BeautifulSoup爬虫之保存CSV文件
爬虫保存数据到CSV文件
一.闲话
一般我们写爬虫时都会保存为简单的text文件,但是当我们爬取的数据量很大我们想方便统计或者想存长时间保存 这个时候我们怎么办?我们可以保存信息为CSV格式 或者直接保存到数据库中。python提供了这样的包给我们!接下来我们以“中彩网往期双色球信息”为例给大家演示下如何保存信息CSV格式。
二.干活
依然是爬虫三部曲:分析网页获取目标网址 ,爬取信息,保存信息。
1.分析网页:
中彩网的网址为:”http://www.zhcw.com/ssq/kaijiangshuju/index.shtml?type=0/” 双色球往期回顾页面如下:
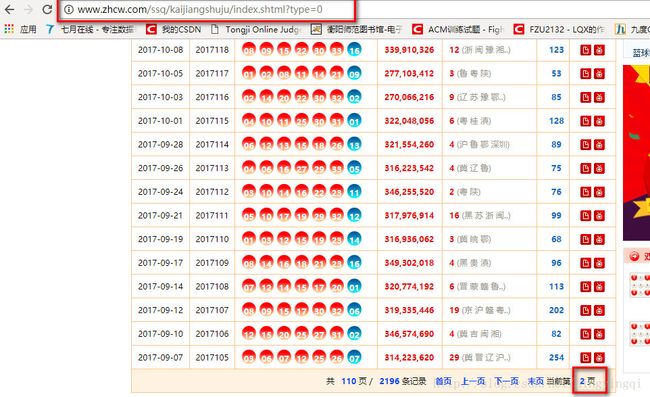
通过分析发现点击下一页地址栏网址没有变化数据是动态加载的,如果爬取这一页只能获取一页的数据,显然这个地址不是最终的地址。我们接着分析网页源码找到我们需要的网址:”http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html”
依旧是分析网址我们得出他的分页规律,为我们以后拼接页数做准备。
2.代码
1)日志文件
#! -*- encoding:utf-8 -*-
"""
乱码问题 解决方式一:#! -*- encoding:utf-8 -*-\
方式二:u'哈哈哈' 字符串以unicode格式存储
"""
import logging
import getpass
import sys
class MyLog(object):
#构造方法
def __init__(self):
self.user=getpass.getuser()
self.logger=logging.getLogger(self.user)
self.logger.setLevel( logging.DEBUG ) #日志的级别 critical error warn info debug
#定义日志文件
self.logFile=sys.argv[0][0:-3]+'.log' # 从命令行参数中取出第一个参数,并取从0开始到 倒数第三个字符 拼接成文件名
self.formatter=logging.Formatter('%(asctime) -12s %(levelname) -8s %(name) -10s %(message)-12s\r\n') #日志输出的格式
#日志输出到文件 logging有三个内置的Handler,
self.logHand=logging.FileHandler(self.logFile, encoding='utf8')
self.logHand.setFormatter( self.formatter ) #设置 格式
self.logHand.setLevel( logging.DEBUG ) #设置 级别
#日志输出 到屏幕,这是标准输出流
self.logHandSt=logging.StreamHandler()
self.logHandSt.setFormatter( self.formatter )
self.logHand.setLevel( logging.DEBUG )
#将两个Handler加入到 logger中
self.logger.addHandler( self.logHand )
self.logger.addHandler( self.logHandSt )
#重新定义logger中的日志输出的级别的方法
def debug(self,msg):
self.logger.debug(msg)
def info(self,msg):
self.logger.info(msg)
def warn(self,msg):
self.logger.warn(msg)
def error(self,msg):
self.logger.error(msg)
def critical(self,msg):
self.logger.critical(msg)
if __name__=='__main__':
mylog=MyLog()
mylog.debug(u'debug测试')
mylog.info(u'info测试')
mylog.warn(u'warn测试')
mylog.error(u'error测试')
mylog.critical(u'critical测试')
2)爬虫代码:
"""
目标地址: http://kaijiang.zhcw.com/zhcw/html/ssq/list_60.html
"""
from MyLog import MyLog
import string
from urllib.parse import quote
from urllib import error
import urllib.request
from bs4 import BeautifulSoup
import codecs
import re
from save2excel import SaveBallDate
#爬取出来的数据封装
class DoubleColorBallItem(object):
date=None
order = None
red1 = None
red2 = None
red3 = None
red4 = None
red5 = None
red6 = None
blue=None
money = None
firstPrize = None
province=None
secondPrize = None
class GetDoubleColorBallNumber( object ):
def __init__(self):
self.urls=[]
self.log=MyLog()
#根据pageSum拼装要爬取的地址
self.getUrls()
#开始爬取
self.items=self.spider( self.urls )
#存
self.pipelines( self.items )
#存入excel
SaveBallDate( self.items)
def getResponseContent(self,url):
try:
url=quote( url, safe=string.printable )
response=urllib.request.urlopen( url )
except error.URLError as e:
self.log.error( u'python爬取 %s 出错了' %url)
print( e )
else:
self.log.info( u'python爬取 %s 成功' %url )
return response.read()
"""
1. 先获取页面上的总页数
2. 拼装 访问 地址
"""
def getUrls(self):
url=r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html' #从第一页中取总页数
