Python 短信通知系统开发实战
课程介绍
作为学生,你想不想要这样一种服务:教务系统更新成绩后,你的手机上会自动收到成绩通知?
作为白领,你想不想要这样一种服务:公司发布了晋升、放假等新闻时,你的手机上会第一时间收到新闻?
作为……
什么,你还没学网页设计?没关系,课程直接用控制台写,不需要你设计网页!
什么,你感觉技术特别杂?没关系,课程第一部分“粗暴”地列出了你需要学习的东西,跟着它走,你也可以完成课程!
本达人课共包含以下三大部分:
第一部分(第 01-02 课),带您初步认识网页爬取技术,包括 Python 基础语法和网页基础概念讲解,让你对网页爬取有一个基础认识。
第二部分(第 03-11 课),核心技术讲解,包括开发环境的搭建、数据库的使用、邮箱接口、短信接口集成等技术的讲解,为后面的实战部分打好基础。
第三部分(第 12-15 课),实战进行时,通过项目实战开发,带您从头到尾开发一个学生成绩短息通知系统,并部署至服务器中,全方位提升你的技术实力与思维方式。
作者介绍
潘舒新,现就职于某金融网络公司担任后台开发工程师,Udacity 官方翻译组成员,长期活跃于各大论坛,擅长 Java、Python 开发。
课程内容
导读:关于网页爬取那些事儿
背景
这个事情还要从 Google 或者百度说起。目前的搜索引擎,一般都拥有自己的一套网页检索算法,方便大家迅速的找到需要的网页。但是,当我们在使用各种搜索引擎的时候,是否思考过这样一个问题:搜索引擎是如何搜索到最新网页的信息,并且展现在搜索结果页上的呢?答案就是网页爬虫。
百度蜘蛛,是百度搜索引擎的一个自动程序。它的作用是访问收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,使用户能在百度搜索引擎中搜索到您网站的网页、图片、视频等内容。
——来源 · 百度百科《百度蜘蛛》
在最初,网页爬虫技术似乎就只是为搜索引擎服务的:一方面是搜索引擎的技术性需要,另一方面是当时的互联网信息,还没有这么庞大,最终的一点是,当时的用户对及时性服务还不是这么迫切。但是现在,网页爬虫早已挣脱了之前的技术局限性,被广泛的应用在各个领域中。例如前阵子大放光彩的“即刻”App,其核心就是网页爬虫技术。
网页爬虫在不断发展中也产生了很多新颖并且实用的框架,也从当初的特定编程语言,变成了现在的五花八门、各放异彩的编程语言。然而,在众多的编程语言中,Python 无疑是最为重要,也是最为广泛的语言,本达人课,我们就以 Python 作为我们的主力编程语言,助力我们的“起飞”。
Python 介绍
无论你之前学过什么语言,无论你是否了解 Python,在正式学习本课程前,你需要告诉自己:Python 作为高级编程语言,哪怕你没有编程的基础,你也可以高傲而且自豪地去使用它!
本门课程无意争辩到底哪门语言的效率最高,亦或是哪个编程语言是最好的。选择Python 作为本门课程的主力编程语言的理由主要有以下原因:
- Python 简单易学,初学者在什么都不了解的情况下,都可以很好的上手;
- Python 自带的封装接口,以及丰富的第三方库大大简化了我们的开发流程,一些看上去很难实现的功能,往往一行代码就能够搞定;
- 基于 Python 开发的网页爬虫框架众多,方便我们以后的深入学习。
Python 给自己的定义,就是一个“胶水”语言:哪里需要哪里用。或许和 C++、Go 等一些语言相比,Python 的运行速度很慢,但是需要指出的是,这里的“速度慢”,仅仅是相比较而言。例如,发送邮件,使用 C++ 需要0.1秒,Python 则需要1秒。虽然速度相差10倍,但是作为日常开发而言,Python 的速度已经完全满足了我们的开发要求。
热度
Python 网络爬虫技术本身发展特别快,甚至可以说,网页爬虫技术随着 Python 的发展而发展。从最初 Python 自带的 urllib 库,到现在流行的 BeautifulSoup4、Selenium 等第三方框架。可以说,在网络爬虫的世界中,Python 一直处于“最强王者”的地位。

此图来自于百度指数(2018年4月23日)。可以发现的是,从2014年开始,Python 爬虫的搜索指数呈大幅上升的趋势,也同时印证了 Python 在网页爬虫领域上的地位。
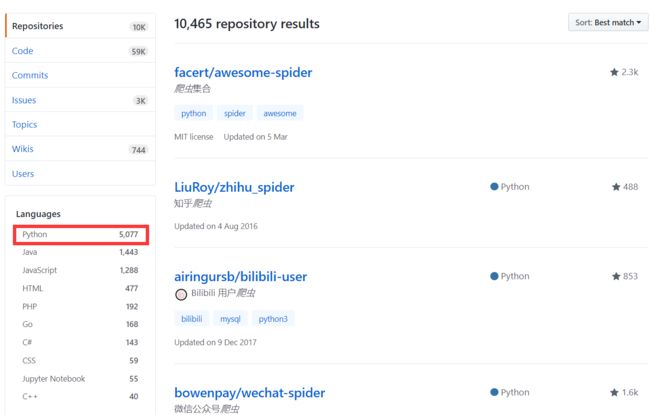
在全球知名的 Github 网站上,搜索“爬虫”,有5077项使用 Python 写的网页爬虫项目,比排名第二的 Java 多出了将近3.5倍!
