flink知识总结
1. 什么是flink?
Flink 能够提供毫秒级别的延迟,同时保证了数据处理的低延迟、高吞吐和结果的正确性,还提供 了丰富的时间类型和窗口计算、Exactly-once 语义支持,另外还可以进行状态管理,并提供 了 CEP(复杂事件处理)的支持。
2. Flink 的重要特点?
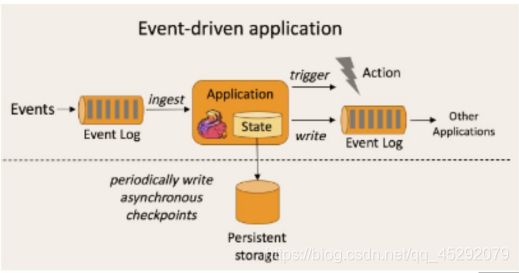
事件驱动
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 kafka 为 代表的消息队列几乎都是事件驱动型应用。 与之不同的就是 SparkStreaming 微批次,如图:

事件驱动型:
流与批的世界观
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计 算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统 传输的每个数据项执行操作,一般用于实时统计。
分层API
简单说越想上的API的代码越好写,越靠下的代码越多

3. 什么是有界流和无界流?
在 spark 的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实 时数据是由一个一个无限的小批次组成的。
而在 flink 的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数 据是一个没有界限的流,这就是所谓的有界流和无界流。
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并 提供数据,必须连续处理无界流,也就是说必须在获取后立即处理 event。对于无界 数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不 会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取 event,以 便能够推断结果完整性。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前 通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有 界数据集进行排序,有界流的处理也称为批处理。
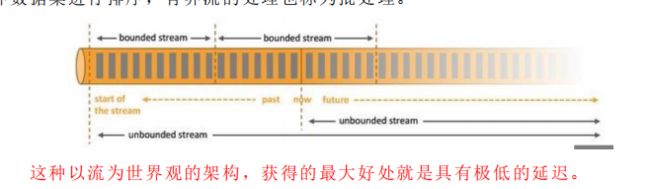
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
4. flink的其他特点?

5. flink和sparkStreaming 对比?

6. spark DAG 如何划分stage?
Spark会根据shuffle/宽依赖使用回溯算法来对DAG进行Stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的stage/阶段中
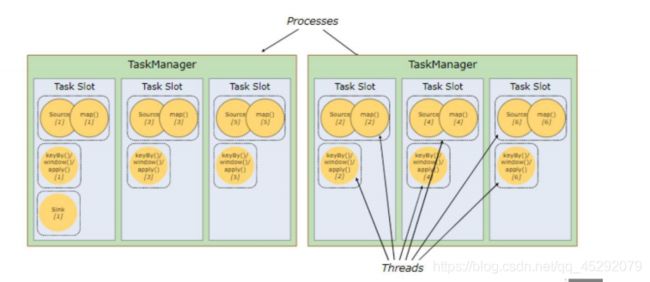
7. flink 运行的组件?
Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作: 作业管理器(JobManager)、
资源管理器(ResourceManager)、
任务管理器(TaskManager),
以及分发器(Dispatcher)。
因为 Flink 是用 Java 和 Scala 实现的,所以所有组件都会运行在 Java 虚拟机上。
8. jobmanager 的什么作用?
控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的 JobManager 所控制执行。JobManager 会先接收到要执行的应用程序,这个应用程序会包括: 作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它 资源的 JAR 包。JobManager 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫做 “执行图”(ExecutionGraph),包含了所有可以并发执行的任务。JobManager 会向资源管 理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上 的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager 上。而在运行过程中,JobManager 会负责所有需要中央协调的操作,比如说检 查点(checkpoints)的协调。
9. jobmanager接收到的应用程序包含?
作业图(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它 资源的 JAR 包。
JobManager 会把 JobGraph 转换成一个物理层面的数据流图,这个图被叫做 “执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
10. taskManager 的什么作用?
Flink 中的工作进程。通常在 Flink 中会有多个 TaskManager 运行,每一个 TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了 TaskManager 能够执行的任务数量。 启动之后,TaskManager 会向资源管理器注册它的插槽;收到资源管理器的指令后, TaskManager 就会将一个或者多个插槽提供给 JobManager 调用。JobManager 就可以向插槽 分配任务(tasks)来执行了。在执行过程中,一个 TaskManager 可以跟其它运行同一应用程 序的 TaskManager 交换数据。
11. resourceManager的作用?
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是 Flink 中 定义的处理资源单元。Flink 为不同的环境和资源管理工具提供了不同资源管理器,比如 YARN、Mesos、K8s,以及 standalone 部署。当 JobManager 申请插槽资源时,ResourceManager 会将有空闲插槽的 TaskManager 分配给 JobManager。如果 ResourceManager 没有足够的插槽 来满足 JobManager 的请求,它还可以向资源提供平台发起会话,以提供启动 TaskManager 进程的容器。另外,ResourceManager 还负责终止空闲的 TaskManager,释放计算资源。
12. flink的资源管理器有哪些?
YARN、Mesos、K8s,以及 standalone 部署。
13. Dispatcher的作用?
他并不是必需的

