记一次Pyhthon爬虫其之一——提交表单、模拟登录
背景
python学习已经2个月了,教程中的基本部分已经全部过了一遍,于是我决定找一个东西练练手,知乎上有这么一个问题:Python 的练手项目有哪些值得推荐?,全部看完后,虽然其中有用的东西很多,但能让我理立刻提起兴趣的项目却没有(除了2048那个),所以后来我决定通过python来爬取我校所有学生的成绩。
本来,学生成绩是只有自己能看到的,但我们学校教务处的登录密码是统一的,虽然可以修改,但只有极少一部分人改了,这为我爬取数据提供了方便。
我打算将这次的爬虫记录分成三个部分,(一)获取页面(GET)、提交表单(POST)、模拟登录(修改HTTP头)。(二)验证码识别。(三)爬取数据。
(爬虫的本质是将人工需要花费大量时间获取的合法数据,用程序在短时间获取到,所以我个人认为利用教务处密码统一的漏洞来爬取本来不可能拿到的数据是有违道德的,也应该是违法的,所以这几篇东西,我不会提到任何敏感的东西,也不会放上所有的代码,只有核心功能的部分罢了)
果然教务系统在新学期被换成别的第三方系统的了..
思路
整个登录、爬取的流程如下:
至于学号循环、计数这些属于基础,这里不提及。
其实细分下来,东西还是挺多的:请求验证码、识别验证码(二值化、去噪、切割、识别)、构建data和hear、获取cookie、模拟POST与GET、写表格等。
代码
获取验证码并储存cookie
from urllib import request
import http.cookiejar
ValidateCode = 'http://#######/.../ValidateCode.aspx'
#验证码地址
cookie = http.cookiejar.CookieJar()
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
picture = opener.open(ValidateCode).read()
local = open('e:/image.png', 'wb')
local.write(picture)
local.close()
编造data与head模拟登录
from urllib import request,parse
from html.parser import HTMLParser
import urllib
def logon(username,cCode):
PostUrl = 'http://#######/.../index_LOGIN.aspx'
username = username
#学号由学号循环函数传入
password = '666666'
cCode = cCode
#验证码由验证码识别函数传入
#构建登录data
login_data = parse.urlencode([
('__VIEWSTATE', ''),
('typeName', ''),
('Sel_Type', ''),
('UserID',username),
('PassWord',password),
('cCode', cCode)
])
req = request.Request(PostUrl)
#构建登录head
req.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'),
req.add_header('Accept-Encoding','gzip, deflate'),
req.add_header('Accept-Language', 'zh-Hans-CN, zh-Hans; q=0.7, ja; q=0.3'),
req.add_header('Cache-Control', 'no-cache'),
req.add_header('Connection', 'keep-alive'),
req.add_header('Content-Length', '4303'),
req.add_header('Content-Type','application/x-www-form-urlencoded'),
req.add_header('Cookie','XOXOXOXOXXO'),
req.add_header('Host','@@@@@@@@@@@'),
req.add_header('Referer','######'),
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'),
with request.urlopen(req,data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason)
return(f.read().decode('GBK'))
#输出登录后的页面的内容解释