为什么学习网页爬虫
- 从互联网技术发展的角度来看,越来越多的公司开始拥抱 Python 技术栈。与此相对应的是,越来越多的公司也开始提供了类似 Python 网页爬取工程师、分布式网页爬取架构师等工作职位。Python 爬虫技术已经成为互联网公司不可或缺的技术方向;
- Python 网页爬虫所包含的技术栈,包含了 Python 基础操作、HTML 结构分析、计算机网络特性等互联网公司正在使用的技术,学习 Python 网页爬虫技术,可以很好地触类旁通了解其他技术;
- 网页爬虫技术在日常生活中有很大的用处,学习网页爬虫技术可以帮助我们更好的“享受生活”。
这个课程可以学到什么
早些时候由于个人兴趣原因研究并使用了 Python,在使用时发现,国内关于 Python 网页爬虫的教程虽然很多、内容丰富,但是往往涉及到特别多的前期准备,并不适合 Python 新人上手。为了帮助一位学弟尽快的入手网页爬虫技术,我总结了自己的网页爬虫学习路线,结合他的实际应用,做出了一套适合新手入门学习的 Python 网页爬虫教程。在这套教程的帮助下,学弟很快掌握了核心的技术栈,并且顺利的完成了我对他的毕业要求。
本达人课,首先介绍 Python 和网页的一些基础知识,带你快速的学习 Python 的基础语法,再一起讨论网页爬虫框架的使用,如何通过邮件或者短信发送我们需要的信息,最后使用我们学到的技术实现一个在服务器运行的成绩通知短信系统,进行实战演练。
需要强调的是,Python 网页爬虫技术栈经过近几年的发展,可以说已经自成一脉。如果要将这些技术全部展现出来,不仅工作量巨大,而且涉及的技术对于新手也太过深奥,因为本达人课先带大家掌握 Python 网页爬虫的入门部分,后面大家再进阶学习也就容易很多了。
适合阅读的人群
该系列文章适合以下人群阅读:
- 刚学完 Python 基础课程,希望做一个有趣的实战项目的人员;
- 对 Python 网页爬虫感兴趣,希望尽快上手核心技术的开发人员;
- 希望做一个提高生活效率的在校学生或其他人员。
在学习本课程之前,希望你有一些基础的开发技能,例如:独立使用 C++ 写出一个从1加到10的控制台程序。
开发环境:
- JetBrains PyCharm 2017.3.3 x64 (也可以使用其他IDE)
- Python 3.5
使用到的软件:
- MySQL
- fidder4
- Requests
- BeautifulSoup 4
- ……
点击了解更多《Python 短信通知系统开发实战》
第01课:Python 极速教程
Python 版本的选择
本文采用的是 Python 3.x(具体来说,是 Python 3.5)。采用该版本主要原因有:
- Python 3.x 较为完美的解决了 2.x 版本存在的中文字符编码问题,使得初学者能够更好地关注代码本身;
- 作为一名程序员,在学习新技术的时候不仅要靠自我判断,也要考虑到历史的行程:目前大部分的第三方库,都以 Python 3.x 进行开发和部署。之前仅支持 2.x 版本的第三方库,也逐步兼容了 Python 3.x;
- Python 3.x 和 2.x 的差异并不是很大,学会 3.x 的简单操作,就可以很好的过渡到 2.x 版本。(如果你对这两者的差异感兴趣,可以阅读这里 )
搭建开发环境
本门课程假定你使用的是 Windows 操作系统,因为这能够让你在接下来的教程中,稍微体会到编码问题的棘手性(当然,我们也会最终解决这个问题)。如果你使用的是 Unix 或者是类 Unix 系统,相信你已经对编码问题有了初步的了解,欢迎你向其他同学传授一下你的人生经验。
作为一名开发人员,推荐大家前往 Python 官方网站下载相应的安装包。为了保证接下来我们能够顺利的使用第三方框架,安装的时候请勾选 安装 pip ,如果你认为自己会忘记,那就直接一直点击 Next Step 吧!
