爬取大学排名和NBA球星数据并进行多维度可视化
opexcel 模块地址:https://blog.csdn.net/wei_zhen_dong/article/details/105318970
import requests
from lxml import etree
from opdata.opexcel import Operatingexcel
import pyecharts.options as opts
from pyecharts.charts import Radar
def use_requsert_dome():
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
response = requests.get(url,headers)
if response.status_code == 200:
# 编码解码
html = response.text.encode('iso-8859-1').decode('utf-8')
return html
else:
return None
def text_to_dic(text):
dict = {}
html = etree.HTML(text)
pags = html.xpath('/html/body/div[3]/div/div[2]/div/div[3]/div/table/tbody')
for i in pags:
id = i.xpath('//tr/td[1]/text()')
name = i.xpath('//tr/td[2]/div/text()')
province = i.xpath('//tr/td[3]/text()')
# 总分
score = i.xpath('//tr/td[4]/text()')
#生源质量
quality = i.xpath('//tr/td[5]/text()')
# 培养结果
employment = i.xpath('//tr/td[6]/text()')
# 科研规模
srs = i.xpath('//tr/td[7]/text()')
# 科研质量
fwci = i.xpath('//tr/td[8]/text()')
# 顶尖成果
topresults = i.xpath('//tr/td[9]/text()')
# 顶尖人才
elite = i.xpath('//tr/td[10]/text()')
# 经费
expenditure = i.xpath('//tr/td[11]/text()')
# 成果转化
at = i.xpath('//tr/td[12]/text()')
dict["id"]=id
dict["name"] = name
dict["province"] = province
dict["score"] = score
dict["quality"] = quality
dict["employment"] = employment
dict["srs"] = srs
dict["fwci"] = fwci
dict["topresults"] = topresults
dict["elite"] = elite
dict["expenditure"] = expenditure
dict["at"] = at
return dict
def draw(arr,value,valuemax,name):
radar=Radar(init_opts=opts.InitOpts(width="1280px", height="720px", bg_color="#CCCCCC"))
v_max=[list(z)for z in zip(arr,valuemax)]
radar.add_schema(
schema=[
opts.RadarIndicatorItem(name=k, max_=v)for k,v in v_max
],
splitarea_opt=opts.SplitAreaOpts(
is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=1)
),
textstyle_opts=opts.TextStyleOpts(color="#fff"),
)
radar.add(
series_name=name,
data=value,
linestyle_opts=opts.LineStyleOpts(color="#CD0000"),
)
radar.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
radar.set_global_opts(
title_opts=opts.TitleOpts(title=name), legend_opts=opts.LegendOpts()
)
radar.render("{0}.html".format(name))
if __name__ == '__main__':
text = use_requsert_dome()
