大数据学习笔记之HBase(二):HBase安装与部署相关
文章目录
- 十一、HBase的安装与部署
- 10.1、Zookeeper集群的正常部署并启动
- 10.2、Hadoop集群的正常部署并启动
- 10.3、解压HBase
- 10.4、修改HBase配置文件
- 10.4.1、hbase-env.sh(HBase的conf目录下)
- 10.4.2、hbase-site.xml
- 10.4.3、regionservers(conf目录下)
- 10.5、替换HBase根目录下的lib目录下的jar包,以解决兼容问题(一般lib下有HBase自带的hadoopjar包,和我们目前运行的hadoop和zookeeper的版本是不兼容的,所以需要全部删掉,修改为我们自己的,修改的时候需要去当前自己运行的系统中找到相关的jar包。)
- 10.6、将整理好的HBase安装目录scp到其他机器节点
- 10.7、将Hadoop配置文件软连接到HBase的conf目录下
- 10.8、启动服务
- 10.9、查看页面
- 十二、HBase常用操作
- 12.1、进入HBase客户端命令操作界面
- 12.2、查看帮助命令
- 12.3、查看当前数据库中有哪些表
- 12.4、创建一张表
- 12.5、向表中存储一些数据
- 12.6、扫描查看存储的数据
- 12.7、查看表结构
- 12.8、更新指定字段的数据
- 12.9、查看指定行的数据
- 12.10、删除数据
- 12.10.1、删除某一个rowKey全部的数据
- 12.10.2、删除掉某个rowKey中某一列的数据
- 12.11、清空表数据
- 12.12、删除表
- 12.13、统计一张表有多少行数据
- 十三、HMaster的高可用
- 13.1、确保HBase集群已正常停止
- 13.2、在conf目录下创建backup-masters文件
- 13.3、在backup-masters文件中配置高可用HMaster节点
- 13.4、将整个conf目录scp到其他节点
- 13.5、打开页面测试
- 十四、HBase和Hadoop的集群类型
- 14.1、单机模式
- 14.2、小型集群
- 14.3、中型集群
- 14.4、大型集群
- 十五、集群配置举例
- 15.1、NameNode/HMaster 常见配置
- 15.2、ResourceManager
- 15.3、DataNode、RegionServer
- 十六、CDH配置
- 16.1、CPU
- 16.2、电源
- 16.3、内存
- 16.4、磁盘
- 16.5、网络
- 十七、容量规划
- 十八、HBase读写流程
- 18.1、HBase读数据流程
- 18.2、HBase写数据流程
- 十九、HBase中的3个重要机制
- 19.1、flush机制
- 19.2、compact机制
- 19.3、split机制
十一、HBase的安装与部署
HBase安装部署之前需要确保HDFS、MapReduce、Yarn、zookeeper已经部署并启动
10.1、Zookeeper集群的正常部署并启动
$ /opt/modules/cdh/zookeeper-3.4.5-cdh5.3.6/bin/zkServer.sh start
10.2、Hadoop集群的正常部署并启动
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/start-dfs.sh
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/start-yarn.sh
也可以通过之前的脚本进行开启
jps检查一下
另一台机器jps检查一下 ResourceManager

页面检查一下

10.3、解压HBase
$ tar -zxf /opt/softwares/hbase-0.98.6-cdh5.3.6.tar.gz -C /opt/modules/cdh/
10.4、修改HBase配置文件
删除conf目录下的.cmd文件
注意:下面的配置文件都可以在HBase的官网中找到,根据关键子可以搜索到,希望自行到官网复制
10.4.1、hbase-env.sh(HBase的conf目录下)