虽然 Python 自带了 IDE ,但是对于初学者而言,官方的 IDE 并不是很好用。本文使用的 IDE 是目前互联网公司普遍使用的由 JetBrains 公司开发的 Pycharm,Pycharm 分为收费的个人专业版和免费的社区版。对于本次课程来说,我们只需要下载社区免费版就可以了。
基本概念
这个部分带领大家“极速”了解 Python 的基础语法。需要说明的是,本部分的所有语法,都是围绕着本课程展现的,还有很多未涉及的语法和高级特性。作为一名开发者,我得承认:如果你想以后从事 Python 开发工作,并且目前对 Python 一点都不了解的话,这样的学习方法并不合适。
Hello World 初体验
按照国际惯例,每当学习一门新的语言时,我们都要仪式性的输出“Hello World"。使用 Python 输出“Hello World”很简单,几需体验三番中 里造会干我一样 爱桑结款游戏(哈,借用下《贪玩蓝月》中的话)……不对,Python 输出“Hello World”只需要一行代码:
print("Hello World")print()是一个函数(function),这是我们接触到的第一个重要概念。你可以理解为函数是一组封装好的代码集合。
数据类型和变量
Python中主要的数据类型有:字符串、整数、浮点数、字符串、布尔值。
当我们在 CMD 控制台输入1+1的时候,控制台会输出2。但是,如果我们要在之后的计算中继续使用这个2该怎么办呢?我们就需要通过一个“变量”来存储我们需要的值。
var1 = "金坷垃" #将"金坷垃"传给参数var1,字符串print(var1) #输出结果为:金坷垃var2 = 2 #整数print(type(var2)) #输出结果为:intvar3 = True #布尔值var4 = 3.1314526 #浮点数在上述代码中,我们使用 type() 来显示变量 var2 的数据类型。在 Python 中,你可以使用 # 来注释相关信息,注释的信息 IDE 在编译的时候,会自动忽略。
布尔值运算
布尔值在 Python 中有两个量:True 和 False。
var1 = 12var2 = 12var3 = 13print(var1==var2) #Trueprint(var1==var3) #False其中,var1==var2 没有改变两个量的值,而是对它们进行比较,且比较的结果是布尔值 True,因为 var1 和 var2 的值都是12。
条件、循环和其他语句
Python 使用 if 和 else 来作为条件判断语句。
int i = 1;if i==1: print("Yes,it is 1")else: print("No,it is not 1")上面的语句用来判断变量 i 是否等于1。请注意:Python 对缩进是极重视的。所以在写判断语句的时候,需要注意缩进是否在同一个区域。
Python支持 for 循环和 while 循环。循环语句和 if、else 语句类似,比如都需要加冒号,语句体需要缩进。
for i in range(1,10): print(i)上面的语句是输出1到10之间的数,请注意,range(1,10) 的范围是从1到9,不包含10。
while(i<10): i++ if i!=8: continue else: break上面的语句中,break 关键词的意思是:跳出循环,continue 的意思是:继续循环。
列表
在本门课中,列表是比较重要的一个数据容器。
list1 = [1,2,3,4,5]list2 = ["金坷垃","圣地亚哥","雄鹰高飞"]列表是具有索引的,因此想要访问一个列表中的数值,只需要列表名+索引值就能够得到了。
print(list1[2]) # 3print(list2[0]) #金坷垃字典
字典是一种特殊的列表,字典中的每一对元素分为键(key)和值(value)。对值的增删改查,都是通过键来完成的。
brands = {"Tencent":"腾讯","Baidu":"百度","Alibaba":"阿里巴巴"}brands["Tencent"] #获取键值为"Tencent"的valuedel brands["Tencent"] #删除腾讯brands.values[] #得到所有的value值brands.get("Tencent") # 获取键值为"Tencent"的value函数
之前我们使用过 print() 和 type(),这两个都是函数。对于重复性的代码段,我们不需要每次都写出,只需要通过函数的名称调用就可以了。
定义函数的关键字是 def,定义的方式和 for循环差不多。