14. taskManager 通过什么控制task数量?
slots
15. flink 是否允许任务共享slot?
允许

16. flink程序包含那几部分?
source、transformation、sink

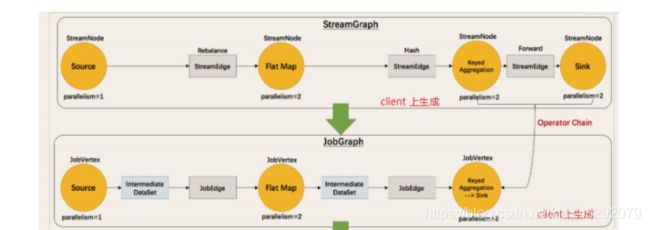
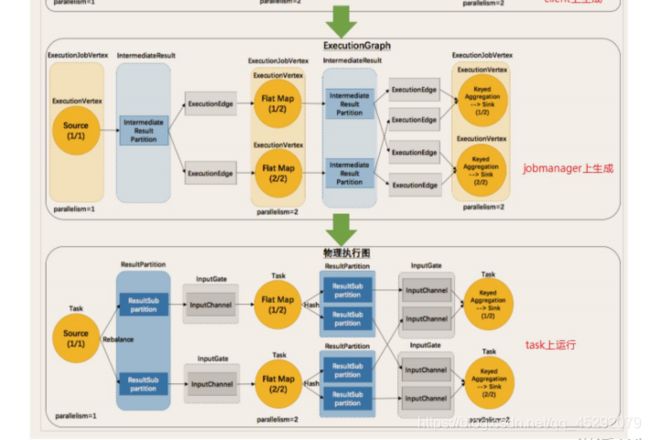
17. flink 的执行图包含那四部分?

18. 什么是streamgraph?

19. 什么是jobgraph?

20. 什么是executiongraph?

21. 什么是物理执行图?

总上如图所示
22. 什么是并行度?
![]()
23. 什么是stream最大并行度?

24. 算子的数据传输 2种形式?



25. flink 的任务链?
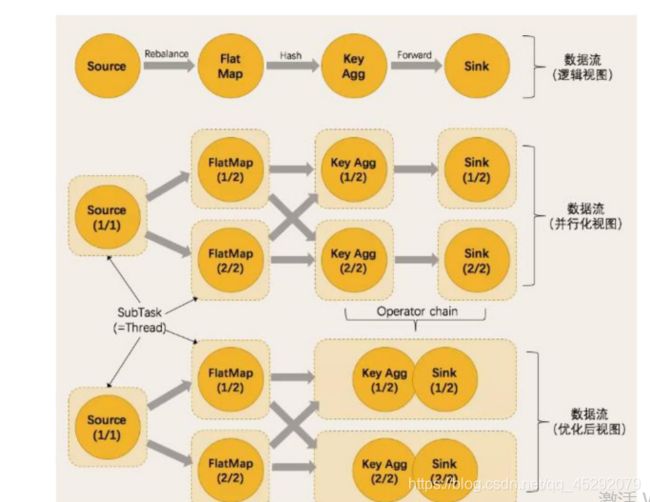
26. 满足任务链的要求?

