独家 | 利用OpenCV和深度学习来实现人类活动识别(附链接)

作者:Adrian Rosebrock
翻译:吴振东
校对:赵春光
本文约5700字,建议阅读16分钟。
这篇教程会告诉你如何利用OpenCV和深度学习来实现人类动作识别。
通过阅读这篇教程,你可以学到如何利用OpenCV和深度学习来实现人类动作识别。
我们实现的人类活动识别模型可以识别超过400类活动,其中准确率在78.4-94.5%之间(取决于任务类别)。 比如,活动类别的可包括:
1. Archery 射箭
2. arm wrestling 掰手腕
3. baking cookies 烤饼干
4. counting money 数钱
5. driving tractor 开拖拉机
6. eating hotdog 吃热狗
7. flying kite 放风筝
8. getting a tattoo 刺纹身
9. grooming horse 给马梳毛
10. hugging 拥抱
11. ice skating 溜冰
12. juggling fire 火焰杂耍
13. kissing 亲吻
14. laughing 大笑
15. motorcycling 骑摩托车
16. news anchoring 播报新闻
17. opening present 拆礼物
18. playing guitar 弹吉他
19. playing tennis 打网球
20. robot dancing机械人跳舞
21. sailing 开帆船
22. scuba diving 潜水
23. snowboarding 单板滑雪
24. tasting beer 喝啤酒
25. trimming beard 修剪胡子
26. using computer使用电脑
27. washing dishes 洗盘子
28. welding 焊接
29. yoga 练瑜伽
30. …and more! 其他
人类活动识别可用于的实践应用包括:
给硬盘中的视频数据集自动分类/分组。
训练或监察新员工准确地完成任务(例如做披萨时的步骤和流程是否合适,其中包括揉面团、上烤炉加热、加盐、加芝士、加馅料等等)。
验证食品的服务生从洗手间出来或手工处理食物时有没有洗手,以免出现交叉污染(比如说鸡肉上的沙门氏菌)。
检查酒吧或饭店里的顾客没有被过度服务(灌酒)。
想要学习如何利用OpenCV和深度学习来实现人类动作检测,请继续阅读本教程。
在这篇教程的第一部分,我们先来讨论下Kinetics数据集,该数据集用来训练人类活动识别模型。
在那之后我们可以聊聊如何来扩展ResNet, 该网络通常使用2D核函数,而我们将采用3D核函数,这样就引入了活动识别模型可利用的时空维度成分。
接下来我们将会实现两种版本的人类活动识别,使用的都是OpenCV库和Python编程语言。
最后,我们应用人类活动识别模型到几个视频样例上,并看一下验证结果。
Kinetics数据集

图1:教程中所采用的人类活动识别深度学习模型是利用Kinetics 400数据集来完成预训练的
我们的人类活动识别模型是利用Kinetics 400数据集来完成训练的。
该数据集包括:
400种人类活动识别分类。
每个类别至少400个视频片段(下载自YouTube)。
一共有300,000个视频。
你可以点击这一链接来查询该模型可以识别的类型名单:
https://github.com/opencv/opencv/blob/master/samples/data/dnn/action_recongnition_kinetics.txt
想要了解关于该数据集的更多信息,包括是如何去整合数据,请参考Kay 等人在2017年发表的论文《The Kinetics Human Action Video Dataset》。
《The Kinetics Human Action Video Dataset》
https://arxiv.org/abs/1705.06950
用于人类动作识别的3D ResNet

图2:深度神经网络利用ImageNet在图像识别上的进度已经使深度学习在活动识别方面趋于成功(在视频方向),在这篇教程中,我们会利用OpenCV进行深度学习的活动识别(照片源自Hara等人的论文)
我们用于人类活动识别的模型来自于Hara 等人在2018年发表于CVPR的论文《Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet》
该论文作者对现有的最先进的2D结构(比如说ResNet,ResNeXt,DenseNet等)进行了探索,将它们扩展为3D核函数从而用于视频分类。
《Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet》
https://arxiv.org/abs/1711.09577
上述文章的作者认为:
这些网络架构都成功地应用到了图像分类中。
经过大规模数据集ImageNet的训练,这些模型都达到了非常高的准确率。
Kinetics数据集的规范同样足够大。
…,因此这些网络架构也应该可以适用于视频分类,通过:1.改变输入集的维度来引入时空维度上的信息;2.在这些网络架构中使用3D核函数。
事实证明上述文章的作者的观点是正确的!
通过改变输出集的维度和卷积核的维度,上述作者获得了如下效果:
在Kinetics测试数据集上的准确率是78.4%。
在UCF-101测试数据集上的准确率是94.5%。
在HMDB-51测试数据集上的准确率是70.2%。
这些结果与利用ImageNet训练的最先进的模型所发布的R1准确率近似,因此这证明了这些模型架构可以用于视频分类,只需要简单地加上时空信息以及用3D核函数来代替2D核函数。
下载OpenCV人类活动识别模型
图3:利用OpenCV和深度学习实现人类活动识别所需文件
对于接下来的教程,你所需要下载的有:
人类活动模型
Python + OpenCV源代码
用于视频分类的样例
你可以在公众号中下载含有全部内容的压缩文件。一旦完成下载,你可以继续阅读本教程。
项目结构
让我们来检查一下项目文件:

我们的项目包含三个附属文件:
action_recognition_kinetics.txt : Kinetics数据集的类别标签。
resnet-34_kinetics.onx : Hara 等人提出的人类活动识别卷积神经网络,并已利用Kinetics数据集完成预训练和序列化。
example_activities.mp4 :一段用于测试人类活动识别的剪辑片段合集。
我们将会回顾一下两个Python脚本,每一个都会接收上面三个文件作为输入:
human_activity_reco.py :我们的人类活动识别脚本每次将N帧图像作为取样,用于活动分类预测。
human_activity_reco_deque.py :一个类似的人类活动识别脚本,使用了一个移动平均数队列。这个脚本跑起来要更慢,不管怎样,我在这里提供这个实现方式,这样你就可以对其进行试验并从中学到一些东西。
利用OpenCV的人类活动识别实现
让我们开始使用OpenCV来完成人类活动识别实现。这一实现是基于OpenCV的官方样例,而我又进行了一些调整(都位于这个和下个样例中),并新增了一些注释(对代码的作用进行了详细的解释)。
打开human_activity_reco.py文件,来看一下下面这段代码:

2-6行是引入包。对于今天这份教程,你需要安装OpenCV4和imutils。如果你没有安装OpenCV的话,利用pip install opencv指令来进行安装。
pip install opencv
https://www.pyimagesearch.com/2018/09/19/pip-install-opencv/
10-16行来解析指令行参数:
--model :训练人类活动识别模型的路径。
--classes :活动识别类别标签文档的路径。
--input 一个用于存放输入视频文件的可选路径。这个参数并没有包括在命令行之内,你的网络是想头也可以在这里被调用。
从这里开始我们来执行初始化:

第21行是加载文本文件中的类别标签。
第22和23行定义采样持续时长(用于分类的帧数)和采样尺寸(每一帧的空间维度大小)。
接下来,我们将会加载并初始化人类活动识别模型:

第27行利用OpenCV的DNN模块来读取PyTorch中预训练的人类活动识别模型。
第31行是对我们的视频流进行实例化,或者是选择一个视频文件,或者是使用网络摄像头。
我们现在准备开始对帧图像进行循环,并执行人类活动识别:

第34行开始循环我们的帧图像,其中帧的批处理将会经过神经网络(第37行)。
第40-53行用于从我们的视频流中构建帧的批处理。第52行将对每一帧图像调整尺寸至400像素宽,而且保持原长宽比不变。
让我们创建自己的输入帧的二进制对象blob,我们此后把它交给人类活动识别卷积网络来处理:

第56-60行是从输入帧列表中创建二进制blob对象。
请注意我们用了blobFromImages (复数形式),而不是blobFromImage (单数形式)作为函数——原因是我们构建了一个多幅图片的批次来进入人类活动识别网络,从而获取了时空信息。
如果你在代码中插入一行 print(blob.shape)的指令,你会注意到这个blob的维度是这样的:
(1, 3, 16, 112, 112)
让我们对这组维度有一个更清楚的了解:
1:批次维度。我们只有单个数据点经过网络(“单个数据点”在这里代表着N帧图像经过网络只为了获得单个类别)。
3:输入帧图像的通道数。
16: 每一个blob中帧图像的总数量。
112(第一个):帧图像的高度。
112(第二个):帧图像的宽度。
至此,我们已经做好了执行人类活动识别推断的准备,然后在给每一帧图像标注上预测的标签,并将预测结果展示在屏幕上:

第64和65行将blob通过网络,获得输出列表(预测结果)。
随后我们选取最高的预测结果作为这个blob的标签(第66行)。
利用这个标签,我们可以抽取出帧图像列表中每个帧图像的预测结果(69-73行),显示输出帧图像,直到按下q键时就打破循环并退出。
一个利用双队列(Deque)数据结构的人类活动实现的替代品
在上一章节关于的人类活动识别中,你从会注意到这几行代码:
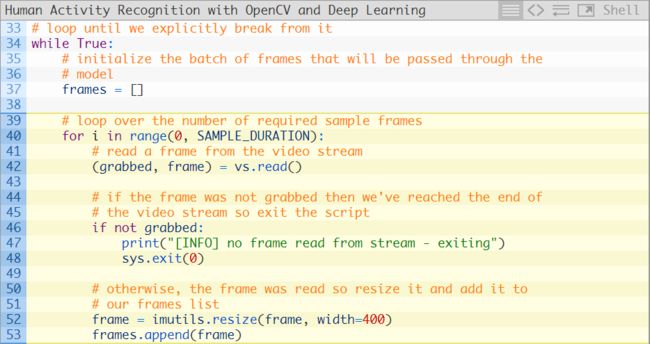
这一实现意味着:
程序会去从我们的输入视频中读取全部SAMPLE_DURATION帧数的图像。
程序会将所有帧图像输入到人类活动识别模型中来获得输出。
接着程序会读取另外一部分SAMPLE_DURATION帧数的图像,然后继续重复这个过程。
因此,我们的程序实现并不是一个移动的预测。
与之相反,它只是简单地抓取一个样本的帧图像,然后进行分类,然后再去处理下一批次。上一批次的任意一帧图像都是被丢弃的。
我们之所以这样做是为了提高处理速度。
如果我们给每一帧单独分类的话,那我们执行脚步的时间就会被拉长。
这说明,通过deque数据结构来进行移动帧图像预测可以获得更好的结果,因为它不会放弃前面全部的帧图像——移动帧图像预测只会丢弃列表中最早进入的帧图像,为那新到的帧图像腾出空间。
为了更好的展示为什么这个问题会与推断速度相关,让我们设想一个含有N帧图像的视频文件:
如果我们用移动帧图像预测,我们进行N次分类,即每1帧图像都进行1次(当然是等deque数据结构被填满时)。
如果我们不用移动图像预测,我们只需要进行 N /SAMPLE_DURATION次分类,这会显著地缩短程序执行一个视频流的总时间。

图4:移动预测(蓝色)利用一个完全填充的FIFO队列窗口来进行预测
批次预测(红色)不需要一帧一帧地移动。移动预测需要更多的计算力,但对于利用OpenCV和深度学习的人类活动识别来说会有更好的效果。
OpenCV的这一dnn模块并不被大多数GPU(包括英伟达的GPU)所支持,我建议你不要对于大多数应用来说还是不要使用移动帧预测。
在今天这篇教程的.zip文件中,你会找到一个名为human_activity_reco_deque.py的文件,这一文件包括一个利用移动帧预测的人类活动识别实现。
这一个脚本与上一个非常相似,我把它放在这里是让你去尝试一下:

引入的库与之前是完全相同的,除了需要再加上Python中collections 模块的deque 实现(第二行)。
在第28行,我们初始化了一个FIFO帧队列,其中最大的长度等于我们的采样时长。我们的“先进先出”(FIFO)队列将会自动弹出最先进入的帧并接收新的帧。我们针对帧队列进行移动推断。
其余所有的代码都是相同的,接下来让我们来检查一下处理帧图像的循环:

第41-57行与我们之前的脚本是不一样的。
在上一个版本的脚本中,我们抽取了一个带有SAMPLE_DURATION数量帧的一个批次,然后再在这个批次上进行推断。
在这个脚本中,我们依旧是以批次为单位进行推断,但现在是移动批次。不同点就在我们在第52行把帧图像放入到了FIFO队列里。如上文介绍,这个队列拥有maxlen 个单位的采样时长,而且队列的头部永远是我们的视频流的当前帧。一旦这个队列被填满,旧的帧图像就会被这个FIFO双端队列实现自动弹出。
这个移动实现的结果就是一旦当队列被填满,每一个给出的帧图像(对于第一帧图像来说例外)就会被“触碰”(被包含在移动批次里)一次以上。这个方法的效率要低一些;但是它却能获得更高的活动识别准确率,特别是当视频或现场的活动周期性改变时。
第56和57使得我们的帧队列在做出任何推断之前,把帧对列填充好。(例如在图4蓝色区域的前16帧所显示的)。
一旦这个队列被填满,我们将可以执行一个移动的人类活动识别预测:
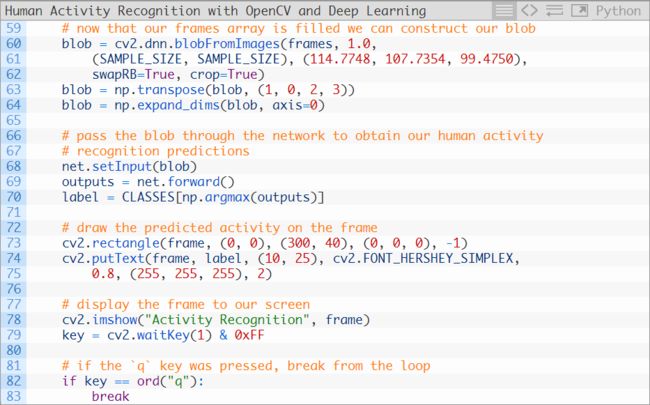
这一段代码块包含的每一行代码与我们之前的脚本是相同的,在这里我们进行了以下操作:
从我们的帧队列中创建了一个blob。
进行了推断,并获得了blob中概率最高的预测。
用平均移动队列所生成的人类活动识别标签对当前帧图像进行注释和显示。
一旦按下q键,程序将会退出。
人类活动识别在实际应用中的结果
让我们看看人类活动识别在实际应用中的结果。
在这里,打开terminal,执行以下命令:

请注意我们的人类活动识别模型要求的OpenCV最低版本是4.1.2.
如果你使用的OpenCV版本过低,那么就会收到以下报错信息:

如果你收到以上信息,说明你需要更新你的OpenCV版本至4.1.2以上。
下面这个例子就是我们的模型正确地给这段视频打上“瑜伽”的标签。
请注意我们的模型在识别时对预测是“瑜伽”还是“拉伸腿部”犹豫不决——当你在做下犬式姿势时,这两个动作术语从技术层面来看都是正确的。从定义上来讲,你在做瑜伽的同时,也是在拉伸腿部。
在下一个样例中,人类活动识别模型正确地预测出了这是在做“滑板运动”。
你可以看到模型也会把这个活动预测为“跑酷”。滑滑板的人在栏杆上跳跃,这很像是跑酷者可能的动作。
有人饿了吗?
如果谁饿了,一定会对这个“做披萨”感兴趣:
但在你吃披萨前,请确保你已经“洗手”:
如果你沉浸于“喝啤酒”,你最好注意一下饮酒量,酒吧侍者有可能会把你灌醉:
你可以看出,我们的人类活动识别模型可能不够完美,但是考虑到本技术上的简单性(只是将ResNet的2D输入改为3D),它的表现还是不错的。
人类活动识别问题还远远没有解决,但在深度学习和卷积神经网络的帮助下,我们已经朝这个方向迈出了一大步。
总结
在这篇教程中告诉你如何用OpenCV和深度学习来实现人类活动识别。
为了完成这一任务,我们借助了Kinetics数据集对人类活动识别模型进行了预训练,这一数据集包含400-700种人类活动(取决于你使用的数据集的版本)和超过300,000个视频剪辑。
我们使用的模型是带有变动的ResNet, 改动的方面是用3D核函数代替了原本的2D滤镜,使得模型具有了可用于活动识别的时间维度成分。
想要了解更多,你可以阅读Hara等人在2018年发表的论文《Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet》
最后,我们用OpenCV和Hara等人的在PyTorch上的实现OpenCV的dnn模型,生成了人类活动识别模型。
基于我们所取得的结果,我们可以看出这个模型可能不够完美,但是表现还是不错的。
原文标题:
Human Activity Recognition with OpenCV and Deep Learning
原文链接:
https://www.pyimagesearch.com/2019/11/25/human-activity-recognition-with-opencv-and-deep-learning/
编辑:王菁
校对:林亦霖
译者简介

吴振东,法国洛林大学计算机与决策专业硕士。现从事人工智能和大数据相关工作,以成为数据科学家为终生奋斗目标。来自山东济南,不会开挖掘机,但写得了Java、Python和PPT。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织