用Python爬取淘宝4403条大裤衩数据进行分析,终于找到可以入手的那一条

炎炎夏日,长裤已难以满足广大男生的需求,为了在搬砖和摆摊的过程中增添一丝舒适感,他们开始寻找一种神奇的存在——大裤衩。J哥在种菜的这些日子里也日益感受到大裤衩的重要性,于是,默默打开了淘宝并搜索了大裤衩,但翻了半天也不知道买啥。
无比懊恼的J哥扔掉了手机,打开电脑并爬取了淘宝4403条大裤衩数据,然后进行了可视化分析,并最终找到一条可以入手的大裤衩。本文主要尝试解决以下几个问题:
- 国内哪些地方的大裤衩卖的比较好?
- 大裤衩市场价格是怎样的?
- 哪些店铺大裤衩销量较高?
- 在售的大裤衩具有哪些特点?
一、数据获取
淘宝网站是一个ajax动态加载的网站,只能通过解析接口或用selenium自动化测试工具去爬取。关于动态网页爬虫,本公众号历史原创文章「实战|Python轻松实现动态网页爬虫(附详细源码)」介绍过,感兴趣的朋友可以了解一下。
本次数据获取采用selenium,由于J哥的谷歌浏览器版本更新较快,导致原来的谷歌驱动失效。于是,我禁用了浏览器自动更新,并下载了对应版本的驱动。
浏览器驱动必须与浏览器版本匹配,否则selenium将失效,这里也给出下载链接:
http://chromedriver.storage.googleapis.com/index.html
接着,J哥利用selenium在淘宝网搜索大裤衩,手机扫码登录,获得了大裤衩的商品名称、商品价格、付款人数、店铺名称、发货地址等信息。限于篇幅,爬虫代码仅给出主函数,感兴趣的朋友可以在公众号后台联系我获取。
1 def main():
2 browser.get('https://www.taobao.com/')
3 page = search_product(key_word)
4 print(page)
5 get_data()
6 page_num = 1
7 while int(page) != page_num:
8 print("-" * 100)
9 print("正在爬取第{}页大裤衩数据".format(page_num + 1))
10 browser.get('https://s.taobao.com/search?q={}&s={}'.format(key_word, page_num*44))
11 browser.implicitly_wait(10)
12 get_data()
13 page_num += 1
14 print("大裤衩数据抓取完成")
15
16 if __name__ == '__main__':
17 key_word = "大裤衩 男"
18 browser = webdriver.Chrome("./chromedriver")
19 main(
二、数据清洗
短短几分钟就爬下了4403条大裤衩样本数据,为了方便数据分析,还需要对原始数据进行简单清洗。
1.导入数据
import pandas as pd
import numpy as np
df = pd.read_csv('big_pants.csv',header=None,
names=['商品名称','商品价格','付款人数','店铺名称','发货地址']) #添加字段名称
df.sample(5) #预览数据
| 商品名称 | 商品价格 | 付款人数 | 店铺名称 | 发货地址 | |
|---|---|---|---|---|---|
| 3984 | 夏季冰丝速干男短裤中老年男士五分裤宽松外穿大裤衩爸爸夏装中裤 | 49.0 | 45人付款 | 爱帝利思旗舰店 | 河北 邢台 |
| 3863 | 我的速度休闲短裤男潮牌ins夏季宽松直筒大裤衩男生纯棉5分五分裤 | 79.8 | 70人付款 | 我的速度曼久专卖店 | 广东 广州 |
| 4203 | 沙滩裤男骚气宽松加肥加大码5分裤ins速干裤肥佬胖子大花裤衩外穿 | 38.0 | 15人付款 | boboggc | 河北 沧州 |
| 1440 | 短裤男士夏季日系宽松休闲五分中裤运动马裤沙滩裤韩版潮流大裤衩 | 9.9 | 432人付款 | 海蜇星旗舰店 | 福建 泉州 |
| 789 | 夏季薄款短裤男ins潮牌青少年大裤衩宽松休闲运动八分7分七分裤子 | 19.9 | 483人付款 | wze旗舰店 | 浙江 杭州 |
2.删除重复记录
df = df.drop_duplicates()
3.查看数据信息
df.info()
Int64Index: 3835 entries, 0 to 4402
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 商品名称 3835 non-null object
1 商品价格 3835 non-null float64
2 付款人数 3835 non-null object
3 店铺名称 3835 non-null object
4 发货地址 3822 non-null object
dtypes: float64(1), object(4)
memory usage: 179.8+ KB
4.缺失值处理
df.dropna(axis=0, how='any', inplace=True)
5.商品价格字段处理
listBins = [0, 50,100, 150, 200, 500,1000000] #设置切分区域
listLabels = ['50及以下','51-100','101-150','151-200','201-500','500及以上']#设置切分后对应标签
df['价格区间'] = pd.cut(df['商品价格'], bins=listBins, labels=listLabels, include_lowest=True) #利用pd.cut进行数据离散化切分
6.发货地址字段处理
df["省份"] = df["发货地址"].str.split(' ',expand=True)[0] #expand=True可以把用分割的内容直接分列
#df['省份'] = df['发货地址'].str.split(' ').apply(lambda x:x[0]) #提取省份
df["城市"] = df["发货地址"].str.split(' ',expand=True)[1] #提取城市
df["城市"].fillna(df["省份"], inplace=True) #城市字段空值用省份非空值填充
7.付款人数字段处理
import re
df['数字'] = [re.findall(r'(\d+\.{0,1}\d*)', i)[0] for i in df['付款人数']] # 提取数值
df['数字'] = df['数字'].astype('float') # 转化数值型
df['单位'] = [''.join(re.findall(r'(万)', i)) for i in df['付款人数']] # 提取单位(万)
df['单位'] = df['单位'].apply(lambda x:10000 if x=='万' else 1)
df['付款人数'] = df['数字'] * df['单位'] # 计算付款人数
8.其他处理
# 删除多余的列
df.drop(['发货地址', '数字', '单位'], axis=1, inplace=True)
#按商品价格降序
df = df.sort_values(by="商品价格", axis=0, ascending=False)
# 重置索引
df = df.reset_index(drop=True)
df.head(10)
| 商品名称 | 商品价格 | 付款人数 | 店铺名称 | 价格区间 | 省份 | 城市 | |
|---|---|---|---|---|---|---|---|
| 0 | 短裤男夏季运动5五分裤7七分休闲中裤子男士宽松沙滩裤大裤衩潮流 | 8948.0 | 124.0 | cys7363583 | 500及以上 | 浙江 | 宁波 |
| 1 | 芬迪小怪兽老佛爷短裤男士夏季运动五分休闲宽松大裤衩沙滩男裤潮 | 1329.0 | 16.0 | 流行时尚潮衣潮鞋 | 500及以上 | 上海 | 上海 |
| 2 | 加大薄款五分裤男弹力加肥冰丝码休闲短裤潮牌胖子宽松中裤大裤衩 | 1159.7 | 3.0 | 樊峥旗舰店 | 500及以上 | 福建 | 泉州 |
| 3 | FILAYU代购短裤男宽松潮牌ins嘻哈运动新款五分大裤衩外穿篮球裤 | 588.0 | 9.0 | xietianyong28 | 500及以上 | 香港 | 香港岛 |
| 4 | 0aape猿人头休闲短裤男士夏季五分中裤子宽松沙滩裤大裤衩潮0bape | 499.0 | 46.0 | 佩渊宗 | 201-500 | 福建 | 泉州 |
| 5 | 猿人头夏季薄款男士短裤宽松情侣女沙滩裤子大裤衩0aape0bapeape | 499.0 | 60.0 | gvw男装 | 201-500 | 福建 | 泉州 |
| 6 | 猿人头男士迷彩短裤夏季沙滩裤大裤衩裤子五分裤潮0aape0bape0ape | 499.0 | 33.0 | gvw男装 | 201-500 | 福建 | 泉州 |
| 7 | 帝折尼男士花短裤夏季沙滩裤大裤衩韩版休闲裤修身裤中裤潮薄 | 480.0 | 5.0 | yonglandemao123 | 201-500 | 浙江 | 台州 |
| 8 | 韩国专柜男士休闲裤子五分沙滩运动中裤口宽松潮流直筒夏季大裤衩 | 429.0 | 5.0 | 仙游轩辕雅阁 | 201-500 | 浙江 | 温州 |
| 9 | 专柜夏季男士亚麻短裤透气白色宽松棉麻沙滩裤五分裤纯棉运动裤衩 | 399.0 | 153.0 | 龙通财 | 201-500 | 上海 | 上海 |
三、数据可视化
数据清洗干净后,接下来就可以做可视化分析了,本次可视化分析主要用到Python的pyecharts库和BI工具。
我们首先来看点有意思的数据,最贵的大裤衩和最便宜的大裤衩的区别。
最贵的大裤衩:

最便宜的大裤衩:
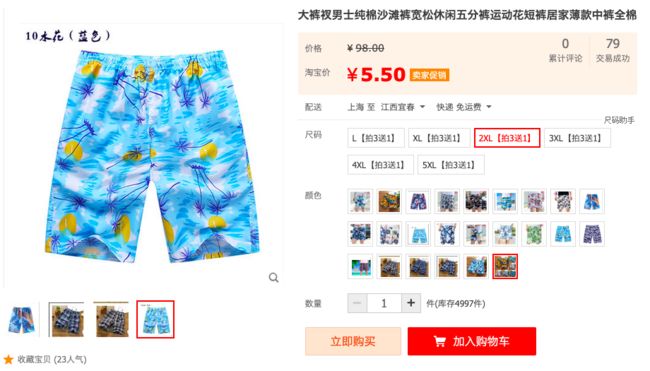
对比一下,不难发现这两条大裤衩的区别,一个风度翩翩,一个花里胡哨。作为一名种菜的民工,风度没暖用(主要还是买不起),便宜无好货的认知在开始学种菜的时候就印刻在J哥的脑海里了,于是J哥继续分析。
1.国内哪些地方的大裤衩卖的比较好?
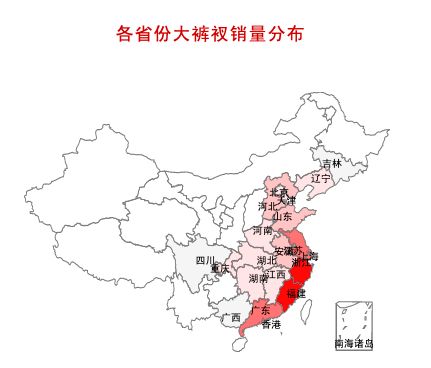
J哥利用省份和付款人数字段数据做了个全国地图,发现福建和浙江这两个地方盛产大裤衩。根据一般的经济学原理,产业集聚更容易带来专业化分工和规模化经营。于是,J哥首先锁定了这两个地方的大裤衩并进一步下钻分析。
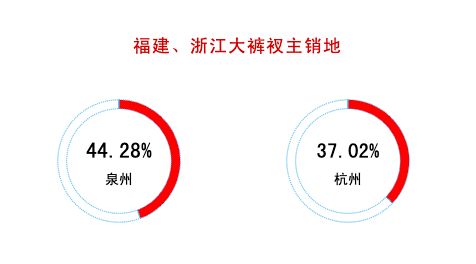
在盛产大裤衩的两个省份中,泉州占到了福建大裤衩的44.28%,杭州占到了浙江大裤衩的37.02%。目标进一步缩小,J哥内心无比激动。
2.大裤衩市场价格是怎样的?