注意两点:1.相同的并行度
2.one to one
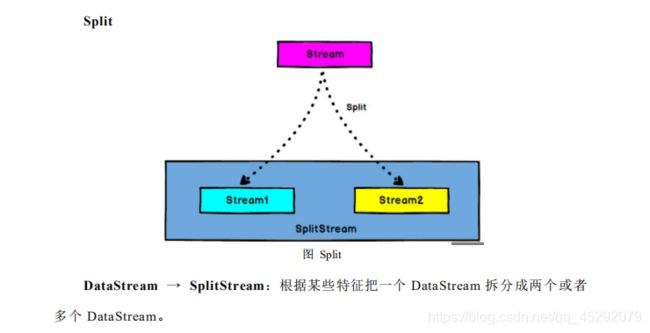
27. flink 流split ,select?
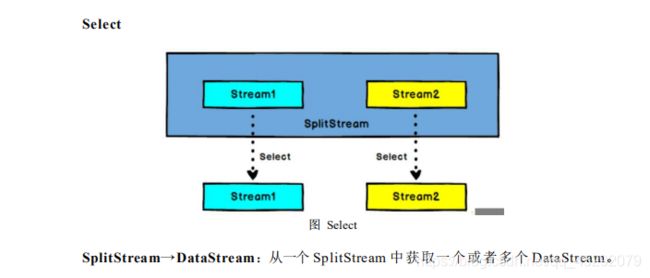
28. 流的connect 和 union 的区别?
1. Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap 中再去调整成为一样的。
2. Connect 只能操作两个流,Union 可以操作多个。
29. flink的数据类型?
Flink支持非常完善的数据类型,数据类型的描述信息都是由TypeInformation定义。TypeInformation主要作用是为了再Flink系统内有效的对数据结构类型进行管理,能够在分布式计算过程中对数据的数据类型进行管理和推断。同时基于对数据的类型信息管理,Flink内部对数据存储也进行了响应的性能优化。
-
原生数据类型
1.java原生基本类型(装箱)或String类型
2.java原生基本类型(装箱)或String类型对象的数组 -
Java Tuples类型
目前支持的类型字段上限是25,如果字段数量超过上限,可以通过继承Tuple类的方式进行拓展 -
Scala Case Class类型
包括Scala tuples类型,支持的字段上限是22 -
POJOs类型

5. Flink Value类型
Value数据类型实现了Value,其中包括read()和write()两个方法完成序列化和反序列化操作,相对于通用的序列化工具会有比较高效的性能。目前Flink提供了内建的Value类型有IntValue、DoubleValue已经StringValue等,用户可以结合原生数据类型和Value类型使用
- 特殊数据类型
30. 什么是富函数? 富函数有什么作用?
富函数”是 DataStream API 提供的一个函数类的接口,所有 Flink 函数类都 有其 Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一 些生命周期方法,所以可以实现更复杂的功能。
RichMapFunction
RichFlatMapFunction
RichFilterFunction …
Rich Function 有一个生命周期的概念。典型的生命周期方法有:
open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter 被调用之前 open()会被调用。
close()方法是生命周期中的最后一个调用的方法,做一些清理工作。 getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函 数执行的并行度,任务的名字,以及 state 状态
31. flink window的类型?

32. window function 有哪些?

33. flink 的时间语义?
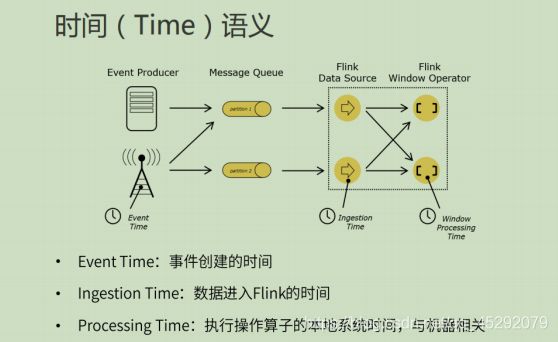
34. 乱序数据有什么影响?
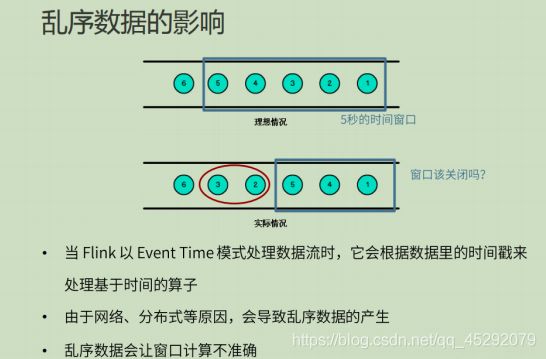
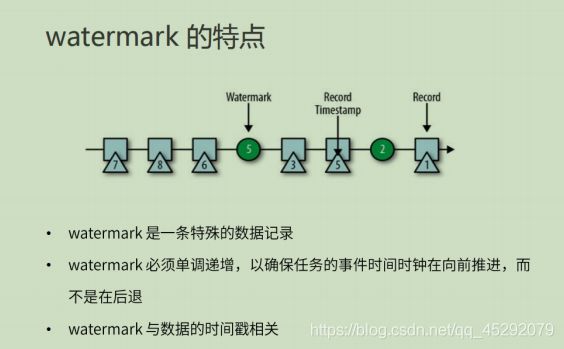
35. 什么是watermark?