if text != None:
dict = text_to_dic(text)
arr = ["总分", "生源质量", "科研规模", " 科研质量", "顶尖成果", "经费", "成果转化"]
valuemax = [100, 100,40000, 1.5,1200,1200000,1200]
ol = Operatingexcel()
ol.set_excel_dic(dict,"data\csdn_data.xlsx",0,0)
dics = ol.get_excel_dic("data\csdn_data.xlsx","大学排名")
for i in range(int(dics["id"][-1])):
name = dics["name"][i]
score = dics["score"][i]
quality = dics["quality"][i]
srs = dics["srs"][i]
fwci = dics["fwci"][i]
topresults = dics["topresults"][i]
expenditure = dics["expenditure"][i]
at = dics["at"][i]
value = [[score, quality, srs, fwci, topresults,expenditure,at]]
draw(arr, value, valuemax, name)
数据为2016年的又点老旧,不过也就是为了练习
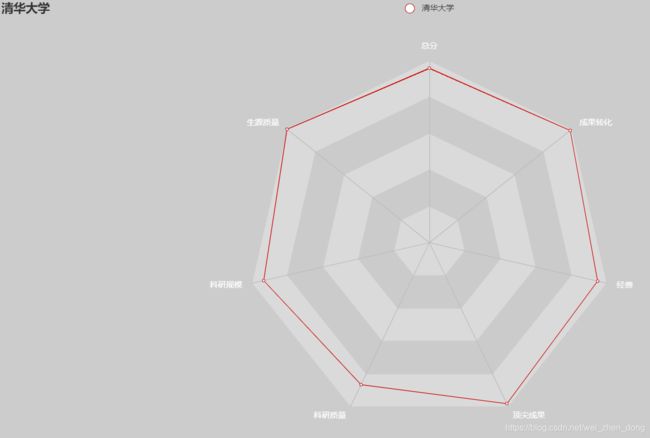
清华大学:
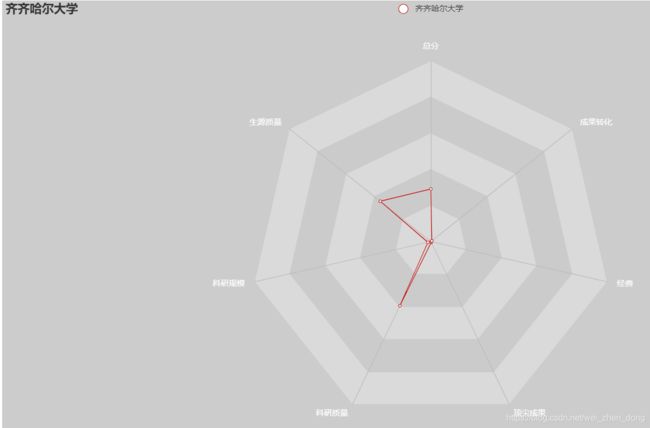
齐齐哈尔大学:
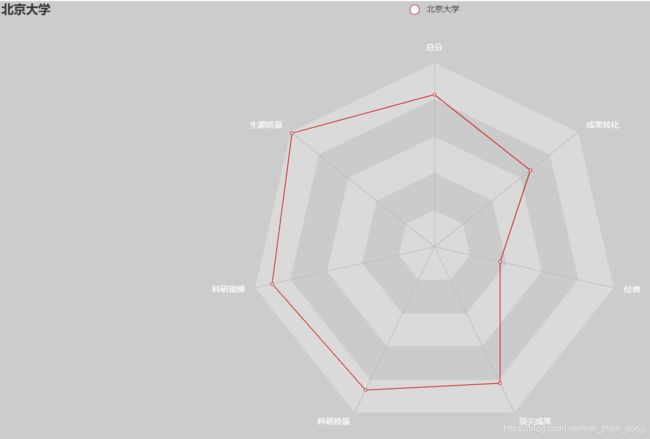
北京大学:
这里放一个NBA球星数据,有兴趣的也可以做一个球星的能力纬度分析
爬取虎扑体育NBA球星数据:
import requests
from lxml import etree
from opdata.opexcel import Operatingexcel
# 小例子,获取虎扑体育NBA球星数据
def use_requsert_dome():
url = 'https://nba.hupu.com/stats/players'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
response = requests.get(url,headers)
if response.status_code == 200:
return response.text
else:
return None
def text_to_dic(text):
dict = {}
html = etree.HTML(text)
pags = html.xpath('//*[@id="data_js"]/div[4]/div/table/tbody')
for i in pags:
name = i.xpath('//tr/td[2]/a/text()')
team = i.xpath('//tr/td[3]/a/text()')
score = i.xpath('//tr/td[4]/text()')
hit_shoot = i.xpath('//tr/td[5]/text()')
hit_rate = i.xpath('//tr/td[6]/text()')
hit_rate_3 = i.xpath('//tr/td[8]/text()')
hit_rate_f = i.xpath('//tr/td[10]/text()')
session = i.xpath('//tr/td[11]/text()')
time = i.xpath('//tr/td[12]/text()')
dict["name"]=name
dict["team"] = team
dict["score"] = score[1:]
dict["hit_shoot"] = hit_shoot[1:]
dict["hit_rate"] = hit_rate[1:]
dict["hit_rate_3"] = hit_rate_3[1:]
dict["hit_rate_f"] = hit_rate_f[1:]
dict["session"] = session[1:]
dict["time"] = time[1:]
return dict
if __name__ == '__main__':
text = use_requsert_dome()
if text != None:
dict = text_to_dic(text)
ol = Operatingexcel()
ol.set_excel_dic(dict,"data\csdn_data.xlsx",0,0)
因为比较简单,所以没有太多注释,如果有疑问也可以参考我之前的博客。
由于我的水平有限,文章中难免有不妥和错误之处,真诚的希望路过的大佬,能在评论区批评指正。