分分钟爬取51job
爬取前程无忧(一)
- 步骤:
- 1.解析url
- 2.获取url上的内容
- 3.对获取的内容进行解析
- 4.对解析后的内容进行存储
步骤:
1.解析url
首先,明确我们的目的:爬取51上所有的python岗位的相关职位信息
这是我们的原始url:
https://search.51job.com/list/010000,000000,0000,00,9,99,python,2,3.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
当然我们的有效url仅有:
https://search.51job.com/list/010000,000000,0000,00,9,99,python,2,3.html
根据我们的观察一共有六页
我们打开第二页,第三页对比一下
第一页:https://search.51job.com/list/010000,000000,0000,00,9,99,python,2,1.html
第二页:https://search.51job.com/list/010000,000000,0000,00,9,99,python,2,2.html
第三页:https://search.51job.com/list/010000,000000,0000,00,9,99,python,2,3.html
ok,我们可以很明显的发现规律,
url中python和页码,没错这就是我们需要处理的第一个点
首先将我们的URL进行一个完整的表述,我们可以这样做:
在这里我们的key可以采取从屏幕上进行获取
key = input('请输入想查询的职业/岗位:' )
for i in range(6):
url = 'https://search.51job.com/list/010000,000000,0000,00,9,99,' + str(key) + ',2,' + str(i+1) + '.html'
这里我们可以输出看一下我们的url

ok,我们的url就这样处理好了
2.获取url上的内容
我们已经获取了所有的网页地址,接下来我们使用requests库的get请求来获取网页上的内容,同时给我们的爬虫加上一点小小的伪装,
首先要导入库
import requests
然后使用requests库的get请求来得到我们的网页源码,
response = requests.get(url=url,headers=headers)
response里面就包含了我们需要的内容,我们可以查看其内容
print(response.status_code) # 打印状态码,状态码200表示ok
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) # 以文本形式打印网页源码
print(response.content) # 以字节流形式打印
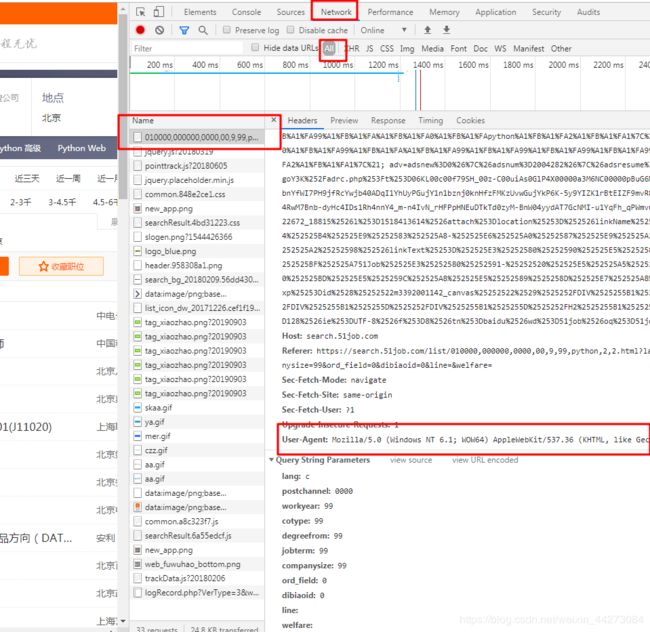
headers则是请求头,是区分浏览器和程序的必要元素,
更多的请求头信息可以查看大佬:https://blog.csdn.net/gklcsdn/article/details/101522169
如何查看我们的请求头呢,我们用Google浏览器打开我们的网页,按下F12进行元素检查,然后你就可以看到一串前端代码,
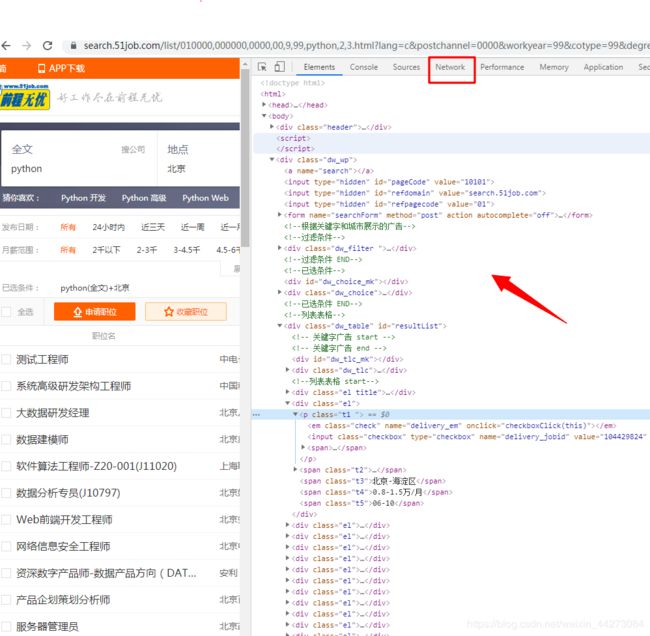
我们找到network,点进去,然后刷新我们的页面,点开文件,这里就可以看到很多的信息了,
然后我们找到我们需要的进行添加,
3.对获取的内容进行解析
这里我们使用xpath模块来进行解析
response.encoding = 'gbk'
tree = etree.HTML(response.text) ## 解析HTML文档,返回根节点对象
divs = tree.xpath('//div[@class = "dw_table"]/div[@class = "el"]')
tree.xpath:在源码中找出我们所需要的信息(直接找我们需要的即可,注意)
