股票操作之强化学习基础(二)(Q-learning、Sarsa、Sarsa-lambda)
股票操作之强化学习基础(二)(Q-learning、Sarsa、Sarsa-lambda)
1. Q-learning
Q-learning是强化学习一个比较基础的算法,很多强化学习的升级算法都是在q-learning的基础上进行升级的。

举个简单的例子:一个人在位置1,他需要到位置6,每次可以向左或者向右移动,但是他不知道位置6在他最右边,他只能自己去摸索如何到位置6。已知条件有在各个状态下向左或向右可到达的位置,到达6位置可以获得10奖励。
那他该怎么去学习呢?
Q-learning的一个核心就是对Q-table的学习,Q其实是quality的缩写。Q-table其实就是在当前状态不同动作的价值评估矩阵。状态在这个例子中可以表示为人所在的位置,动作的话包括向左移动和向右移动两个动作。这个Q-table的初始化可以表示成如下:
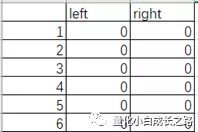
Q-table中的值就是quality。那他怎样去学习这个Q-table呢。
Step 1:根据Q-table中各个动作的价值,采用贪婪策略选择动作,以一个概率选择一个动作(优先选价值高的动作),从当前状态移动到下一个状态。(如果在位置1向左移动则还在位置1)
Setp 2:更新Q-table
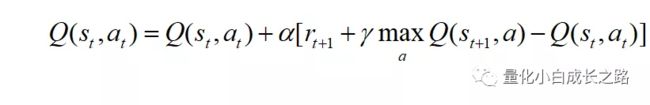
解释一下St 表示t时刻所在状态(state),at 表示t时刻动作(action),Q(St , at)表示在St 状态下at 动作的价值。R(St , at )表示在St 状态下通过动作at+1 可获得的奖励(reward),St+1 表示在St 状态下通过动作at+1 可到达的状态。max Q(St+1 , a) 表示在St+1 状态下不同动作的最大价值。gamma表示衰减率,其目的是为了让我们更加注重一个当下动作的价值;目前没有想到好的解释,可以设想一下如果gamma等于0或者1时我们的Q-table都是不好更新的。a其实就是学习率,可以理解为梯度下降算法中的学习率。
rt+1 + gammamax Q(St+1 , a) 其实就是一个期望的Q值,Q(St , at )就是一个当前Q值,rt+1 + gammamax Q(St+1 , a) - Q(St , at ) 就是期望Q值与当前Q值的差,通过不断的学习这个差值更新Q值。(有点像神经网络的反向传播算法 back-propagation)
Step 3:如果到达位置6获得奖励,一回合的更新结束进行下一回合更新,也就是重复step1和step2。
嗯可能比较难理解,大家可以看看其他参考资料,跑跑别人的Q-learning代码再自行理解。大家可以自行上网搜索Q-learning算法资料,也可以看昨天推荐莫烦的强化学习入门。
Q-learning的伪代码如下:

伪代码中选择下一步的动作是利用贪婪规则选取的,就是以一定概率先选取价值最大的那步,也有一定概率选择其他动作。
Q-learning是一种off-policy算法,翻译一下就是离线线学习,接下来介绍另外一种on-policy算法,翻译一下就是在线学习。这两者的区别可以看具体伪代码之间的区别。
Sarsa
Sarsa是一种on-policy算法。
其伪代码如下:

