2018秋招面试问题(七、C++基础问题)
注:面试过程中整理的学习资料,如有侵权联系我即刻删除。
目录
上亿万数量级的海量查询,比如十亿订单中,找出前一百个销量最好的产品
对于一个海量的文件中存储着不同的URL,用最小的时间复杂度去除重复的URL
给定a、b两个文件,各存放50亿个ur,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
对于海量数据,用什么数据结构存储用户搜索的高频关键词比较合适?比如,当用户输入“黄”字,输入框要自动显 示“黄晓明”,“黄蓉”,“黄山”,“黄鹤楼”等提示,但是能存储的量很有限,所以需要选择恰当的数据结构。
哈夫曼树
用#define声明一个常数,表明1年中有多少秒(忽略闰年问题)?
c++关键字voatile
C++中下列数据类型所占的字节数以及数值表示范围
编译语言和解释语言
系统函数和库函数的比较
如何判断一个整数是否是某个数的平方
C++异常处理机制
析构函数能不能抛出异常?为什么
C++中对象的生命周期
函数指针、指针函数分别是什么?
x&(-x)返回是是什么?比如若x = 2^31-4
二叉排序树查找一个数的时间复杂度
不用if,switch,三目运算符来输出较大的数或者较小的数?
用C++程序写代码来判断一个操作系统是16位还是32位的?
如何判断一段程序是C编译的还是C++编译的?
char a[]和char *a的区别
结构体中末尾定义一个char data[0];或者int data[0]
如何用O(1)的时间复杂度来删除一个单链表结点
不申请新的内存空间来交换两个变量的值
上亿万数量级的海量查询,比如十亿订单中,找出前一百个销量最好的产品
首先,利用哈希算法,将订单分为1000组(相同产品的订单要分入一个组)。
其次,用哈希map统计每个组里产品出现的频率(也就是销量),
堆排序构造出一个100个元素的小顶堆,存入文件,这样就有1000个文件存放小顶堆。
最后再将这1000个文件归并排序,找出频率最高的前一百个。
对于一个海量的文件中存储着不同的URL,用最小的时间复杂度去除重复的URL
将海量数据分组,比如分为1000个组,那就是hash(url)%1000,来分组,相同的url一定进了相同的组,然后用hash_map来统计频度,重复出现的就删除掉。
给定a、b两个文件,各存放50亿个ur,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
可以估计每个文件的大小为50G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 遍历文件a,对每个url算出对应的哈希值,再求取
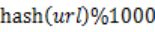 ,然后根据所取得的值将url分别存储到1000个小文件中。这样每个小文件的大约为300M。
,然后根据所取得的值将url分别存储到1000个小文件中。这样每个小文件的大约为300M。 - 遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为
 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件( )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
- 顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为
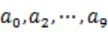 )中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。 - 找一台内存在2G左右的机器,依次对
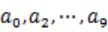 用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(
用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(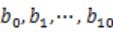 ,此处有误,更正为b0,b1,b2,b9)。
,此处有误,更正为b0,b1,b2,b9)。
对![]() 这10个文件进行归并排序(内排序与外排序相结合)。
这10个文件进行归并排序(内排序与外排序相结合)。
对于海量数据,用什么数据结构存储用户搜索的高频关键词比较合适?比如,当用户输入“黄”字,输入框要自动显 示“黄晓明”,“黄蓉”,“黄山”,“黄鹤楼”等提示,但是能存储的量很有限,所以需要选择恰当的数据结构。
这个需要进行存储,应该用字典树或者是状态机。
哈夫曼树
