上查看集群状态。集群状态仍为3
mysql> show status like 'wsrep_clu%';
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_weight | 3 |
| wsrep_cluster_conf_id | 11 |
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | 6cb10f99-c3c2-11e9-a912-e6a1e0e11c9f |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+
5 rows in set (0.01 sec)五 同步测试
首先在节点上创建数据库,并写入数据:
[root@sjk1 ~]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10
Server version: 5.7.25-28-57-log Percona XtraDB Cluster (GPL), Release rel28, Revision a2ef85f, WSREP version 31.35, wsrep_31.35
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> create database percona;
Query OK, 1 row affected (0.10 sec)
mysql> use percona;
Database changed
mysql> create table example (node_id int primary key,node_name varchar(30));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into percona.example values (1,'percona1');
Query OK, 1 row affected (0.34 sec)
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
+---------+-----------+
1 row in set (0.00 sec)
mysql> quit
Bye
[root@sjk1 ~]# 在节点2和节点3上验证数据是否同步:
# 节点2
[root@sjk2 mysql]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
......
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
+---------+-----------+
1 row in set (0.00 sec)
# 节点3
[root@sjk3 mysql]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
......
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
+---------+-----------+
1 row in set (0.00 sec)
然后分别在节点2和节点3上写入数据:
# 节点2上写入数据
mysql> insert into percona.example values (2,'percona2');
Query OK, 1 row affected (0.09 sec)
# 节点3上写入数据
mysql> insert into percona.example values (3,'percona3');
Query OK, 1 row affected (0.08 sec)
在节点1上验证数据是否同步:
[root@sjk1 ~]# mysql -uroot -p
Enter password:
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
| 2 | percona2 |
| 3 | percona3 |
+---------+-----------+
3 rows in set (0.00 sec)PXC集群内的所有节点均可写入并同步复制到其他节点。
此时,如果停止节点1的mysql服务,然后在其他节点写入数据:
[root@sjk1 ~]# systemctl stop mysqld
[root@sjk1 ~]# systemctl status mysqld
● mysql.service - Percona XtraDB Cluster
Loaded: loaded (/usr/lib/systemd/system/mysql.service; enabled; vendor preset: disabled)
Active: inactive (dead) since Wed 2019-08-21 16:45:52 CST; 8s ago
Process: 43546 ExecStopPost=/usr/bin/mysql-systemd stop-post (code=exited, status=0/SUCCESS)
Process: 43502 ExecStop=/usr/bin/mysql-systemd stop (code=exited, status=0/SUCCESS)
Process: 41169 ExecStartPost=/usr/bin/mysql-systemd start-post $MAINPID (code=exited, status=0/SUCCESS)
Process: 41168 ExecStart=/usr/bin/mysqld_safe --basedir=/usr (code=exited, status=0/SUCCESS)
Process: 41128 ExecStartPre=/usr/bin/mysql-systemd start-pre (code=exited, status=0/SUCCESS)
Main PID: 41168 (code=exited, status=0/SUCCESS)
在节点2上查看集群状态,并在节点2写入数据:
mysql> show status like 'wsrep_cluster%';
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_weight | 2 |
| wsrep_cluster_conf_id | 14 |
| wsrep_cluster_size | 2 |
| wsrep_cluster_state_uuid | 6cb10f99-c3c2-11e9-a912-e6a1e0e11c9f |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+
5 rows in set (0.01 sec)
mysql> insert into percona.example values (4,'percona4');