36. watermark的特点?
37. flink 状态管理包含哪些?

38. flink 状态的类型?
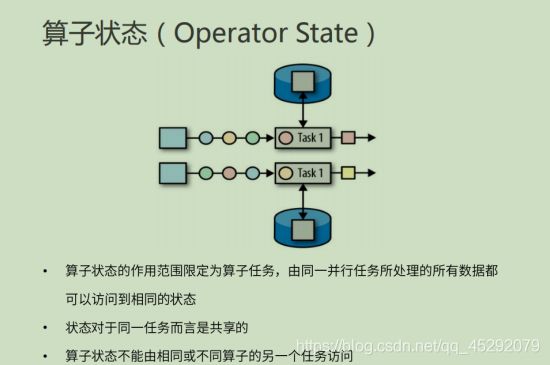
39. 算子状态的特点?
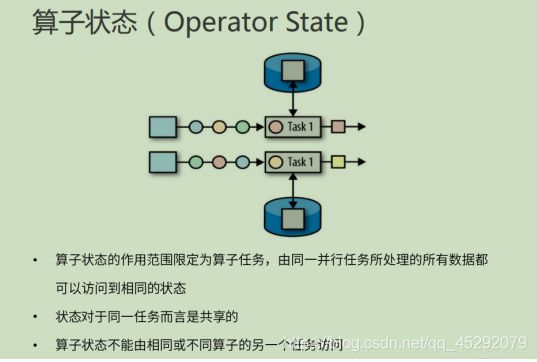
40. 算子状态的数据结构?

41. 键控状态特点?
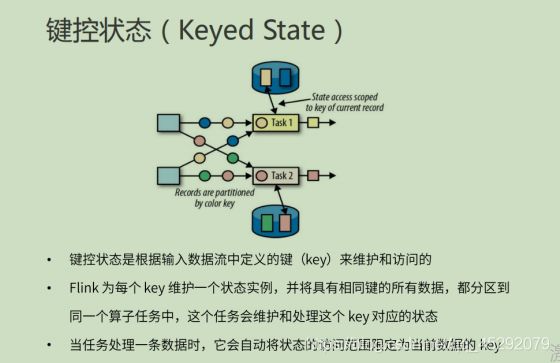
42. 键控状态的数据结构?

43. 什么是状态后端?

44. 状态后端的职责?

45. 状态后端的类型?