htmlContent=self.getResponseContent( url )
soup=BeautifulSoup( htmlContent,'lxml')
pTag=soup.find_all( re.compile('p') )[-1]
pages=pTag.strong.getText().strip()
for i in range( 1, int(pages)-107):
url=r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_'+ str(i)+ '.html'
self.urls.append( url )
self.log.info( u'添加url %s 到 urls列表中待爬取' %url )
def spider( self, urls ):
items=[]
for url in urls:
htmlContent=self.getResponseContent(url)
soup=BeautifulSoup( htmlContent,'lxml')
tags=soup.find_all('tr',attrs={})
for tag in tags:
if tag.find('em'):
item=DoubleColorBallItem()
tagTd=tag.find_all('td')
item.date=tagTd[0].get_text().strip()
item.order=tagTd[1].get_text().strip()
tagEms=tagTd[2].find_all('em')
item.red1=tagEms[0].get_text().strip()
item.red2=tagEms[1].get_text().strip()
item.red3=tagEms[2].get_text().strip()
item.red4=tagEms[3].get_text().strip()
item.red5=tagEms[4].get_text().strip()
item.red6=tagEms[5].get_text().strip()
item.blue=tagEms[6].get_text().strip()
item.money=tagTd[3].find('strong').get_text().strip()
item.firstPrize=tagTd[4].find('strong').get_text().strip()
item.province=tagTd[4].get_text().strip()
item.secondPrize=tagTd[5].find('strong').get_text().strip()
items.append( item )
self.log.info( u'爬取时间为 %s 的数据成功' %(item.date))
return items
def pipelines( self, items ):
fileName=u'双色球中奖信息.txt'
with codecs.open( fileName,'w','utf8') as fp:
for item in items:
fp.write('%s %s \t %s %s %s %s %s %s %s \t %s %s %s %s \n' %(item.date,item.order,item.red1,item.red2,item.red3,item.red4,item.red5,item.red6,item.blue,item.money,item.firstPrize,item.province,item.secondPrize))
self.log.info( u'期数为 %s 的双色球信息保存成功' %(item.order) )
if __name__=='__main__':
gbn=GetDoubleColorBallNumber()3)今天的重点—->保存为CSV文件
python 提供了xlrd,xlwt两个模块给我们读写CSV文件具体的用法请查看他的api(未安装记得安装:pip install xlwt)我这里只讲实战 嘻嘻!
#! -*- encoding:utf-8 -*-
import xlrd
import xlwt
import os
import sys
class SaveBallDate(object):
def __init__(self,items):
self.items=items
self.run(self.items)
def run(self,items):
fileName='hello.csv'
#创建工作簿
book=xlwt.Workbook(encoding='utf8')
sheet=book.add_sheet('ball',cell_overwrite_ok=True)
#写入
sheet.write(0,0,u'开奖日期')
sheet.write(0,1, u'期号')
sheet.write(0,2, u'红球1')
sheet.write(0,3, u'红球2')
sheet.write(0,4, u'红球3')
sheet.write(0,5, u'红球4')
sheet.write(0,6, u'红球5')
sheet.write(0,7, u'红球6')
sheet.write(0,8, u'蓝球')
sheet.write(0,9, u'销售金额')
sheet.write(0,10, u'一等奖')
sheet.write(0,11, u'中奖省份')
sheet.write(0,12, u'二等奖')
i=1
while i1]
sheet.write(i,0,item.date)
sheet.write(i, 1, item.order)
sheet.write(i, 2, item.red1)
sheet.write(i, 3, item.red2)
sheet.write(i, 4, item.red3)
sheet.write(i, 5, item.red4)
sheet.write(i, 6, item.red5)
sheet.write(i, 7, item.red6)
sheet.write(i, 8, item.blue)
sheet.write(i, 9, item.money)
sheet.write(i, 10, item.firstPrize)
sheet.write(i, 11, item.province)
sheet.write(i, 12, item.secondPrize)
i+=1
book.save(fileName) 结果:
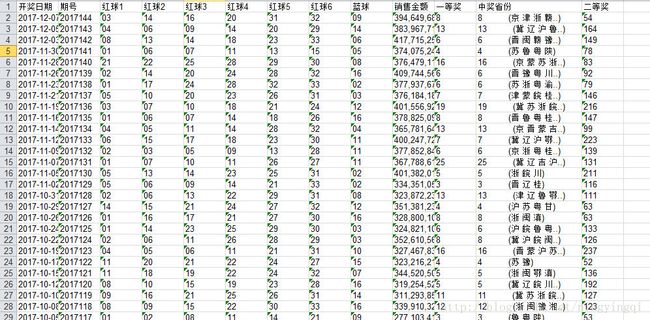
记得导入from save2excel import SaveBallDate以及在init函数添加保存CSV的函数

下一次我们讲解如何将爬取的数据保存到mysq数据库当中!!!