Elasticsearch聚合深入详解——对比Mysql实现
聚合认知前提
桶(Buckets)——满足特定条件的文档的集合
指标(Metrics)——对桶内的文档进行统计计算
SELECT COUNT(color)
FROM table
GROUP BY color
COUNT(color) 相当于指标。
GROUP BY color 相当于桶。
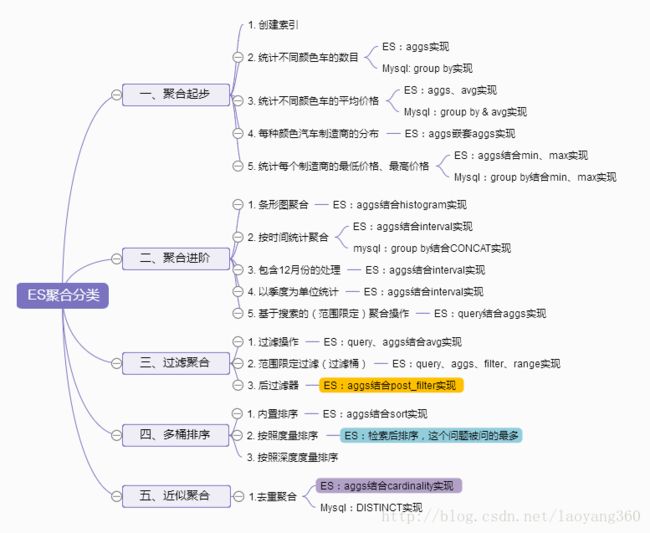
一、聚合起步
1、创建索引
1.1 创建索引DSL实现
put cars
POST /cars/transactions/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }1.2 创建mysql库表sql实现
CREATE TABLE `cars` (
`id` int(11) NOT NULL,
`price` int(11) DEFAULT NULL,
`color` varchar(255) DEFAULT NULL,
`make` varchar(255) DEFAULT NULL,
`sold` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2、统计不同颜色车的数目
2.1 统计不同颜色车的DSL实现
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"popular_colors" : {
"terms":{
"field": "color.keyword"
}
}
}
}返回结果:
lve
2.2 统计不同颜色的mysql实现
select color, count(color) as cnt from cars group by color order by cnt desc;返回结果:
red 4
green 2
blue 23、统计不同颜色车的平均价格
3.1 统计不同颜色车的平均价格DSL实现:
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"colors" : {
"terms":{
"field": "color.keyword"
},
"aggs":{
"avg_price":{
"avg": {
"field": "price"
}
}
}
}
}
}返回聚合结果:
lve
3.2 统计不同颜色车的平均价格sql实现:
select color, count(color) as cnt, avg(price) as avg_price from cars group by color order by cnt desc;
color cnt avg_price
red 4 32500.0000
green 2 21000.0000
blue 2 20000.00004、每种颜色汽车制造商的分布
4.1 统计每种颜色汽车制造商的分布dsl实现
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"colors" : {
"terms":{
"field": "color.keyword"
},
"aggs":{
"make":{
"terms":{
"field": "make.keyword"
}
}
}
}
}
}返回结果:
4.2 统计每种颜色汽车制造商的分布sql实现
说明:和dsl的实现不严格对应
select color, make from cars order by color;
color make
blue toyota
blue ford
green ford
green toyota
red bmw
red honda
red honda
red honda5、统计每个制造商的最低价格、最高价格
5.1 统计每个制造商的最低、最高价格的DSL实现
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"make_class" : {
"terms":{
"field": "make.keyword"
},
"aggs":{
"min_price":{
"min":{
"field": "price"
}
},
"max_price":{
"max":{
"field": "price"
}
}
}
}
}
}聚合结果:
5.2 统计每个制造商的最低、最高价格的sql实现
select make, min(price) as min_price, max(price) as max_price from cars group by make;
make min_price max_price
bmw 80000 80000
ford 25000 30000
honda 10000 20000
toyota 12000 15000二、聚合进阶
1、条形图聚合
1.1 分段统计每个区间的汽车销售价格总和
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"price" : {
"histogram":{
"field": "price",
"interval": 20000
},
"aggs":{
"revenue":{
"sum":{
"field": "price"
}
}
}
}
}
}汽车销售价格区间:定义为20000;
分段统计price和用sum统计。
1.2 多维度度量不同制造商的汽车指标
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"makes": {
"terms": {
"field": "make.keyword",