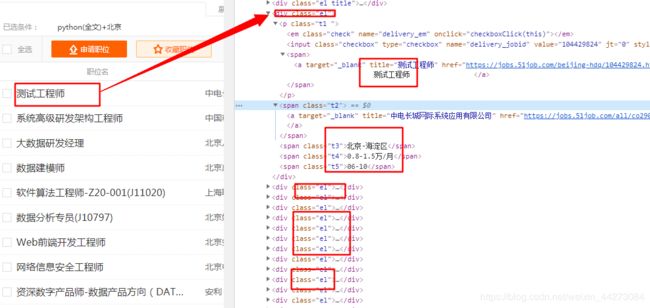
来一个for循环,将我们得到的每一个值都进行保存。
gszw = div.xpath('.//p//a/@title')[0]
gsmc = div.xpath('.//span[@class = "t2"]/a/@title')[0]
gzdd = div.xpath('.//span[@class = "t3"]/text()')[0]
gzxc = div.xpath('.//span[@class = "t4"]/text()')[0]
fbsj = div.xpath('.//span[@class = "t5"]/text()')[0]
至此,我们就已经得到了全部的数据
4.对解析后的内容进行存储
我们获取数据自然是为了将数据进行保存,而后进行分析,这里简单的将数据保存为json文件和csv文件
完整代码:
import requests
from lxml import etree
import json,csv,time
if __name__ == '__main__':
key = input('请输入想查询的职业/岗位:' )
for i in range(6):
url = 'https://search.51job.com/list/010000,000000,0000,00,9,99,' + str(key) + ',2,' + str(i+1) + '.html'
time.sleep(1)
data = []
fp = open('./51job_python.json',mode='a',encoding='utf-8')
fp2 = open('./51job2_python.csv',mode='a',encoding='utf-8')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
response = requests.get(url=url,headers=headers)
response.encoding = 'gbk'
tree = etree.HTML(response.text)
divs = tree.xpath('//div[@class = "dw_table"]/div[@class = "el"]')
try:
for div in divs:
gszw = div.xpath('.//p//a/@title')[0]
gsmc = div.xpath('.//span[@class = "t2"]/a/@title')[0]
gzdd = div.xpath('.//span[@class = "t3"]/text()')[0]
gzxc = div.xpath('.//span[@class = "t4"]/text()')[0]
fbsj = div.xpath('.//span[@class = "t5"]/text()')[0]
d = dict()
d['职位'] = gszw
d['公司'] = gsmc
d['地区'] = gzdd
d['薪酬'] = gzxc
d['时间'] = fbsj
data.append(d)
if gzxc == None:
gzxc = 'mianyi'
print("一条信息获取成功")
reslit = json.dumps(data,ensure_ascii = False)
fp.write(reslit)
fp2.write('\n\n职位:%s。\n公司:%s。\n地区:%s。\n薪酬:%s。\n时间:%s'%(gszw,gsmc,gzdd,gzxc,fbsj))
except Exception as e:
fp2.write('\n\n职位:%s。\n公司:%s。\n地区:%s。\n薪酬:%s。\n时间:%s' % (gszw, gsmc, gzdd, '面议', fbsj))
fp.close()
fp2.close()
至于为什么是前程无忧,而不是Boss和智联
51job:爬取没有限制
boss直聘:需要设置IP,重点设置动态IP
智联:动态抓取,重点获取数据接口
嗯,任重道远。