okhttp、okio添加参数(addParams)出现的java.lang.IllegalArgumentException:Unexpected code point
这是我们项目,收集到的,用户出现过不少次的一个问题。根据堆栈发现是出现在用户修改自己的个人资料时出现的。
项目的网络框架用的是okhttp,在bugly上的样子如下图

查看堆栈信息,找到抛出这个异常的地方,在okhttp的okio这个jar包的Buffer类中,的writeUtf8CodePoint()这个方法中
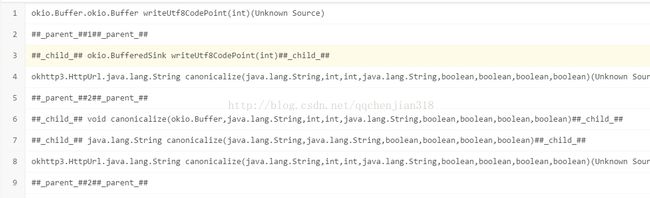
Buffer类的源码如下
@Override public Buffer writeUtf8CodePoint(int codePoint) {
if (codePoint < 0x80) {
// Emit a 7-bit code point with 1 byte.
writeByte(codePoint);
} else if (codePoint < 0x800) {
// Emit a 11-bit code point with 2 bytes.
writeByte(codePoint >> 6 | 0xc0); // 110xxxxx
writeByte(codePoint & 0x3f | 0x80); // 10xxxxxx
} else if (codePoint < 0x10000) {
if (codePoint >= 0xd800 && codePoint <= 0xdfff) {
throw new IllegalArgumentException(
"Unexpected code point: " + Integer.toHexString(codePoint));//可能抛出异常的地方 A
}
// Emit a 16-bit code point with 3 bytes.
writeByte(codePoint >> 12 | 0xe0); // 1110xxxx
writeByte(codePoint >> 6 & 0x3f | 0x80); // 10xxxxxx
writeByte(codePoint & 0x3f | 0x80); // 10xxxxxx
} else if (codePoint <= 0x10ffff) {
// Emit a 21-bit code point with 4 bytes.
writeByte(codePoint >> 18 | 0xf0); // 11110xxx
writeByte(codePoint >> 12 & 0x3f | 0x80); // 10xxxxxx
writeByte(codePoint >> 6 & 0x3f | 0x80); // 10xxxxxx
writeByte(codePoint & 0x3f | 0x80); // 10xxxxxx
} else {
throw new IllegalArgumentException(
"Unexpected code point: " + Integer.toHexString(codePoint));//可能抛出异常的地方 B
}
return this;
}大于0xd800 并且小于0xdfff的范围,是做其他用的(详情可参看Unicode编码以及Utf-8等相关知识),而大于0x10ffff是超出了Unicode的编码范围的。
现在我们需要知道这个方法在哪里被调用的,以及codePoint是什么东西,怎么来的?
最终我们找到了okhttp3这个jar包中的HttpUrl这个类中的canonicalize这个方法中,该方法源码如下
static void canonicalize(Buffer out, String input, int pos, int limit, String encodeSet,
boolean alreadyEncoded, boolean strict, boolean plusIsSpace, boolean asciiOnly) {
Buffer utf8Buffer = null; // Lazily allocated.
int codePoint;
for (int i = pos; i < limit; i += Character.charCount(codePoint)) {
codePoint = input.codePointAt(i);
if (alreadyEncoded
&& (codePoint == '\t' || codePoint == '\n' || codePoint == '\f' || codePoint == '\r')) {
// Skip this character.
} else if (codePoint == '+' && plusIsSpace) {
// Encode '+' as '%2B' since we permit ' ' to be encoded as either '+' or '%20'.
out.writeUtf8(alreadyEncoded ? "+" : "%2B");
} else if (codePoint < 0x20
|| codePoint == 0x7f
|| codePoint >= 0x80 && asciiOnly
|| encodeSet.indexOf(codePoint) != -1
|| codePoint == '%' && (!alreadyEncoded || strict && !percentEncoded(input, i, limit))) {
// Percent encode this character.
if (utf8Buffer == null) {
utf8Buffer = new Buffer();
}
utf8Buffer.writeUtf8CodePoint(codePoint);
while (!utf8Buffer.exhausted()) {
int b = utf8Buffer.readByte() & 0xff;
out.writeByte('%');
out.writeByte(HEX_DIGITS[(b >> 4) & 0xf]);
out.writeByte(HEX_DIGITS[b & 0xf]);
}
} else {
// This character doesn't need encoding. Just copy it over.
out.writeUtf8CodePoint(codePoint);
}
}
}在出现问题的地方,对每个参数进行如下代码的检查
private boolean checkIsUnLawful(String[] input){
if (input != null && input.length> 0){
for (int i = 0; i < input.length; i++) {
String length = input[i];
int codePoint;
if (!TextUtils.isEmpty(length)){
for (int j = 0; j < length.length(); j += Character.charCount(codePoint)) {
codePoint = length.codePointAt(j);
if ((codePoint >= 0xd800 && codePoint <= 0xdfff) || codePoint > 0x10ffff) {
return false;
}
}
}
}
}
return true;
}问题就可以解决了