"size": 10
},
"aggs": {
"stats": {
"extended_stats": {
"field": "price"
}
}
}
}
}
}输出截取片段:
{
"key": "ford",
"doc_count": 2,
"stats": {
"count": 2,
"min": 25000,
"max": 30000,
"avg": 27500,
"sum": 55000,
"sum_of_squares": 1525000000,
"variance": 6250000,
"std_deviation": 2500,
"std_deviation_bounds": {
"upper": 32500,
"lower": 22500
}
}
}2、按时间统计聚合
2.1 按月份统计制造商汽车销量dsl实现
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales":{
"date_histogram":{
"field":"sold",
"interval":"month",
"format":"yyyy-MM-dd"
}
}
}
}返回结果:
2.2 按月份统计制造商汽车销量sql实现
SELECT make, count(make) as cnt, CONCAT(YEAR(sold),',',MONTH(sold)) AS data_time
FROM `cars`
GROUP BY YEAR(sold) DESC,MONTH(sold)
查询结果如下:
make cnt data_time
bmw 1 2014,1
ford 1 2014,2
ford 1 2014,5
toyota 1 2014,7
toyota 1 2014,8
honda 1 2014,10
honda 2 2014,112.3 包含12月份的处理DSL实现
以上2.1 中没有12月份的统计结果显示。
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales":{
"date_histogram":{
"field":"sold",
"interval":"month",
"format":"yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds":{
"min":"2014-01-01",
"max":"2014-12-31"
}
}
}
}
}2.4 以季度为单位统计DSL实现
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales":{
"date_histogram":{
"field":"sold",
"interval":"quarter",
"format":"yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds":{
"min":"2014-01-01",
"max":"2014-12-31"
}
},
"aggs":{
"per_make_sum":{
"terms":{
"field": "make.keyword"
},
"aggs":{
"sum_price":{
"sum":{ "field": "price"}
}
}
},
"top_sum": {
"sum": {"field":"price"}
}
}
}
}
}2.5 基于搜索的(范围限定)聚合操作
2.5.1 基础查询聚合
GET /cars/transactions/_search
{
"query" : {
"match" : {
"make.keyword" : "ford"
}
},
"aggs" : {
"colors" : {
"terms" : {
"field" : "color.keyword"
}
}
}
}对应的sql实现:
select make, color from cars
where make = "ford";
结果返回如下:
make color
ford green
ford blue三、过滤聚合
1. 过滤操作
统计全部汽车的平均价钱以及单品平均价钱;
GET /cars/transactions/_search
{
"size" : 0,
"query" : {
"match" : {
"make.keyword" : "ford"
}
},
"aggs" : {
"single_avg_price": {
"avg" : { "field" : "price" }
},
"all": {
"global" : {},
"aggs" : {
"avg_price": {
"avg" : { "field" : "price" }
}
}
}
}
}等价于:
select make, color, avg(price) from cars
where make = "ford" ;
select avg(price) from cars;2、范围限定过滤(过滤桶)
我们可以指定一个过滤桶,当文档满足过滤桶的条件时,我们将其加入到桶内。
GET /cars/transactions/_search
{
"size" : 0,
"query":{
"match": {
"make": "ford"
}
},
"aggs":{
"recent_sales": {
"filter": {
"range": {
"sold": {
"from": "now-100M"
}
}
},
"aggs": {
"average_price":{
"avg": {
"field": "price"
}
}
}
}
}
}mysql的实现如下:
select *, avg(price) from cars where period_diff(date_format(now() , '%Y%m') , date_format(sold, '%Y%m')) > 30
and make = "ford";
mysql查询结果如下:
id price color make sold avg
3 30000 green ford 2014-05-18 27500.00003、后过滤器
只过滤搜索结果,不过滤聚合结果——post_filter实现
GET /cars/transactions/_search
{
"query": {
"match": {
"make": "ford"
}
},
"post_filter": {
"term" : {
"color.keyword" : "green"
}
},
"aggs" : {
"all_colors": {
"terms" : { "field" : "color.keyword" }
}
}
}post_filter 会过滤搜索结果,只展示绿色 ford 汽车。这在查询执行过 后 发生,所以聚合不受影响。
小结
选择合适类型的过滤(如:搜索命中、聚合或两者兼有)通常和我们期望如何表现用户交互有关。选择合适的过滤器(或组合)取决于我们期望如何将结果呈现给用户。
- 在 filter 过滤中的 non-scoring 查询,同时影响搜索结果和聚合结果。
- filter 桶影响聚合。
- post_filter 只影响搜索结果。
四、多桶排序
4.1 内置排序
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"colors" : {
"terms" : {
"field" : "color.keyword",
"order": {
"_count" : "asc"
}
}
}
}
}4.2 按照度量排序
以下是按照汽车平均售价的升序进行排序。
过滤条件:汽车颜色;
聚合条件:平均价格;
排序条件:汽车的平均价格升序。
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"colors" : {
"terms" : {
"field" : "color.keyword",
"order": {
"avg_price" : "asc"
}
},
"aggs": {
"avg_price": {
"avg": {"field": "price"}
}
}
}
}
}多条件聚合后排序如下所示:
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"colors" : {
"terms" : {
"field" : "color.keyword",
"order": {
"stats.variance" : "asc"
}
},
"aggs": {
"stats": {
"extended_stats": {"field": "price"}
}
}
}
}
}4.3 基于“深度”的度量排序
太复杂,不推荐!
五、近似聚合
cardinality的含义是“基数”;
5.1 统计去重后的数量
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"distinct_colors" : {
"cardinality" : {
"field" : "color.keyword"
}
}
}
}类似于:
SELECT COUNT(DISTINCT color) FROM cars;以下:
以月为周期统计;
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"months" : {
"date_histogram": {
"field": "sold",
"interval": "month"
},
"aggs": {
"distinct_colors" : {
"cardinality" : {
"field" : "color.keyword"
}
}
}
}
}
}六、doc values解读
在 Elasticsearch 中,doc values 就是一种列式存储结构,默认情况下每个字段的 doc values 都是激活的,doc values 是在索引时创建的,当字段索引时,Elasticsearch 为了能够快速检索,会把字段的值加入倒排索引中,同时它也会存储该字段的 doc values。
Elasticsearch 中的 doc vaules 常被应用到以下场景:
- 1)对一个字段进行排序
- 2)对一个字段进行聚合
- 3)某些过滤,比如地理位置过滤
- 4) 某些与字段相关的脚本计算因为文档值被序列化到磁盘,我们可以依靠操作系统的帮助来快速访问。当 working set 远小于节点的可用内存,系统会自动将所有的文档值保存在内存中,使得其读写十分高速;
当其远大于可用内存,操作系统会自动把 doc values 加载到系统的页缓存中,从而避免了 jvm 堆内存溢出异常。
——————————————————————————————————
更多ES相关实战干货经验分享,请扫描下方【铭毅天下】微信公众号二维码关注。
(每周至少更新一篇!)

和你一起,死磕Elasticsearch!
——————————————————————————————————
2018.1.12 21:50 于家中床前
作者:铭毅天下
转载请标明出处,原文地址:
http://blog.csdn.net/laoyang360/article/details/79048455
如果感觉本文对您有帮助,请点击‘顶’支持一下,您的支持是我坚持写作最大的动力,谢谢!