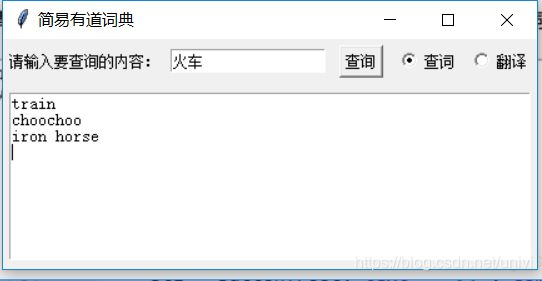
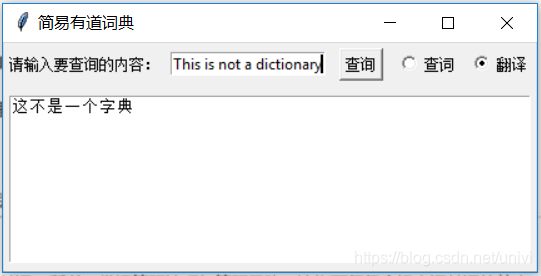
python简易有道词典
0.说明
通过浏览器跟踪【有道词典】和【有道翻译】网页查询过程,制作python简易字典。
代码案例在:https://github.com/suchocolate/test/tree/master/spider/simpledictionary
制作过程:
- 踩点查词
- 踩点翻译
- 制作程序
1.踩点有道词典
1.1 先踩点查英文单词
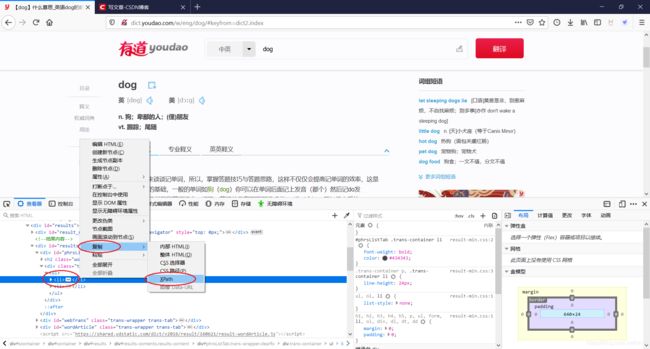
F12浏览器登陆有道词典网页,查看实际查英文词的URL是:http://dict.youdao.com/w/eng/dog/
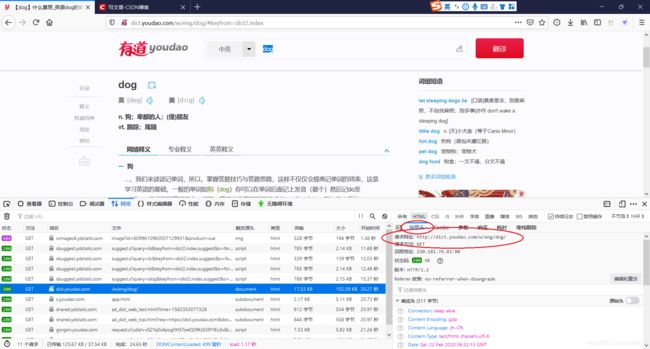
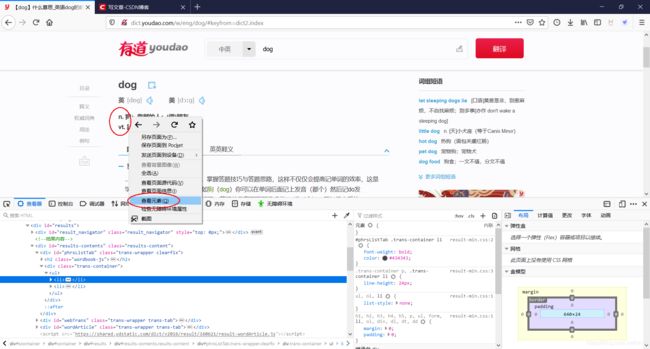
记录一下查询结果的xpath,交给lxml.etree解析:
1.2 再查一下中文词
发现URL是:http://dict.youdao.com/w/%E7%8B%97/,这个“%E7%8B%97”是URL编码的中文,可以用urllib.parse里的quote制作。
2.踩点有道翻译
有道翻译的URL是:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule。
后来发现向这个URL POST数据不会得到结果,真正的URL要把“_o”去掉。
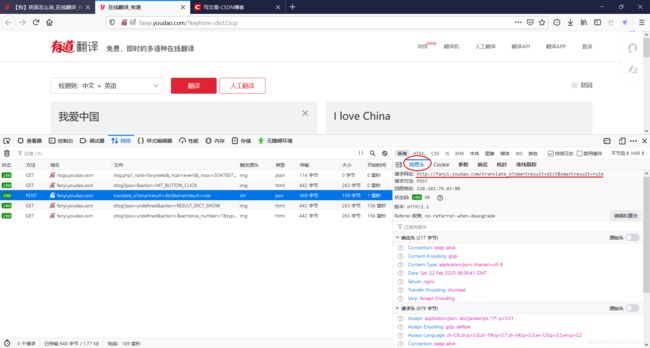
翻译时,浏览器发送的是表单,那么到时封装到request的data里。

有道返回的是json,用json解析: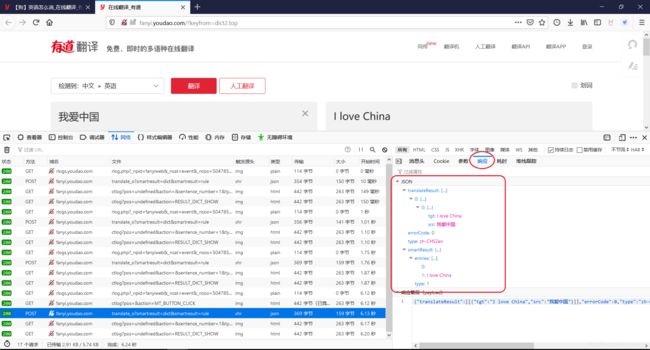
3.制作程序
# 请求网页用
from urllib import request, parse
# 制作转化中文为URL格式
from urllib.parse import quote
# 分析库
from lxml import etree
# 用tkinter做图形化
from tkinter import *
# 解析json数据
import json
# 英文单词查询网址
ebase = 'http://dict.youdao.com/w/eng/'
# 中文单词查询网址
cbase = 'http://dict.youdao.com/w/'
# 翻译网址
trans = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
# 查询时http头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"}
# 翻译提交的字典
dic = {"doctype": "json"}
# 判断查询类型,1是查词,2是翻译。
def chaxun():
if v.get() == 1:
chaci()
else:
fanyi()
# 定义查词函数:
def chaci():
wd = e1.get()
# 如果是中文查询,转换中文为URL编码格式,中文unicode编码范围。
if '\u4e00' <= wd <= '\u9fff':
# 转中文为URL编码
wd = quote(wd)
url = cbase + wd
q = request.Request(url=url, headers=headers)
r = request.urlopen(q, timeout=2)
html = etree.HTML(r.read().decode('utf-8'))