export HBASE_MANAGES_ZK=false : 是否使用HBase自带的zookeeper托管服务,选择不用,我们选择自己搭建zookeeper集群然后去使用。
10.4.2、hbase-site.xml
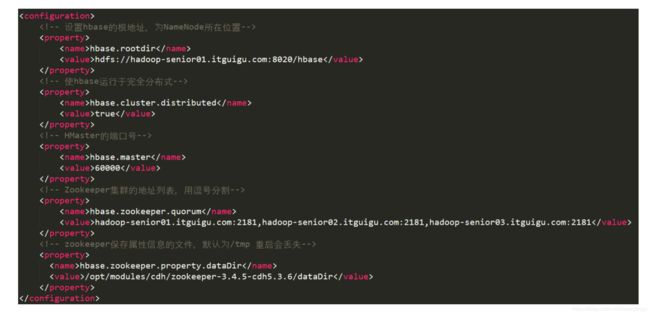
hbase.rootdir : 当前HBase的根目录,这个目录是HDFS系统中的 hdfs://namenode节点的名称:port,如果是高可用的话,比如原来配置的是hdfs://mycluster/hbase
hbase.cluster.distribute : 是否让HBase支持分布式
hbase.master : 指定Hmaster的节点,可以直接写端口号,如上图,6000,表示会高可用,也可以指定ip,比如hadoop-senior01.itguigu.com:6000,意思就是在hadoop-senior01.itguigu.com这台机器上运行Hmaster,在其他的机器上运行RegionServer,但是如果要高可用的话,就不能配置成具体的某个机器,只能,只配置端口号。
hbase.zookeeper.quorum :配置zookeeper的集群,注意zookeeper必须是奇数个。
hbase.zookeeper.property.dataDir :配置属性缓存的文件地址,默认是temp,即重启的话就没了。
10.4.3、regionservers(conf目录下)

10.5、替换HBase根目录下的lib目录下的jar包,以解决兼容问题(一般lib下有HBase自带的hadoopjar包,和我们目前运行的hadoop和zookeeper的版本是不兼容的,所以需要全部删掉,修改为我们自己的,修改的时候需要去当前自己运行的系统中找到相关的jar包。)
- 删除原有Jar包
删除hadoop的jar
$ rm -rf /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/hadoop-*
删除zookeeper的jar
$ rm -rf lib/zookeeper-3.4.6.jar
(尖叫提示:如果lib目录下的zookeeper包不匹配也需要替换)
- 拷贝新的Jar包
这里涉及到的jar包大概是:
hadoop-annotations-2.5.0.jar
hadoop-auth-2.5.0-cdh5.3.6.jar
hadoop-client-2.5.0-cdh5.3.6.jar
hadoop-common-2.5.0-cdh5.3.6.jar
hadoop-hdfs-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-app-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-common-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-core-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-hs-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-hs-plugins-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-jobclient-2.5.0-cdh5.3.6.jar
hadoop-mapreduce-client-jobclient-2.5.0-cdh5.3.6-tests.jar
hadoop-mapreduce-client-shuffle-2.5.0-cdh5.3.6.jar
hadoop-yarn-api-2.5.0-cdh5.3.6.jar
hadoop-yarn-applications-distributedshell-2.5.0-cdh5.3.6.jar
hadoop-yarn-applications-unmanaged-am-launcher-2.5.0-cdh5.3.6.jar
hadoop-yarn-client-2.5.0-cdh5.3.6.jar