要想买到一条合适的大裤衩,不仅需要分析销量因素,咱们还得分析价格因素。由上图可知,80%的大裤衩价格在50元以下,100元以上的大裤衩占比不到2%。可见,大家对大裤衩的心理价位普遍不高。
3.哪些店铺大裤衩销量较高?
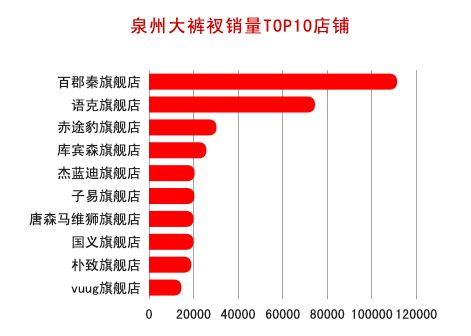

从销量较高的淘宝店铺来看,基本都是旗舰店,看来大家对店铺品牌效应关注度较高。J哥也查了下mystery8090,这是一家专注胖男孩的韩流服饰店,市场定位还是不错的,难怪也获得了不错的销量。
4.在售的大裤衩具有哪些特点?

J哥为了了解大裤衩的特点,对商品名称字段做了文本分析,以浴缸为背景绘制了大裤衩词云图。主要的特点基本上还是看的出来的,在售的大裤衩大都具有宽松、休闲、短、潮流等特点。
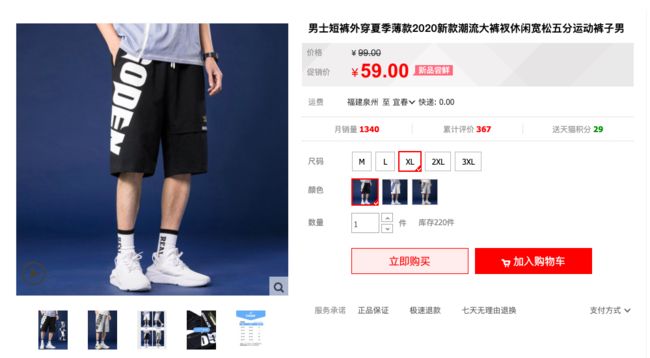
5.选择合适的大裤衩
J哥根据以上分析,同时查看了相关的宝贝评价、好评率等指标,综合分析后,终于找到了以下大裤衩并入手。J哥不经感慨,再也不怕种菜的时候热出翔了!
往期回顾
睡地摊or租房?爬取某大型房产网站24685个房源信息并分析,助你选择
摆地摊or打工,爬取某大型招聘网站3万条招聘信息并分析,作何选择?
实战|Python爬虫并用Flask框架搭建可视化网站
欢迎关注公众号菜J学Python,我们坚持认真写Python基础,幽默写Python实战。你可在公众号后台免费领取相关学习资料或学习交流。