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的 路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数。< 如果两个数的和比接下来两个数都大,那就要并列生长 >
用#define声明一个常数,表明1年中有多少秒(忽略闰年问题)?
#define SECONDS (365*24*60*60)UL
考虑16位机将会溢出,所以要加UL。
c++关键字voatile
volatile int i=10;
volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i的地址中读取。
- 多线程下的volatile
当多个线程都要用到某一个变量且该变量的值会被改变时,可以用volatile声明,该关键字的作用是防止优化编译器把变量从内存装入CPU寄存器中,如果变量被装入寄存器,那么两个线程有可能一个使用内存中的变量,一个使用寄存器中的变量,这会造成程序的错误执行。volatile的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。这样有利于多线程安全。
C++中下列数据类型所占的字节数以及数值表示范围
char: 1个字节,范围是-128~127(-128代表的是-0)
0~127的补码是:00000000~01111111
-128~-1的补码是:10000000~11111111
BYTE是无符号的char型(1个字节),WORD是无符号short型(2个字节),DWORD是无符号long型(4个字节)。
WORD:0~65535
编译语言和解释语言
解释型语言:不需要编译,而是程序在运行时先翻译成中间代码,再由解释器对中间代码进行解释运行。
翻译成机器语言,每执行一次都要翻译一次。因此效率比较低,应用于一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序。
如Python/JavaScript / Perl /Shell等都是解释型语言。
编译型语言:程序在执行之前需要一个专门的编译过程,由编译器把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。
程序执行效率高,依赖编译器,跨平台性差些,如c/c++,由于程序执行速度快,因此像开发操作系统、大型应用程序、数据库系统等时都采用它。
对于java语言,就比较特殊,因为它既需要编译,又需要JVM(java虚拟机)来解释运行,跨平台性很好。
总结:
编译型语言,执行速度快、效率高;依靠编译器、跨平台性差些。
解释型语言,执行速度慢、效率低;依靠解释器、跨平台性好。
系统函数和库函数的比较
库函数很多时候就通过系统调用来实现的,比如fwrite库函数,就是通过write系统调用来实现的。
系统调用:
实际上是指底层的一个调用,就是内核提供的、功能十分强大的一系列的函数。这些系统调用是在内核空间中实现的。是操作系统为用户态运行的进程和硬件设备(如CPU、磁盘、打印机等)进行交互提供的一组接口,即就是设置在应用程序和硬件设备之间的一个接口层。可以说是操作系统留给用户程序的一个接口。
库函数:
顾名思义是把函数放到库里,是把一些常用到的函数编完放到一个文件里,供别人用。别人用的时候把所在的文件名用#include<>加到里面就可以了,一般放到lib文件里。库函数一般分为两类:一种是C语言标准规定的库函数,一类是编译器特定的库函数。libc就是一个C标准库,里面放着一些基本的函数,这些函数都被标准化了。
联系与区别:
1、库函数,把部分系统调用包装起来。比如库函数printf,就调用了putc()和write()等这样一些系统函数。系统调用是为了方便使用操作系统的接口,而库函数则是为了使编程方便。
2、库函数的调用是应用程序的一部分,而系统调用则是操作系统的一部分。
3、系统调用依赖于内核,不保证移植性;库函数调用平台移植性好。
4、系统调用在用户空间和内核上下文环境之间切换,开销大,库函数属于过程调用,开销较小。
如何判断一个整数是否是某个数的平方
- 暴力遍历法(从0~n/2遍历)
- 用二分法查找,数组相当于为0~n之间的数。
- 将一个数连续减去,1,3,5,7,9,11,13,...这是为差2的等差数列,因为这串数列的Sn和就刚好为n^2。只要数不为0就一直减,要是最后值为0,那就说明是平方,如果不为0,那就不是平方。
- 数的平方根取整再平方等不等于该数,
if(n == (int)sqrt(n)*(int)sqrt(n))或者
result = sqrt(a);
if(floor(result)==result);
C++异常处理机制
C++的异常处理机制有3部分组成:try(检查),throw(抛出),catch(捕获)。
throw要在try当中,基本格式如下。
如果throw了一个无法被捕获的异常,也就是catch无法捕获,这时候会调用默认的终止函数。catch是根据异常类型的不同来执行不同的catch分支。如果catch里面是...表示捕获所有类型的异常。