hadoop-yarn-common-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-applicationhistoryservice-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-common-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-nodemanager-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-resourcemanager-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-tests-2.5.0-cdh5.3.6.jar
hadoop-yarn-server-web-proxy-2.5.0-cdh5.3.6.jar
zookeeper-3.4.5-cdh5.3.6.jar
我们可以通过find命令快速进行定位,例如我们可以执行:
$ find /opt/modules/ -name hadoop-hdfs-2.5.0-cdh5.3.6.jar
到hadoop的根目录,find -name hadoop-hdfs-2.5.0-cdh5.3.6.jar find 的第二个参数默认是当前目录
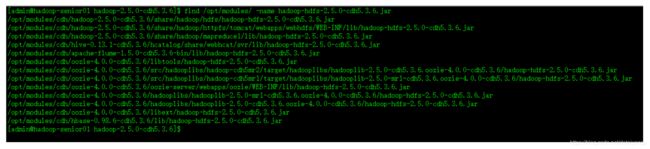
然后将查找出来的Jar包根据指定位置复制到HBase的lib目录下,在这里我给大家整合好到一个文件夹中了,请依次执行:
$ tar -zxf /opt/softwares/CDH_HadoopJar.tar.gz -C /opt/softwares/
$ cp -a /opt/softwares/HadoopJar/* /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/lib/
10.6、将整理好的HBase安装目录scp到其他机器节点
$ scp -r /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
hadoop-senior02.itguigu.com:/opt/modules/cdh/
$ scp -r /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
hadoop-senior03.itguigu.com:/opt/modules/cdh/
10.7、将Hadoop配置文件软连接到HBase的conf目录下
- core-site.xml
$ ln -s /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop/core-site.xml /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/conf/core-site.xml - hdfs-site.xml
$ ln -s /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop/hdfs-site.xml /opt/modules/cdh/hbase-0.98.6-cdh5.3.6/conf/hdfs-site.xml
(尖叫提示:不要忘记其他几台机器也要做此操作)
如果不想软连接的话直接全部拷贝过去也可以
10.8、启动服务
$ bin/hbase-daemon.sh start master
$ bin/hbase-daemon.sh start regionserver
或者:
$ bin/start-hbase.sh
对应的停止命令:
$ bin/stop-hbase.sh
启动完之后jps 会出现HMaster
10.9、查看页面
启动成功后,可以通过主机名:60010地址来访问HBase的管理页面
例如,http://hadoop-senior01.itguigu.com:60010
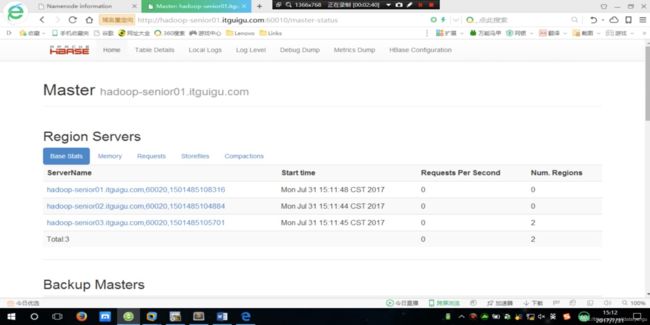
可以看到三个活着的RegionServer
Backup Master是高可用的,还没有配置
zookeeper配置的时候的注意点:
zoo.cfg文件

