爬爬看:爬取GitHub项目Zip文件,并保存解压.
前言
最近在学习崔庆才大佬的网络爬虫课程,难免要用到他GitHub上课源代码.但项目很多,一个个下载这种事情,显得很愚蠢.我作为一个程序员,宁愿用一天来写一个代码,也不要用十分钟来手动下载(`へ´*)ノ.
目标站点分析
这次我们要下载的zip文件链接是这样的:
![]()
我们只要爬取关键词"DouYin"就能构造一个zip链接.
修改"page"参数就能修改爬取页面:
![]()
HTML下载器
HTML下载器用到了requests库的get方法,这里没啥好介绍的,直接附上代码:
def getHTML(offset):
url = 'https://github.com/Python3WebSpider?page=' + str(offset)
r = requests.get(url)
try:
if r.status_code == 200:
return (r.text)
except:
print('链接失败!')
HTML解析器
这里用到两种方法,正则表达式和BeautifulSoup解析器.

我们要爬取的对象是"h3"标签的子标签—“a"的string属性"DouYin”.
方法一:
def parsePage1(html,urllist,namelist):
pattern = re.compile('.*?(.*?).*?
', re.S)
items = re.findall(pattern, html)
for item in items:
zipurl = 'https://github.com/Python3WebSpider/' + item[9:] + '/archive/master.zip'
urllist.append(zipurl)
namelist.append(item[9:])
方法二:
def parsePage2(html, urllist, namelist):
soup = BeautifulSoup(html, 'html.parser')
data = soup.find_all('h3')
for item in data:
a = item('a')
for item in a:
print(item.string)
zipurl = 'https://github.com/Python3WebSpider/' + item[9:] + '/archive/master.zip'
urllist.append(zipurl)
namelist.append(item[9:])
Zip下载器
下载器主要用到urllib库的urlretrieve函数,urlretrieve函数可以下载服务器的资源.
def downloadZip(urllist, namelist):
count = 0
dir = os.path.abspath('.')
for item in urllist:
if os.path.exists(os.path.join(dir, namelist[count] + '.zip')):
count = count +1
else:
try:
print('正在下载' + namelist[count])
work_path = os.path.join(dir, namelist[count] + '.zip')
urllib.request.urlretrieve(item,work_path)
count = count + 1
except:
continue
Zip解压并删除
值得注意的是GitHub的服务器地址在国外,如果下载的zip文件如果过大,就会导致下载错误.如果解压失败的话,就用except进行重新下载.
def unZip():
file_list = os.listdir(r'.')
for file_name in file_list:
if os.path.splitext(file_name)[1] == '.zip':
try:
print('正在尝试解压' + file_name)
file_zip = zipfile.ZipFile(file_name, 'r')
for file in file_zip.namelist():
file_zip.extract(file, r'.')
file_zip.close()
os.remove(file_name)
except:
#如果解压失败则删除文件并重新下载.
name = os.path.splitext(file_name)[0]
os.remove(file_name)
zipurl = 'https://github.com/Python3WebSpider/' + name + '/archive/master.zip'
try:
print('正在下载' + name)
work_path = os.path.join(dir, name + '.zip')
urllib.request.urlretrieve(zipurl, work_path)
except:
continue
总结
- 由于我爬取的项目主页面只有两页,我采用的是手动修改的方式更改爬取页面,这里可以酌情修改;
- 个别文件会因为文件过大和网络错误导致失败,这时可以手动下载;
- 由于技术原因,这套代码还不够健壮,欢迎提出你的建议;
- 最后附上爬取成功并解压的截图和全代码;
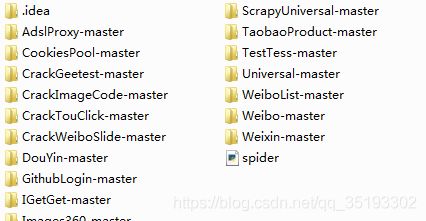
import os
import urllib.request
import requests
import re
from bs4 import BeautifulSoup
import zipfile
def getHTML(offset):
url = 'https://github.com/Python3WebSpider?page=' + str(offset)
r = requests.get(url)
try:
if r.status_code == 200:
return (r.text)
except:
print('链接失败!')
def parsePage1(html,urllist,namelist):
pattern = re.compile('.*?(.*?).*?
', re.S)
items = re.findall(pattern, html)
for item in items:
zipurl = 'https://github.com/Python3WebSpider/' + item[9:] + '/archive/master.zip'
urllist.append(zipurl)
namelist.append(item[9:])
def parsePage2(html, urllist, namelist):
soup = BeautifulSoup(html, 'html.parser')
data = soup.find_all('h3')
for item in data:
a = item('a')
for item in a:
print(item.string)
zipurl = 'https://github.com/Python3WebSpider/' + item[9:] + '/archive/master.zip'
urllist.append(zipurl)
namelist.append(item[9:])
def downloadZip(urllist, namelist):
count = 0
dir = os.path.abspath('.')
for item in urllist:
if os.path.exists(os.path.join(dir, namelist[count] + '.zip')):
count = count +1
else:
try:
print('正在下载' + namelist[count])
work_path = os.path.join(dir, namelist[count] + '.zip')
urllib.request.urlretrieve(item,work_path)
count = count + 1
except:
continue
def unZip():
file_list = os.listdir(r'.')
for file_name in file_list:
if os.path.splitext(file_name)[1] == '.zip':
try:
print('正在尝试解压' + file_name)
file_zip = zipfile.ZipFile(file_name, 'r')
for file in file_zip.namelist():
file_zip.extract(file, r'.')
file_zip.close()
os.remove(file_name)
except:
name = os.path.splitext(file_name)[0]
os.remove(file_name)
zipurl = 'https://github.com/Python3WebSpider/' + name + '/archive/master.zip'
try:
print('正在下载' + name)
work_path = os.path.join(dir, name + '.zip')
urllib.request.urlretrieve(zipurl, work_path)
except:
continue
def main():
urllist = []
namelist = []
html = getHTML(2)
parsePage1(html, urllist, namelist)
downloadZip(urllist, namelist)
unZip()
main()