Sarsa算法和Q-learning算法相似,其目的都是为了求得Q-table的近似解。他们之间的区别可以看下面这幅图。

仔细看上图中的框出来的区别Sarsa的学习过程和Q-Learning基本一样,不同的地方是在于更新Q值时稍有差异。
Q-learning期望Q与当前Q的error为: rt+1 + gamma*max Q(St+1 , a) - Q(St , at)
Sarsa期望Q与当前Q的error为: rt+1 + gamma*max Q(St+1 , at+1) - Q(St , at)
Q-learning在计算error时取下一状态的最大Q值减去当前Q值,而Sarsa则需要将下一状态的动作先确定,再计算期望Q值。
Q-Learning在走下一步的时候是先看下一步应该走哪,但是最后不一定走,而Sarsa是决定完要走的步之后一定会去走那一步。换句话说,Q-Learning在更新当前位置的Q值的时候会参考表中收益最大的那个值,但下一步不一定会走到那个位置,而Sarsa是先选取下一步要走的位置的Q值来更新当前位置的Q值,当然,选完它下一步一定会去走那一步。
Sarsa虽然说是说到做到,但是由于它选取下一步的位置是严格按照已有学习到的经验来选择,所以它探索未知位置的能力就会很差,相对于说了不一定算的Q-Learning来说,反而Q-Learning更勇敢一些。(这段话引自[1])
我们可以理解成Q-learning 是一种贪婪, 大胆, 勇敢的算法, 对于错误, 死亡并不在乎. 而 Sarsa 是一种保守的算法, 他在乎每一步决策, 对于错误和死亡比较敏感. 两种算法都有他们的好处, 比如在实际中, 你比较在乎机器的损害,用一种保守的算法, 在训练时就能减少损坏的次数. (这段话引自[2]) 目前我自己也还不太理解为什么Sarsa更保守一些。
总结一下on-policy与 off-policy的本质区别,其本质区别在于:更新Q值时所使用的方法是沿用既定的策略(on-policy)还是使用新策略(off-policy)。[3]
Sarsa-lambda
Q-learning和 Sarsa都是单步更新的算法。单步更新的算法缺点有:虽然单步更新每一步都在更新,但是在没有获取到reward的时候,其每一步更新都是无用的,除此之外最重要一点当第一次获取到宝藏时只会更新获取宝藏的上一个位置的Q值。第二次获得宝藏时只会更新获得宝藏的前两步。第三次则前三步,以此类推。
Sarsa-lambda:为了解决单步更新算法的缺点,Sarsa-lambda(Sarsa的升级算法)加快Sarsa的收敛速度。
先大概看一看Sarsa-lambda的伪代码:

伪代码中加入了eligibility矩阵(伪代码中的E),eligibility翻译为合适,其用来记录在获得reward的过程中,其存在不可或缺的路径。
然后我们再分析一下伪代码的修改。
首先下图这一步与Sarsa类似,第一个区别在于,Sarsa-lambda计算出期望Q值与当前Q值的error后不进行更新而是将其记录在一个矩阵中;第二个区别在于记录这个状态下的某个动作的出现次数(出现次数+1)

然后再看新的更新步骤,与Sarsa的更新不同在于,Sarsa-lambda每进行一个动作之后,会对整个Q-tabel进行更新,而Sarsa算法只会对当前状态下进行的动作的Q值进行更新,这是不同之处一。不同之处二在于Sarsa-lambda在更新时除了要乘以学习率还要乘以E值(也就是不可或缺性)。除此之外E矩阵也会进行更新,下图中的gamma是衰减性,gamma值越小则越不看重之前步骤。lambda是Sarsa-lambda中的lambda,如果lambda=0,则会变成一个单步更新;如果lambda=1,则是回合更新。Lambda与gamma在这里的作用似乎有些相似。

总结
今天这篇文章比较偏理论,讲的比较简单,大家可以看看其他资料加强自己的理解,我也只是从算法的层次上写了自己的一点理解。当然今天讲的强化学习还未结合神经网络.
参考资料:
[1]https://www.jianshu.com/p/91fbc682fb3e
[2]https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/3-1-tabular-sarsa1/
[3]https://zhidao.baidu.com/question/2079619689603473628.html
对量化、数据挖掘、深度学习感兴趣的可以关注公众号,本人不定期分享有关这些方面的研究。

个人知乎:
https://www.zhihu.com/people/e-zhe-shi-wo/activities