46. 什么是processfunction 函数?
Process Function 用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的 window 函数和转换算子无法实现)。
47. processfunction 函数有哪些?
ProcessFunction
KeyedProcessFunction
CoProcessFunction
ProcessJoinFunction
BroadcastProcessFunction
KeyedBroadcastProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
48. 什么是侧输出流?
大部分的 DataStream API 的算子的输出是单一输出,也就是某种数据类型的流。 除了 split 算子,可以将一条流分成多条流,这些流的数据类型也都相同。process function 的 side outputs 功能可以产生多条流,并且这些流的数据类型可以不一样。
一个 side output 可以定义为 OutputTag[X]对象,X 是输出流的数据类型。process function 可以通过 Context 对象发射一个事件到一个或者多个 side outputs。
49. flink 故障恢复机制的核心?
应用状态的一致性检查点
50. 什么是 有状态的一致性检查点?
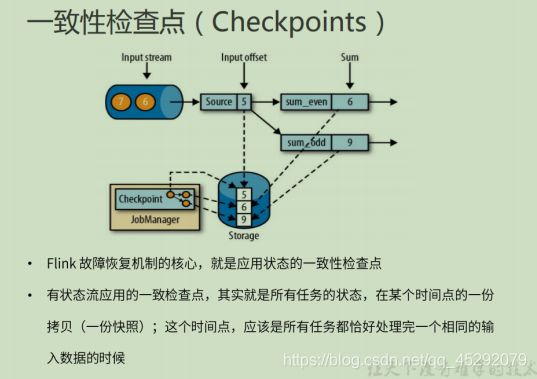
51. 如何从检查点恢复状态?
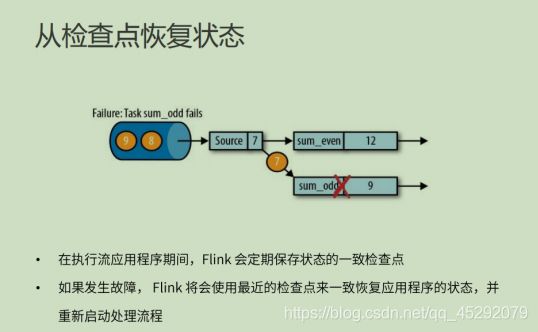
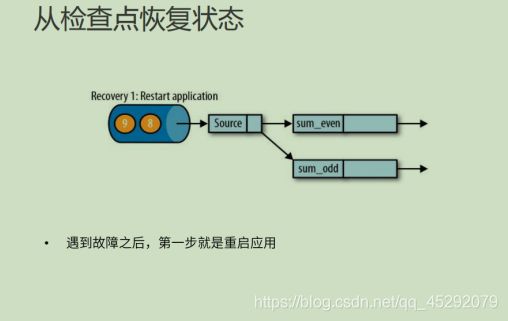
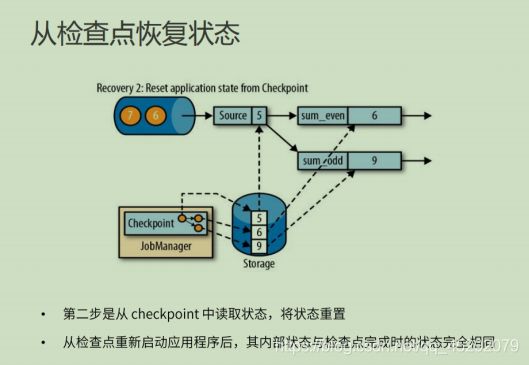
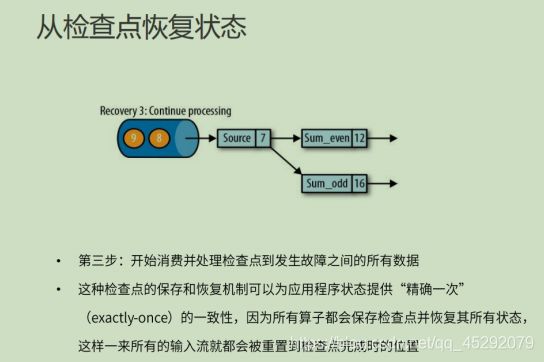
52. 什么是保存点?

53. 检查点和保存点的区别?
点击一下,你就知道
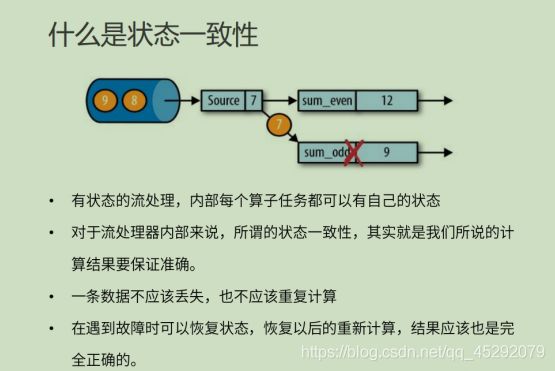
54. 什么是状态一致性?
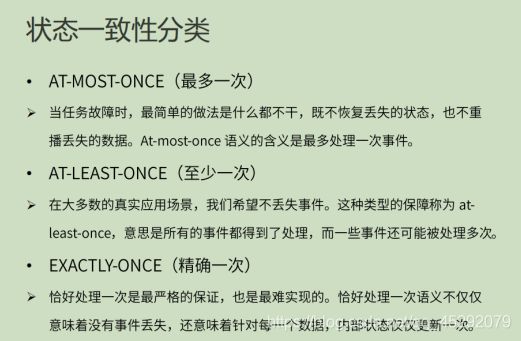
55. 状态一致性的分类?
56. 端到端的精确性?

57. 什么是幂等写入?

58. 什么是2PC?

59. flink和kafka端到端状态一致性的保证?

60. kafka精确一致性(Exactly-once ) 两阶段提交的步骤?

61. 什么是CEP?

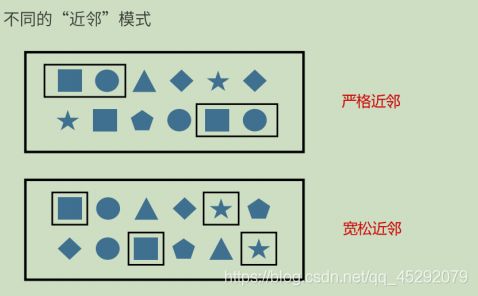
62. flink CEP 的模式有那些?

63. flink CEP 个体模式分为?

64. flink CEP 个体模式的条件?


65. flink CEP 模式序列的几种模式?