dataDir这个文件夹默认是没有的,这个目录是需要自己创建的,创建完成之后,需要在每一台机器上的zkData文件下创建myid文件,123
HBase的log日志在logs文件夹下面,比如HBase崩了,查看.log文件,不要看.out文件
大部分出问题都是zookeeper的问题
配置文件可能有问题
hbase.site.xml
hbase.master这个配置在官方文档中是hbase.maste.port,在这里用hbase.maste就行。
hbase.zookeeper.property.dataDir 的内容 /opt/moudles/cdh/zookeeperxxx/dataDir,这个文件是没有的会自动创建,写成任何名字都行,比如/opt/moudles/cdh/zookeeperxxx/aaa
hbase.rootdir的内容默认是file:///的,改成hdfs,后面的DataNode如果是高可用的话,去掉端口号, 只写成集群名称就可以了。
一定要scp到其他机器上,所有机器上都要是一致的
软连接,也可以选择拷贝过来,总之要让HBase持有hadoop的引用。
Habase配置中的hbase.rootdir中的ip端口只需要和 hdfs配置文件中的 fs.DefaultFS这个配置的内容一样就行
到HDFS的页面上查看时候有hbase这个目录
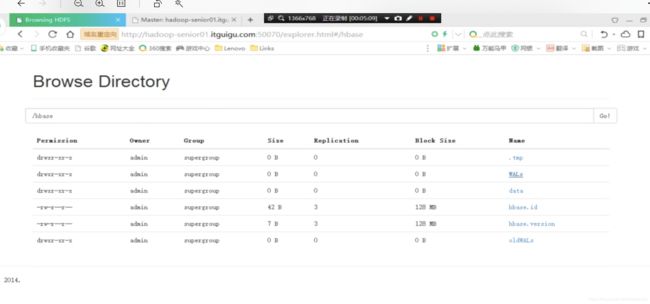
WALs : Hlog的保存目录
oldWALs :老的Hlog
hbase.versoin : hbase的数据是支持版本的,比如之前有一个正常的版本,现在的版本某一天坏了,可以恢复到之前的版本使用
在之前自己写的启动脚本中添加上hbase的启动脚本
start-cluster.sh
#!/bin/bash
echo "========正在开启集群服务======"
ech0 "========正在开启 Namenode节点========"
# 意思就是ssh到这个主机上之后执行后面的启动命令,下面同理
ssh admin@hadoop-senior01.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh start namenode`
echo "========在开启 DataNode节点========"
for i in adminghadoop-seniorol.itguigu.com admin@hadoop-senior02itguigu.com adminghadoop-senior03.itguigu.com
do
ssh $i `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh start datanode`
done
echo "========在开启 SecondaryNamenode节点========"
ssh admin@hadoop-senior03.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh start secondarynamenode`
echo "========正在开启 ResourceManager节点========"
ssh admin@hadoop-senior02.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh start resourcemanager`
echo "========正在开启 NodeManager节点========"
for $i in admin@hadoop-senior0l.itguigu.com admin@hadoop-senior02.itguigu.com admin@hadoop-senior03.itguigu.com
do
ssh i `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh start nodemanager`
done
echo "========正在开启 JobHistory Server节点========"
ssh adminghadoop-senior01.itguigu.com `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/mr-jobhistory-daemon.sh start historyserver`
echo "========正在开启 HBase节点========"
ssh adminghadoop-senior01.itguigu.com `/opt/modules/cdh/-0.98.6-cdh5.3.6/bin/start-hbase.sh`
stop-cluster.sh
#!/bin/bash
echo "========正在关闭集群服务======"
# 意思就是ssh到这个主机上之后执行后面的启动命令,下面同理
echo "========正在关闭HBase节点========"
ssh adminghadoop-senior01.itguigu.com `/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/bin/start-hbase.sh`
echo "========正在关闭JobHistory Server节点========"
ssh adminghadoop-senior01.itguigu.com `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/mr-jobhistory-daemon.sh stop historyserver`
echo "========正在关闭 ResourceManager节点========"
ssh admin@hadoop-senior02.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh stop resourcemanager`
echo "========正在关闭 NodeManager节点========"
for $i in admin@hadoop-senior0l.itguigu.com admin@hadoop-senior02.itguigu.com admin@hadoop-senior03.itguigu.com
do
ssh i `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh stop nodemanager`
done
ech0 "========正在关闭 Namenode节点========"
ssh admin@hadoop-senior01.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh stop namenode`
echo "========在关闭 SecondaryNamenode节点========"
ssh admin@hadoop-senior03.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh stop secondarynamenode`
echo "========在关闭 DataNode节点========"
for i in adminghadoop-seniorol.itguigu.com admin@hadoop-senior02itguigu.com adminghadoop-senior03.itguigu.com
do
ssh $i `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh stop datanode`
done
HBase高可用
在第二台机器执行 bin/start-hbase.sh
发现多了一句话
说明在第二台机器开启HMaster了
刷新一下刚才的页面
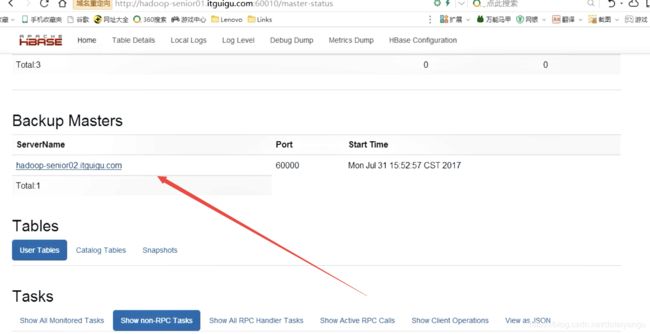
通过在第一台机器个第二台机器执行jps,发现都有HMaster
高可用这里需要注意的是上面的配置文件中
hbase.master : 指定Hmaster的节点,可以直接写端口号,如上图,6000,表示会高可用,也可以指定ip,比如hadoop-senior01.itguigu.com:6000,意思就是在hadoop-senior01.itguigu.com这台机器上运行Hmaster,在其他的机器上运行RegionServer,但是如果要高可用的话,就不能配置成具体的某个机器,只能,只配置端口号。
十二、HBase常用操作
12.1、进入HBase客户端命令操作界面
$ bin/hbase shell
12.2、查看帮助命令
hbase(main):001:0> help
12.3、查看当前数据库中有哪些表
hbase(main):002:0> list