def function(param): #function为函数名,param为参数 i = 1 return i #f返回值 为了讲解的更形象,我们来写一个 a+b 求和的函数。
def getSum(a,b): #定义函数名为getSum,参数为a,b sum = a+b; return sum; #返回a+b的和,sum定义完成后,我们就可以在程序的其他地方,通过调用 getSum(a,b) 来使用这个函数。
文件
之前我们讲的一系列的操作,都是放在内存中的,一旦关闭程序,那么相关的变量也就被释放了。因此,为了保存我们的数据,就必须要学习通过 Python 操作文件。
Python 提供了丰富且易用的文件操作函数,我们将常见的操作快速学习一下:
- open():
open("abc.txt","r") #open()为Python 内置的文件函数,用来打开文件,“abc.txt”为目标文件名,"r"代表以只读方式打开文件,其他的还有“w"和"a"模式- read():
打开的文件,必须通过 .read() 方法才能得到数据。
file = open("abc.txt","r")words = file.read()友情提醒
这篇《Python 极速教程》仅仅展示了本门课程中最需要掌握的几个部分,类似于元祖、类、对象、继承等更加丰富的内容由于时间原因,没有一一放在此处。有兴趣的小伙伴可以选择课后对 Python 进行系统的学习。
相比较于一直在 Python 教程中做各种 a+b、var1==var2 的操作,本门课程希望大家能从实际的使用中学习 Python ,也即:哪里不会搜哪里。事实上,作者在编制这门课程时,也经常会通过 Google、Github 或者是官方文档,搜索一些忘记的不太常用的语法特性。
点击了解更多《Python 短信通知系统开发实战》
第02课:网页基础知识一点通
什么是网页
当你在浏览器输入 www.gitchat.com,并回车访问的时候,你看到的所有的展现在你屏幕上的东西,其实都是网页。网页是通过 URL 来进行识别和访问的。按照 Wiki 百科的说法,网页被定义成下面的说明。
网页(英语:Web Page)是一个适用于万维网和网页浏览器的文件,它存放在世界某个角落的某一部或一组计算机中,而这部计算机必须是与互联网相连。网页经由网址(URL)来识别与访问,当我们在网页浏览器输入网址后,经过一段复杂而又快速的程序,网页文件会被传送到用户家的计算机,然后再通过浏览器解释网页的内容,再展示给用户。是网络中的一“页”,通常是 HTML 格式,但现今已经有愈来愈多、各色各样的网页格式和标准出现。网页通常用图像来提供图画。网页要通过网页浏览器来阅读。
简单的来说,你在浏览器中见到的任何一个页面,都是网页。
为什么要学习网页知识
学习基础的网页知识最重要的一点,是因为这门课程后续要讲授的技术,都涉及到对网页内容的分析与爬取。哪怕仅仅是作为一名刚入门的爬虫小白,你都需要了解一下网页的相关知识。作为一名开发人员,不仅仅要知其然,更要知其所以然。一味地 Copy 代码,不懂得为什么要这样做,反而会大大降低学习的效果。
网页基础知识
什么是 HTML?
HTML(HyperText Markup Language) 是一种用来描述网页的语言,它是通过“标记标签”来描述网页的。通常来说,我们把 HTML 文档称为 Web 页面。
HTML 示例
GitChat达人课 这是我的第一个标题
这是段落
上述示例中的 、<>包裹住的元素,都可以认为是 HTML 的“标记标签”。需要注意的是,“标题标记”一般都有开始标记和结束标记,普通的标题标记,一般以<标签>内容这样进行使用。接下来我们详细的解释一下上述示例中的“标记标签:
是 HTML 的声明。该方法是为了方便浏览器准确的获取 HTML 的版本,以便于正确的对网页内容进行渲染(关于HTML 版本的问题,你可以参考这篇文章:HTML 标准的版本历史)。是 HTML 的根元素。一个 HTML 文档的所有内容,必须放入此标签内。是 HTML 的元(meta)数据。能够提供 HTML 页面的元信息,比如定义网页的编码方式、针对搜索引擎的关键词管理。是 HTML 文档所包含的所有内容(例如文字、视频、音频等)。用来定义标题。在 HTML 中,h 被确切的定义为标题大小。一共有6级标题,分别是-
是 HTML 页面的段落标签。HTML 中如果对文字另起一行的话,必须使用该元素。
CSS
CSS(Cascading Style Sheets)是用来渲染 HTML 文档中元素标签的样式。常见的 CSS 使用方式有三种:
- 内联:在 HTML 元素中直接使用 “style” 属性。
- 内部样式表:在
内标记内部样式表应该在
部分通过