析构函数能不能抛出异常?为什么
不能。
- 从异常机制来看,抛出异常时,将暂停当前函数的执行,开始查找匹配的catch子句。一直查找,直到找到一个可以处理该异常的catch。这个过程称为栈展开。所以如果析构函数抛出异常,那么异常点之后的程序不会执行,如果释放资源的操作在抛出异常之后,那么这些资源不能及时释放就会导致内存泄露。
再有就是,异常发生时,本身就会调用析构函数来释放资源,此时若析构函数自身也抛出异常,前一个异常尚未处理,又有新的异常,就会造成程序崩溃。
C++中对象的生命周期
全局对象在main开始前被创建,main退出后被销毁。
静态对象在第一次进入作用域时被创建,在main退出后被销毁(若程序不进入其作用域,则不会被创建)。
局部对象在进入作用域时被创建,在退出作用域时被销毁。
函数指针、指针函数分别是什么?
函数指针就是指向函数的指针,与普通指针没什么区别,c在编译的时候,每个函数都有一个入口地址,函数指针就指向这个入口地址。有了函数指针之后,就可用这个指针调用函数,也可以作为函数的参数来使用。函数指针是如下调用函数的:

指针函数就是返回值是指针的函数。int *fun(int x,int y);
x&(-x)返回是是什么?比如若x = 2^31-4
把x化为二进制,从右到左第一个1所在的位置记为p,返回值就是2^p方。2^n-1二进制就是n个1。
所以若是x = 2^31-4,那么返回值该是4。2^31-1表示有31个1,-3,末尾便是100,p=2,所以返回值是4。
c++中的左值和右值
左值就是既能出现在等号左边也能出现在等号右边的变量,叫做左值。只能出现在等号右边的变量,叫做右值。像3 + 4, a + b就是右值表达式,左值才能进行赋值,右值不行。
左值引用不能绑定到右值,但是常量左值引用可以接收右值对它的初始化。
如:int &a = 2; # 左值引用绑定到右值,编译失败
const int &b =2; # 常量左值引用绑定到右值,编程通过
++i可以作为左值,i++不能作为左值,因为i++返回的是一个临时变量temp。

函数如果返回全局引用就可以作为左值。

二叉排序树查找一个数的时间复杂度
二叉排序树的查找次数取决于树的高度。
如果这个树比较平衡,那么查找的复杂度就是O(log2n),如果这个树很不平衡的话,那就接近于O(N)。
不用if,switch,三目运算符来输出较大的数或者较小的数?
- a+b+abs(b-a)/2就是较大数,a+b-abs(b-a)/2就是较小数。
- int pair[2] = {a,b};
return pair[a 使用sizeof,定义一个指针p,如果打印sizeof出来是2,说明是16位的,如果打印出来是4,说明是32位的。 char a[]定义了一个字符串数组,a不可改变,但是a指向的内容可以改变。 存取效率来说,char* a = “abcd”存在常量存储区,存取速度慢,char a[]在栈区,存取速度快。 柔性数组,主要用于使结构体包含可变长字段,它不占结构体中的大小,这样这个结构体就实现了可变长度。这样分配了比结构体多的内存大小之后,这个柔性数组就有了意义,多分配的内存就可以由柔性数组来操控。 将待删除结点的下一个结点的val值赋给这个待删结点,然后把->next->next赋给->next,这样就是O(1)的时间复杂度。 比如:a = 1,b = 2. b = a-b; a = a-b; 异或,a = a^b^b,b = a^b^a;用C++程序写代码来判断一个操作系统是16位还是32位的?
如何判断一段程序是C编译的还是C++编译的?

char a[]和char *a的区别
结构体中末尾定义一个char data[0];或者int data[0]
如何用O(1)的时间复杂度来删除一个单链表结点

不申请新的内存空间来交换两个变量的值