图中的这句话的意思是操作hdfs
12.4、创建一张表
hbase(main):003:0> create ‘student’,‘info’
student表名,info列族名
12.5、向表中存储一些数据
hbase(main):004:0> put ‘student’,‘1001’,‘info:name’,‘Thomas’
hbase(main):005:0> put ‘student’,‘1001’,‘info:sex’,‘male’
hbase(main):006:0> put ‘student’,‘1001’,‘info:age’,‘18’
student:往哪张表中存数据
1001: rowkey
info:name:列族名:列名
Thomas:值
这个操作可以变相的理解为(可能不太准确)

注意上面的列可以无限的增加
12.6、扫描查看存储的数据
hbase(main):007:0> scan ‘student’

COLUMN+CELL 列加单元格
timestamp时间戳,是自动生成进去的
格式:表名+rowkey+列族+列+时间戳+值
或:查看某个rowkey范围内的数据
hbase(main):014:0> scan ‘student’,{STARTROW => ‘1001’,STOPROW => ‘1007’}
STARTROW起始rowkey
STOPROW结束rowkey
注意:前包后不包
如图

如果后面不加的话,就是全扫描,整张表就出来了,数据太多的时候就卡死了,慎重。
12.7、查看表结构
hbase(main):009:0> describe ‘student’
student:表名

12.8、更新指定字段的数据
hbase(main):009:0> put ‘student’,‘1001’,‘info:name’,‘Nick’
hbase(main):010:0> put ‘student’,‘1001’,‘info:age’,‘100’
查看更新后的数据:

类似于map中的覆盖,上面的添加和更新都是这个操作。
12.9、查看指定行的数据
hbase(main):012:0> get ‘student’,‘1001’

或:查看指定行指定列或列族的数据
hbase(main):013:0> get ‘student’,‘1001’,‘info:name’

12.10、删除数据
12.10.1、删除某一个rowKey全部的数据
hbase(main):015:0> deleteall ‘student’,‘1001’
12.10.2、删除掉某个rowKey中某一列的数据
hbase(main):016:0> delete ‘student’,‘1001’,‘info:sex’
12.11、清空表数据
hbase(main):017:0> truncate ‘student’

注意看上图中的提示 disabling table,使表变得不可用,dropping table,删除表,creating table,创建表
如果直接执行drop 操作,会报错

意思还表示可用的需要先将表置位不可用
12.12、删除表
首先需要先让该表为disable状态,使用命令:
hbase(main):018:0> disable ‘student’
然后才能drop这个表,使用命令:
hbase(main):019:0> drop ‘student’
(尖叫提示:如果直接drop表,会报错:Drop the named table. Table must first be disabled)
12.13、统计一张表有多少行数据
hbase(main):020:0> count ‘student’
多少个不同的rowkey
十三、HMaster的高可用
13.1、确保HBase集群已正常停止
$ bin/stop-hbase.sh
13.2、在conf目录下创建backup-masters文件
$ touch conf/backup-masters
13.3、在backup-masters文件中配置高可用HMaster节点
$ echo hadoop-senior02.itguigu.com > conf/backup-masters
13.4、将整个conf目录scp到其他节点
$ scp -r conf/ hadoop-senior02.itguigu.com:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
$ scp -r conf/ hadoop-senior03.itguigu.com:/opt/modules/cdh/hbase-0.98.6-cdh5.3.6/
13.5、打开页面测试
http://hadoop-senior01.itguigu.com:60010

