Facebook:对比COPA 与CUBIC,BBR v1在拥塞控制及视频质量的表现

Facebook的测试结果显示,COPA较于常用算法CUBIC及BBR v1存在一定优势,来看看具体表现。
文 / Nitin Garg
译 / Adrian Ng
原文 https://engineering.fb.com/video-engineering/copa/
在对互联网应用进行性能优化时,可能会涉及一些复杂的权衡。在传输大量数据的时候,如果传输速度过快,可能会因为丢包而产生重传,从而随着时间流逝导致性能损失。同时,如果发送数据的速度太慢则可能会导致延迟和卡顿,对性能也有很大的损害。此外,不同的视频体验需要针对质量与延迟进行不同的权衡。对于交互式体验,其应用程序可通过降低视频质量,避免卡顿。但当视频的高质量是最重要的因素时,应用程序可以在合理的范围内的保持一定延迟。此时,应用通常会在几种不同的拥塞控制算法中进行选择,找到最适合当前目标的优化算法进行优化。
尽管在拥塞控制领域上我们已进行了广泛的研究,但若要将研究付诸实践一直以来都会涉及到修改Linux内核。使用QUIC可以在无需修改内核的情况下,在用户空间中实现整个传输堆栈,简化整个部署和实验的流程。而COPA 与 QUIC 的耦合可以为我们提供一种算法,该算法可适用于各种视频体验,并且可以合理地遵循一种部署策略。在实际测试中,测试结果显示COPA较于常用算法CUBIC及BBR v1存在一定优势。本文将详细介绍为此所做的实验工作以及从大规模评估COPA中获得的经验。

COPA测试:基于延迟的拥塞控制
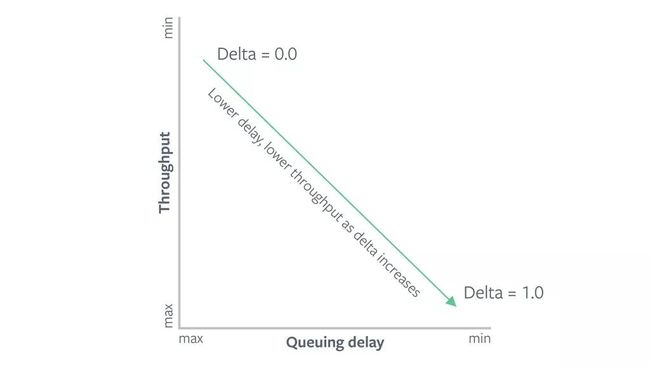
经过对COPA的实施和评估, COPA(美国MIT理工学院所设计的基于延迟的可调拥塞控制算法) 基于一个客观函数,所以吞吐量和延迟的权衡可以通过用户指定的参数parameter,delta进行配置。如果增量值较高,COPA对延迟就越敏感,使得输出降低。反应效果的增量值减少将提供高质量的输出并降低延迟。
在此实验中,我们选择了Android平台上的Facebook Live。通过Facebook Live, 用户可以做线上直播streaming,推广给朋友并且获取更多粉丝. 根据我们的设置,首先需要一个手机摄像头生成视频,再用自适应bitrate算法测量输出, 并调整编码bitrate。接着,我们将使用QUIC把视频传送到FB服务器,重新在服务器内发出新的码流播放给观众。
在第一个测试里,我们实现了无竞争模式(采用固定delta)的COPA。采用0.04的增量值才得以以达到以下结果,并在其中发现这些结构作为应用程序可以提供更合理的质量与延迟权衡,所以将CUBIC和BBR v1拥塞控制算法放在一起进行比较。CUBIC比较常见,也是LINUX的默认拥塞控制算法。此应用模式是增加CWND一直到数据包丢失,再通过乘法式减少CWND。但这种模式也会带来一些问题,例如缓冲膨胀buffer bloat及jagged锯齿状的传输模式会导致延迟。最近Google开发的新算法BBR,利用的则是bottleneck带宽和RTT构建网络路径模型,调整发送速率,以实现带宽和延迟之间的最佳平衡点。COPA、CUBIC 和 BBR的实作方案都可以在我们的 QUIC 方法中找到。
测试结果
我们通过A/B 测试来衡量全球 Facebook 实时视频的性能,其中大多数在线会话来自美国、墨西哥、印度、印度尼西亚、越南和泰国。在此次实验中,我们聚焦于每个视频的应用指标:
平均高质量的输出: 在广播期间,发送的应用程序字节总数除以持续时间。请注意,Facebook Live 会话时间通常比较长(从几十秒到几分钟),所以应用程序会根据高质量输出和队列大小更改比特率。如果有更好高质量输出,反应出来的传送质量也会提升。重传发生期间,数据字节不会提高输出质量,原因是因为它们不代表任何新的应用程序字节-自然而然地也减少了goodput.
平均应用程序RTT测试: 这是Live摄入延迟的prox服务器。每一秒,应用程序会向服务器发送一个小的虚拟负载并等待确认。我们测量了此往返时间(RTT),并采用会话时间的平均值来计算平均应用 RTT。如果bitrate相同或比例更高,那表示较低的应用 RTT 会显示较低的视频引入延迟。