Query OK, 1 row affected (0.01 sec)
wsrep_cluster_size 显示此时的集群节点数为2。当再次启动节点1的mysql服务,在节点1上检查节点2最近写入的数据是否完成同步:
[root@sjk1 ~]# systemctl start mysqld.service
[root@sjk1 ~]# mysql -uroot -psdbrk
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
| 2 | percona2 |
| 3 | percona3 |
| 4 | percona4 |
+---------+-----------+
4 rows in set (0.01 sec)
由此可见,当集群内的某个节点掉线后,其他节点仍可以正常的工作,新写入的数据会在该节点重新上线后完成同步(即使该节点停掉后对数据目录进行过清空),以实现PXC的高可用。
针对重新上线的节点,PXC有两种方式完成数据传输以保证数据同步:State Snapshot Transfer (SST)和Incremental State Transfer (IST)。
SST通常用在当有新的节点加入PXC集群同时从已存在节点复制全部数据时采用,在PXC中有三种可用的方式完成SST过程:
– mysqldump
– rsync
– xtrabackup
mysqldump和rsync的缺点是在数据传输过程中法规,PXC集群将会变成只读模式,SST将会对数据库施加只读锁(FLUSH TABLES WITH READ LOCK)。而使用xtrabackup则不需要再数据同步过程中施加读锁,仅仅是同步.frm文件,类似于常规的备份。
IST用于只将数据的增量变化从一个节点复制到另一个节点。
尽管,如果SST使用xtrabackup不需要施加读锁,SST仍可能扰乱了服务的正常运行。而IST则不会。如果一个节点掉线时间较短,当再次上线,它将只会从其他节点获取掉线期间的数据变化部分。IST是在节点上使用缓存机制实现的。每个节点包含一个缓存,且环形缓冲区(大小是可配置的)存储最后N个变化,并且节点能够传输该缓存的一部分。显然,只有当传输所需的更改量小于N时,才可以执行IST,如果超过N,则加入的节点必须执行SST。
如果3个节点中挂了两个呢?恢复方式同上。
停掉2,3节点的mysql服务
systemctl stop mysql.service在1节点上插入数据
mysql> insert into percona.example values (5,'percona5');
Query OK, 1 row affected (0.00 sec)重启2,3节点,并在2节点上查看数据有没有同步
# 重启2节点
[root@sjk2 ~]# systemctl start mysqld
# 重启3节点
[root@sjk3 mysql]# systemctl start mysql
# 重启2节点后,登上去,查看数据有没有同步(结果是肯定同步啦)
[root@sjk2 mysql]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9
Server version: 5.7.25-28-57-log Percona XtraDB Cluster (GPL), Release rel28, Revision a2ef85f, WSREP version 31.35, wsrep_31.35
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
| 2 | percona2 |
| 3 | percona3 |
| 4 | percona4 |
| 5 | percona5 |
+---------+-----------+
5 rows in set (0.00 sec)如果三个节点全挂?此时恢复方式不太一样
mysql HA集群在断网过久或者所有节点都down了之后该怎么恢复呢?
等三台机器恢复网络通讯后,因为此时的mysql已经异常无法加入集群,因此需要先保证所有的mysql都是down的(如果个别节点没死透,存在僵尸进程,3306,4567两个端口没全挂,那么手动杀掉该僵死进程)。然后删除第一个节点的 grastate.dat、galera.cache 两个文件(其他节点不用删)
[root@sjk1 mysql]# rm -rf grastate.dat galera.cache然后启动第一个节点(以初始化集群的方式)
[root@sjk1 ~]# systemctl start [email protected]启动后,查看集群状态
mysql> show status like 'wsrep_clus%';
+--------------------------+--------------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------------+
| wsrep_cluster_weight | 1 |
| wsrep_cluster_conf_id | 1 |
| wsrep_cluster_size | 1 |
| wsrep_cluster_state_uuid | 47a30425-c434-11e9-9a09-56429b062ebd |
| wsrep_cluster_status | Primary |
+--------------------------+--------------------------------------+
5 rows in set (0.01 sec)然后在其他两个节点上执行启动命令 systemctl start mysql , 必须等一台成功了,再其另一台
# 节点2
[root@sjk2 ~]# systemctl start mysql
# 节点3
[root@sjk3 mysql]# systemctl start mysql最后在mysql中执行 show status like 'wsrep%';
mysql> show status like 'wsrep%';
+----------------------------------+----------------------------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------------------------+
| wsrep_local_state_uuid | 47a30425-c434-11e9-9a09-56429b062ebd |
......
| wsrep_local_state_comment | Synced |
......
| wsrep_incoming_addresses | 192.168.158.144:3306,192.168.158.145:3306,192.168.158.146:3306 |
| wsrep_cluster_weight | 3 |
......