最后,可以尝试关闭第一台机器的HMaster:
$ bin/hbase-daemon.sh stop master
然后查看第二台的HMaster是否会直接启用
十四、HBase和Hadoop的集群类型
14.1、单机模式
主要用于开发工作,一台机器上运行所有的守护进程,或者一台机器运行多个虚拟机。一般用于评估和测试。
14.2、小型集群
20台机器以内的集群,不同的机器运行不同的守护进程,适用于数据量和处理请求较少的小型生产环境。
14.3、中型集群
20到1000台机器集群,3到5个zookeeper节点,适用于成熟的生产环境。
14.4、大型集群
1000台机器以上的集群,属于超大规模集群了,适用于大规模生产环境。
十五、集群配置举例
15.1、NameNode/HMaster 常见配置
内存:16~128G
CPU:2*(8~24)核处理器
硬盘:1TB-SATA硬盘+1个元数据备份盘(转速7200R/MIN+)能使用固态更好。
网卡:2*1GB网卡
为了有更好的性能,所有的元数据都缓存在内存中,因此内存需要拥有较快的速度和较好的质量。大内存意为着可以存储更多的文件,从而支持NameNode更大的命名空间。同时NameNode不需要很大的磁盘,小容量的磁盘就可以满足需求,元数据要存储加载到内存中,数据副本以及修改日志存储在磁盘上。
15.2、ResourceManager
可以运行在NameNode机器上,也可以运行在单独的机器上。硬件配置和NameNode一直,因为只是用于作业分发,因此不需要较大的磁盘和较强的运算能力。
15.3、DataNode、RegionServer
实际的数据存储于这些节点,因此这些节点需要较大的存储和较强的运算能力。较小的集群可以使用一般的磁盘,内存和CPU,如果集群规模较大,可以考虑:
内存:16~128G
CPU:2*(8~24)核处理器
硬盘:2TB,转速7200
网卡:2*1GB
十六、CDH配置
备选资源:
内存:64~512GB
硬盘:1TB~4TB
CPU:2*(824)核CPU,主频22.5GHZ
网卡:千、万兆以太网
16.1、CPU
工作负载核心,推荐DataNode配置为双CPU插槽,配置中等主频的CPU,高端CPU太烧钱,所以我们可以增加数量。
16.2、电源
耐热性,稳定。
16.3、内存
需要足量的内存以保证不需要等待数据频繁的装载到内存中,因此8~48G内存比较合适,HBase会使用大量的内存,将文件存放在内存中(如果开启了内存表的话),对于HBase集群,我们需要比单独的Hadoop集群更大的内存。如果HBase开启缓存,Hbase会尝试将整张表缓存在内存中。
16.4、磁盘
不建议在某台机器上配置很大容量的磁盘,这样当这台机器出现问题,不容易将数据分散到其他机器节点中。必须不能低于SATA 7200转
16.5、网络
Hadoop或者HBase在执行任务,读取数据和写入数据时,会在节点之间传输数据块,因此建议配置高速的网络和交换机。对于中小集群,1GB/s的网络足矣。对于排序和shuffle这类操作,需要节点间传输大量数据,如果带宽不足,会导致一些节点连接超时,比如RegionServer、Zookeeper。
十七、容量规划
运算公式:T = (S* R)* 1.25
尖叫提示:
S表示存储数据量
R表示副本数
T表示整个集群需要的空间
假如存储了10t的数据,在运算的过程中会产生很多临时的小文件,运算完了之后虽然会删掉,但是在运算的过程中,还是会占用空间的,所以应该预留出来一部分,最少预留出来25%,所以最后DataNode需要配置的空间大小是 存储的数据量副本数1.25
十八、HBase读写流程
18.1、HBase读数据流程
HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在的位置信息,即找到这个meta表在哪个HRegionServer上保存着。
接着Client通过刚才获取到的HRegionServer的IP来访问Meta表所在的HRegionServer,从而读取到Meta,进而获取到Meta表中存放的元数据。
Client通过元数据中存储的信息,访问对应的HRegionServer,然后扫描所在HRegionServer的Memstore和Storefile来查询数据。
最后HRegionServer把查询到的数据响应给Client。