# 查中文时的xpath和英文的xpath不同
result = html.xpath('/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/div[1]/div/ul/p/span/a/text()')
else:
url = ebase + wd
q = request.Request(url=url, headers=headers)
r = request.urlopen(q, timeout=2)
html = etree.HTML(r.read().decode('utf-8'))
# 查英文词的xpath
result = html.xpath('/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/div[1]/div/ul/li/text()')
# 清理text,重新显示
text1.delete(1.0, END)
# 如果有结果,显示结果
if len(result) != 0:
for pt in result:
text1.insert(INSERT, pt + '\n')
else:
# 如果没有结果,提示没有结果
text1.insert(INSERT, 'There is no explain.')
# 翻译
def fanyi():
# 清除文本框中的内容
text1.delete(1.0, END)
# 获取输入框的字,复制给变量wd,装入字典
wd = e1.get()
dic['i'] = wd
data = bytes(parse.urlencode(dic), encoding='utf-8')
# 开始翻译
q = request.Request(url=trans, data=data, headers=headers, method='POST')
r = request.urlopen(q)
# 得到的结果是json数据,
result = json.loads(r.read().decode('utf-8'))
# 数据处理后放入输入框
text1.insert(INSERT, result['translateResult'][0][0]['tgt'])
if __name__ == '__main__':
# 主函数,定义一个tk对象
root = Tk()
root.title('简易有道词典')
# 定义一个说明标签
l1 = Label(root, text='请输入要查询的内容:')
l1.grid(row=0, column=0)
# 定义一个输入框
e1 = Entry(root)
e1.grid(row=0, column=1, padx=1, pady=5)
# 定义一个按钮
bt1 = Button(root, text='查询', command=chaxun)
bt1.grid(row=0, column=2, padx=5, pady=5)
# 定义一个文本框
text1 = Text(root, width=59, height=10)
text1.grid(row=1, columnspan=5, padx=5, pady=7)
# 定义一个单选变量,初始值1,即默认是查词
v = IntVar()
v.set(1)
# 定义一个单选框
Radiobutton(root, text="查词", variable=v, value=1).grid(row=0, column=3)
Radiobutton(root, text="翻译", variable=v, value=2).grid(row=0, column=4)
# 循环窗体
mainloop()
运行的效果