依据测试结果,我们使用RTT 测量发现 COPA 的视频延迟平均率比 CUBIC 低。对于网络良好且低延迟率的session,BBR可以减少更多幅度。P50 应用 RTT 从 499 ms 的 CUBIC 下降到 479 ms 的 COPA 和 462 ms 的 BBR,COPA 减少了 4%, BBR 减少了 8%。

因此,对于网络较差且延迟率较高的直播,COPA可以克服减少更多的幅度。 P90 App RTT 从 CUBIC 的 5.4 秒降至 COPA 的 3.9 秒,COPA 减少了 27%,而 BBR 的缩减开始减少。

在实际场景中,我们可以通过调整视频质量来降低延迟。举个例子,如果降低视频bitrate,降低视频质量,每当发生网络拥塞时,视频延迟也会相应降低。如果分别把三组数据都拿来做比较,我们会发现COPA和BBR提供的质量输出要比CUBIC好。这样的结果反而显得COPA 和 BBR不仅减少了延迟,还可以提供更高质量的视频。如果我们遵循延迟改进的模式,可以发现COPA 相比 BBR 有明显的优势。BBR 将 P10 改进了 4.8%,而 COPA 提高了 6.2%。BBR 将 P50 良件提高了 5.5%,而 COPA 提高了 16.3%。

我们必须留意的是,在P90 以上的增益似乎会减少,这是由于这个实验的编码器bitrate设限为 3 Mbps。在具体实验中,我们专注于测量 QUIC 运输的 RTT 和转播overhead。传输 RTT 和应用 RTT 有很大的差异,前者是通过网络发送数据包后测量往返时间,后者是在数据包离开应用层后测量数据包。应用程序 RTT 存在隐藏的重传,即使在packet loss的情况下,它也会在传输层产生多次的往返运输。
RTT平均传输数据
随着RTT应用模式,BBR为我们提供了最低的传输 RTT能量,以获得最佳连接(P25 及以下)。但是结果显而易见,平均率幅度的减少并不大,因为对于这些用户来说RTT已经处在一个很低的平均率了。
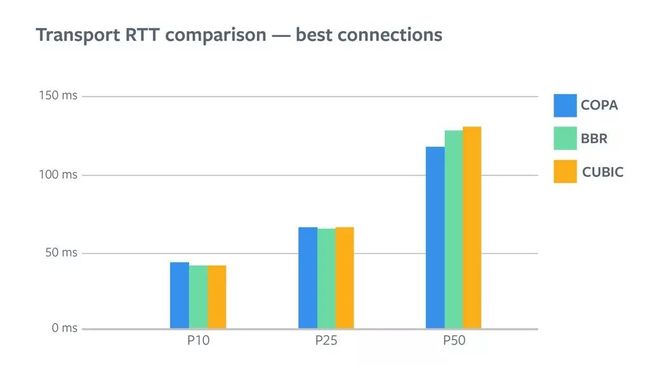
当你留意P75 及更高时, COPA在此很明显提供了最低值。BBR 将 P75 RTT 降低了 10%,而 COPA 将其降低了 35%。与之相比,P95 的降低幅度更大,BBR 将其降低了 16%,而 COPA 将其降低的幅度高达 45%。

如果存在较低的传输 RTT,也许可以判定视频延迟下降的原因。值得注意的是,视频延迟(RTT应用程序)还取决于应用程序基于 ABR 发送的数据量,这会影响传输发送缓冲区中的数据量。因此,这使 ABR 能够产生更好质量,从而抵消了较低传输 RTT 减少的延迟。另一方面,传输 RTT 的变化仅取决于数据包离开传输后基础网络中排队的数据量
RTX Overhead开销
为进一步了解传输行为,我们查看了丢失和传输的数据量。该指标的确切定义是:
RTX Overhead = Total bytes retransmitted bytransport / Total bytes ACKed
我们发现,与CUBIC相比BBR 对于所有用户的总体开销较低,对于90%的用户来讲约为CUBIC的一半左右。COPA和CUBIC相比, COPA 负担了大约 75% 用户四分之一的开销,到最后开始攀升并最终达到CUBIC 的4-5倍左右。