一般来讲,服务器就是依靠cookie来确定用户身份,例如,获取验证码、登录页面时会在给你一个验证码的同时生成一个cookie,并且将这个cookie也发送给你。登录时的会先检查cookie来确定你是哪个用户(给你发了哪个验证码),对得上才会进行后面的步骤。同理,登录成功后,也依靠这个cookie来确定你的身份,来看你有没有进行相关操作的权限。
(不过也有很多cookie一直变动或用了其他辅助手段的网站,这里不讲这个,我也是菜鸡一个,见得并不多。)
第一段代码为获取验证码并进行储存的函数,使用了http.cookiejar.CookieJar与
request.HTTPCookieProcessor构造opener,目的是在获取到验证码后,取出服务器返回的响应head中的cookie并进行储存。
(实际上我校服务器的cookie可以反复使用,这也就是为什么第二部分的登录函数的参数只有2个:用户名、验证码。但按理来说,cookie是应当每次获取使用后失效的,所以获取验证码的函数应该这么写。)
如果你看到有些教程里出现了’import urllib2’、’import cookielib’,然后你照着做报错的,注意,urllib2在python3里被合并到urllib中,成为request,应当 from urllib import request 。cookielib无法被单独import,应当以improt http.cookielib。
第二段代码为构建data以及构建head进行模拟登录(POST),登录后读取一下页面,查看登录的情况:帐号密码错误、验证码错误、登录成功。读取后判断页面是否存在相关字符串即可。
要构建data和head,首先需要知道这两个东西的具体格式,不同的网站是不同的,所以需要自行进行构建。head用一般的浏览器即可看到(按F12),这里使用edge。
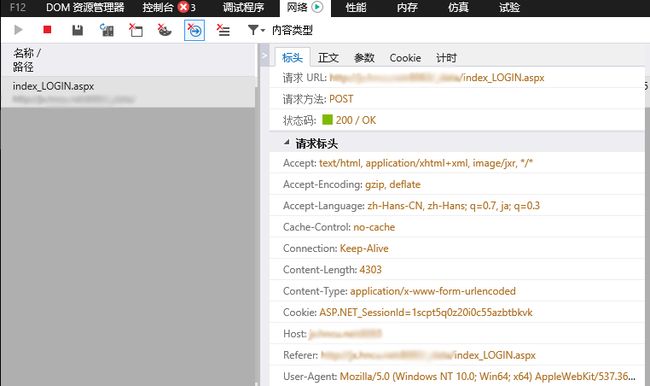
照着构建head即可。
#构建登录head
req.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'),
req.add_header('Accept-Encoding','gzip, deflate'),
req.add_header('Accept-Language', 'zh-Hans-CN, zh-Hans; q=0.7, ja; q=0.3'),
req.add_header('Cache-Control', 'no-cache'),
req.add_header('Connection', 'keep-alive'),
req.add_header('Content-Length', '4303'),
req.add_header('Content-Type','application/x-www-form-urlencoded'),
req.add_header('Cookie','XOXOXOXOXXO'),
req.add_header('Host','@@@@@@@@@@@'),
req.add_header('Referer','######'),
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'),
而data则需要抓包,自行搜索http抓包有一堆东西,我这里用的是Wireshark
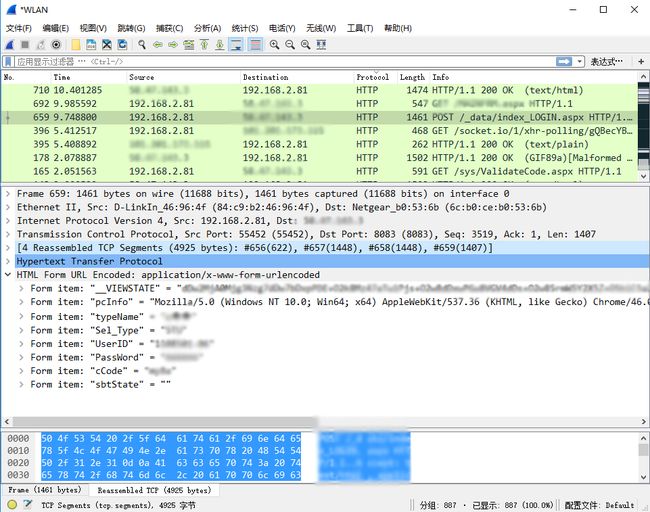
明文,没有进行加密,同样照着构建data即可。
#构建登录data
login_data = parse.urlencode([
('__VIEWSTATE', ''),
('typeName', ''),
('Sel_Type', ''),
('UserID',username),
('PassWord',password),
('cCode', cCode)
])
req = request.Request(PostUrl) 而head和data都构建好后,登录就非常的简单了。
前面有提到,我校服务器的cookie不会自动废弃,可以重复使用,所以我在实际使用时,并未使用第一段的获取验证码及cookie的函数,而是使用了类似第二段模拟登录代码的方法。自带head去请求验证码(模拟刷新验证码),然后直接保持head中的cookie不变,在模拟登录中同样使用同样的cookie进行登录及以后的操作。甚至可以自己随手敲cookie来用。
总结
模拟登录其实很简单,但自己从0做起确实做了两天,大部分时间处在百度中。python2与python3的一些语法不同的地方和一些发生了变化的库也耗费了我大量时间。当初做完模拟登录,以为剩下的东西就很简单了,大概也就两天的样子,结果一个验证码识别就折腾了我四天。
剩下两篇:验证码识别与拉取数据并保存。