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | 47a30425-c434-11e9-9a09-56429b062ebd |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 0 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy |
| wsrep_provider_version | 3.35(rddf9876) |
| wsrep_ready | ON |
+----------------------------------+----------------------------------------------------------------+
71 rows in set (0.01 sec) 我们必须保证 wsrep_local_state_comment 为 Synced,wsrep_incoming_address 为三个mysql服务的ip:port,wsrep_cluster_size 为3(集群有几个节点就要保证为几)
查看数据有没有丢,如下所示:数据没丢:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| percona |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.51 sec)
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
| 2 | percona2 |
| 3 | percona3 |
| 4 | percona4 |
| 5 | percona5 |
+---------+-----------+
5 rows in set (0.75 sec)最后,停掉一节点,以普通方式启动。
接下来我们讲讲pxc数据库全备
xtrabackup全量备份:
innobackupex --user=root --password=sdbrk --socket=/var/lib/mysql/mysql.sock /home/backup/full执行该全备命令后,将会自动在/home/目录下生成 backup/full 子目录
执行全备命令后,数据库 $datadir 目录结构不会发生变化,比如不会新增一些文件或文件夹。
备份后 在备份目录/home/bakcup/full 下创建一个以时间命名的目录,这里面就是相关的备份文件,同样也可以看到我们创建的percona库
接下来再讲讲如何使用备份数据库进行还原
使用全备进行还原
1. 破环数据库
[root@sjk1 mysql]# rm -rf /mysql/*2. 恢复数据库
使用全备进行恢复,恢复之前需要保证数据目录是空的状态,否则会报错:

停掉服务,清空数据目录,进行数据恢复,修复属主属组关系,重启服务
[root@sjk1 ~]# systemctl stop mysql #停掉服务
[root@sjk1 ~]# innobackupex --apply-log --redo-only /home/backup/full/2019-08-22_09-56-24 # 对完全备份进行整理
......
190822 12:55:36 completed OK!
[root@sjk1 ~]# rm -rf /mysql/* #清空数据目录
[root@sjk1 ~]# innobackupex --defaults-file=/etc/my.cnf --copy-back /home/backup/full/2019-08-22_09-56-24 #全备恢复--还原数据库,还原前需确认数据库数据目录为空
......
190822 13:06:41 [01] Copying ./mysql/plugin.frm to /mysql/mysql/plugin.frm
190822 13:06:41 [01] ...done
190822 13:06:41 [01] Copying ./mysql/servers.frm to /mysql/mysql/servers.frm
190822 13:06:41 [01] ...done
190822 13:06:41 [01] Copying ./mysql/tables_priv.frm to /mysql/mysql/tables_priv.frm
190822 13:06:41 [01] ...done
190822 13:06:41 [01] Copying ./mysql/tables_priv.MYI to /mysql/mysql/tables_priv.MYI
190822 13:06:41 [01] ...done
190822 13:06:41 [01] Copying ./mysql/tables_priv.MYD to /mysql/mysql/tables_priv.MYD
......
190822 13:06:42 [01] Copying ./performance_schema/session_status.frm to /mysql/performance_schema/session_status.frm
190822 13:06:42 [01] ...done
190822 13:06:42 [01] Copying ./ib_buffer_pool to /mysql/ib_buffer_pool
190822 13:06:42 [01] ...done
190822 13:06:42 [01] Copying ./xtrabackup_info to /mysql/xtrabackup_info
190822 13:06:42 [01] ...done
190822 13:06:42 [01] Copying ./xtrabackup_binlog_pos_innodb to /mysql/xtrabackup_binlog_pos_innodb
190822 13:06:42 [01] ...done
190822 13:06:42 [01] Copying ./xtrabackup_master_key_id to /mysql/xtrabackup_master_key_id
190822 13:06:42 [01] ...done
190822 13:06:42 [01] Copying ./xtrabackup_galera_info to /mysql/xtrabackup_galera_info
190822 13:06:42 [01] ...done
190822 13:06:42 completed OK!
[root@sjk1 ~]# chown -R mysql:mysql /mysql/ # 修复属主属组
[root@sjk1 ~]# systemctl start mysql # 启动服务
登录检查恢复情况
[root@sjk1 ~]# mysql -uroot -p # 登录检查恢复情况
Enter password:
......
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| percona |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> select * from percona.example;
+---------+-----------+
| node_id | node_name |
+---------+-----------+
| 1 | percona1 |
| 2 | percona2 |
| 3 | percona3 |
| 4 | percona4 |
| 5 | percona5 |
+---------+-----------+
5 rows in set (0.25 sec)
mysql>
注意:如果数据节点全挂,数据全丢的情况下如何恢复?步骤如下(6步):
1.停掉所有服务
2.清空有节点数据目录下的内容
3.在第一节点上:
innobackupex --apply-log --redo-only /root/full/2019-08-21_01-02-47
innobackupex --defaults-file=/etc/my.cnf --copy-back /home/backup/full/2019-08-22_09-56-24 #全备恢复--还原数据库,还原前需确认数据库数据目录为空
chown -R mysql:mysql /mysql/ # 修复属主属组
4.启动第一个节点
systemctl start [email protected]
5.启动其他节点(必须一个启动完再启动下一个)
systemctl start mysql
6.所有节点都启动完后,停掉第一个节点,然后以正常方式启动
[root@sjk1 mysql]# systemctl stop [email protected]
[root@sjk1 mysql]# systemctl start mysql