COPA 不将packet loss视为拥塞信号; 当它发现队列延迟增加时,会主动降低CWND。随着bottleneck队列的填满,COPA 所进行的延迟测量将会增加,我们就可以在流量损失产生前发现存在拥塞。因此在理想情况下,我们应该始终可以看到COPA有较低的数据包流失。实际上,这是大约90%的用户所看到的,而最后 10% 的用户则看到更多的损失。这表示丢失率和排队延迟与这部分用户没有关联性。
网络流量监管
网络流量监管表示某一来源的流量被隔离并限制以特定速率节流。。通常情况下,提供者将会丢弃超过该速率的所有额外数据包。并且会产生一些明显特征,使其与拥塞造成的损失区分开来:
一致的吞吐量
高损失
更低的RTT 和队列延迟
尽管与CUBIC和BBR相比,COPA的尾端重传开销很大,但尾端RTT开销比较少,这与流量监管的一些特点相符。为了正视这一点,第一步,我们按照ASN 对结果进行分解,因为通常情况下,流量监管会因为ASN 的提供对象不同存在很大差异。经过测试,我们发现某些 ASN(在某一项独立分析中发现了流量监管的迹象)对于 COPA 的 RTX 开销也高得多。为了证实此理论,我们绘制了图表展示 RTT、队列延迟和 RTX 开销之间的关联性。

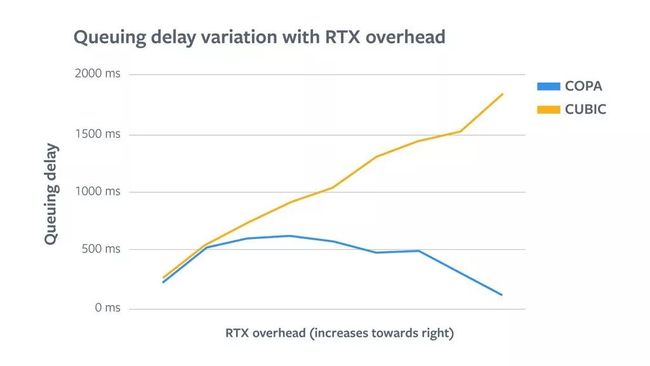
在图中的前半部分,我们看到对于 COPA,RTT 和队列延迟会随着 RTX 开销的增加而提升。这表示在当前区域,损失确实是由于拥塞造成的,同时伴随着排队延迟的增加。但在达到最大值后,RTT 和队列延迟在图表的后半部分开始下降。RTX开销最高的区域中的用户实际上看到的延迟非常低。这就证实了我们的结论,即高损失可能是因为网络限制的原因。不过,短缓冲区也有可能是其中一部分原因,但网络特征和解决方案非常相似。对于CUBIC来说,RTT 和队列延迟随着 RTX 开销的增加而增加。这表明所有用户的损失都是由于拥塞造成的,因为 CUBIC 将损失视为拥塞信号,并相应地减少了 CWND。
未来计划
COPA的潜力是毋庸置疑的。目标函数运行良好,控制排队延迟与吞吐量权衡的拨号非常有吸引力。我们的测试是基于极端条件情况进行的,即在非常低的delta值下优化吞吐量。虽然它仅仅是针对吞吐量进行优化,但与 BBR 和 CUBIC 相比,仍然大大减少了排队延迟。值得注意的是,在我们的 QUIC 实现和传输控制协议(TCP) 版本中,BBR 正在进行一些变化和改进,因此这种比较在将来可能会显示出不同的结果。后续,我们将开始测试另一个极端情况, 即产品对极低延迟有要求时。这项实验会使我们更接近于拥有一个能够满足不同应用需求的单一可调拥塞控制算法。广泛的部署还需要更好地了解COPA对竞争流程的影响及其对于TCP的友好性。在测试中,我们无法捕捉到这方面的重要信号。因此,这仍然是未来工作很重要的一部分,高RTX cases还存在许多改进的余地。目前有几种方法来更好的解决这些问题:COPA文件建议实施一种竞争模式,在这种模式中,增量值根据竞争的流动和损失动态变化。另外一种选择是实施启发式方法,即根据损失来减少CWDN。但此方法存在一定风险,有可能会使COPA对于拥塞无关的随机损失做出反应,并侵蚀一些吞吐量。此外,与 BBR v1类似,还有一种方法就是可以为网络策略实施显示检测。
LiveVideoStack 秋季招聘
LiveVideoStack正在招募编辑/记者/运营,与全球顶尖多媒体技术专家和LiveVideoStack年轻的伙伴一起,推动多媒体技术生态发展。同时,也欢迎你利用业余时间、远程参与内容生产。了解岗位信息请在BOSS直聘上搜索“LiveVideoStack”,或通过微信“Tony_Bao_”与主编包研交流。