18.2、HBase写数据流程
Client也是先访问zookeeper,找到Meta表,并获取Meta表元数据。
确定当前将要写入的数据所对应的HRegion和HRegionServer服务器。
Client向该HRegionServer服务器发起写入数据请求,然后HRegionServer收到请求并响应。
Client先把数据写入到HLog,以防止数据丢失。
然后将数据写入到Memstore。
如果HLog和Memstore均写入成功,则这条数据写入成功
如果Memstore达到阈值,会把Memstore中的数据flush到Storefile中。
当Storefile越来越多,会触发Compact合并操作,把过多的Storefile合并成一个大的Storefile。
当Storefile越来越大,Region也会越来越大,达到阈值后,会触发Split操作,将Region一分为
二。
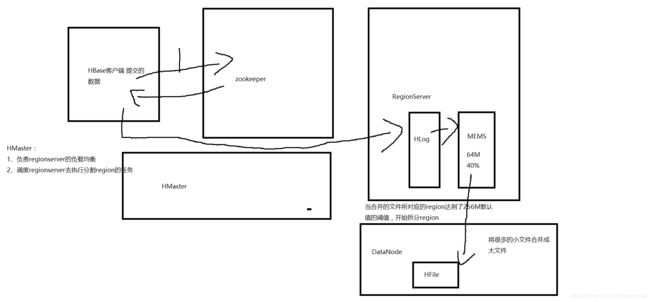 客户端去访问zookeeper,返回HMaster和RegionServer的信息,知道自己要存到哪里,然后访问具体的RegionServer,将数据写到Hlog上面,Hlog刚开始是在本地的,注意Hlog直接创建在HDFS上面是不可能的,HDFS是一次写入多次读取,往Hlog中写成功之后,往MEMS上写,如果在MEMS上写成功的话,在概念上的描述就是这条数据成功的写入了,但是同时会往DataNode上写数据,有两个阈值,64m、当前虚拟机分配给虚拟机的堆内存大小的40%,两者满足其一就开始往HDFS上面写,写上去的就是一个一个的Hfile文件,可是一直都是64m的小文件,显然对于HDFS来说是不合理的,所以降很多的小文件合并成大文件,region达到了256m的默认值,就开始拆分region。如果在写的过程中,HMaster崩了会怎么样?首先了解一下HMaster的作用:1、负责RegionServer的负载均衡,如果当前的RegionServer崩了,就会把当前RegionServer里面的region分发给其他的RegoinServer,这里可能有一个疑问,RegionServer已经崩了,还怎么分发?region的数据实际上是存在hdfs,RegionServer只是服务的进程,负责服务和管理region的,如果RegionServer崩了,就把数据本身通过HMaster调度分发给其他的服务。2、调度RegionServer去执行分割region,如果当前的HMaster崩了,正常的读写流程没有问题,时间长的话会导致RegionServer,某一个regoin特别的大,就会导致regoin上的网络io和磁盘io大量的增加region向zookeeper汇报心跳就会断掉,region可能就因为HMaster这个管理者没有了,自己就死了,接着就会导致,当前的客户端正在进行数据交互,这边突然死了,就导致原数据的丢失。所以在生产环境里面,如果HMaster崩了,需要尽快的恢复它,HMaster尽量实现高可用。
客户端去访问zookeeper,返回HMaster和RegionServer的信息,知道自己要存到哪里,然后访问具体的RegionServer,将数据写到Hlog上面,Hlog刚开始是在本地的,注意Hlog直接创建在HDFS上面是不可能的,HDFS是一次写入多次读取,往Hlog中写成功之后,往MEMS上写,如果在MEMS上写成功的话,在概念上的描述就是这条数据成功的写入了,但是同时会往DataNode上写数据,有两个阈值,64m、当前虚拟机分配给虚拟机的堆内存大小的40%,两者满足其一就开始往HDFS上面写,写上去的就是一个一个的Hfile文件,可是一直都是64m的小文件,显然对于HDFS来说是不合理的,所以降很多的小文件合并成大文件,region达到了256m的默认值,就开始拆分region。如果在写的过程中,HMaster崩了会怎么样?首先了解一下HMaster的作用:1、负责RegionServer的负载均衡,如果当前的RegionServer崩了,就会把当前RegionServer里面的region分发给其他的RegoinServer,这里可能有一个疑问,RegionServer已经崩了,还怎么分发?region的数据实际上是存在hdfs,RegionServer只是服务的进程,负责服务和管理region的,如果RegionServer崩了,就把数据本身通过HMaster调度分发给其他的服务。2、调度RegionServer去执行分割region,如果当前的HMaster崩了,正常的读写流程没有问题,时间长的话会导致RegionServer,某一个regoin特别的大,就会导致regoin上的网络io和磁盘io大量的增加region向zookeeper汇报心跳就会断掉,region可能就因为HMaster这个管理者没有了,自己就死了,接着就会导致,当前的客户端正在进行数据交互,这边突然死了,就导致原数据的丢失。所以在生产环境里面,如果HMaster崩了,需要尽快的恢复它,HMaster尽量实现高可用。
十九、HBase中的3个重要机制
19.1、flush机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile
涉及属性:
hbase.hregion.memstore.flush.size:134217728
即:128M就是Memstore的默认阈值
hbase.regionserver.global.memstore.upperLimit:0.4
即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模式来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.lowerLimit:0.38
即:当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit
19.2、compact机制
把小的Memstore文件合并成大的Storefile文件。
19.3、split机制
当Region达到阈值,会把过大的Region一分为二。