TensorFlow、MXNet、Keras如何取舍? 常用深度学习框架对比
作者简介
魏秀参,旷视科技 Face++ 南京研究院负责人。南京大学 LAMDA 研究所博士,主要研究领域为计算机视觉和机器学习。在相关领域顶级国际期刊如 IEEE TIP、IEEE TNNLS、Machine Learning Journal 等和顶级国际会议如 ICCV、IJCAI、ICDM 等发表论文十余篇,并两次获得国际计算机视觉相关竞赛冠亚军。著有《解析深度学习——卷积神经网络原理与视觉实践》一书。曾获 CVPR 2017 最佳审稿人、南京大学博士生校长特别奖学金等荣誉,担任 ICCV、CVPR、ECCV、NIPS、IJCAI、AAAI 等国际会议 PC member。(个人自媒体:知乎“魏秀参”,新浪微博“Wilson_NJUer”)。
14 深度学习开源工具简介
自 2006 年 Hinton 和 Salakhutdinov 在 Science 上发表的深度学习论文点燃了最近一次神经网络复兴的“星星之火”,接着, 2012 年 Alex-Net 在 ImageNet 上夺冠又迅速促成了深度学习在人工智能领域的“燎原之势”。当下深度学习算法可谓主宰了计算机视觉、自然语言学习等众多人工智能应用领域。 与此同时,与学术研究一起快速发展并驾齐驱的还有层出不穷的诸多深度学习 开源开发框架。本章将向读者介绍和对比 9 个目前使用较多的深度学习开源框架,供大家根据自身情况“择优纳之”。
14.1 常用框架对比
表 14.2 中从“开发语言”、“支持平台”、“支持接口”、是否支持“自动求导”、 是否提供“预训练模型”、是否支持“单机多卡并行”运算等 10 个方面,对包 含 Caffe、 MatConvNet、 TensorFlow、 Theano 和 Torch 在内的 9 个目前最常用的深度学习开源框架进行了对比。

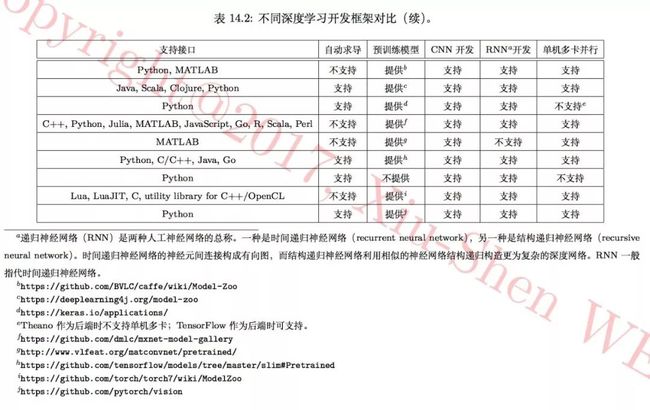
14.2 常用框架的各自特点
14.2.1 Caffe
Caffe 是一个广为人知、广泛应用侧重计算机视觉方面的深度学习库,由加州大学伯克利分校 BVLC 组开发,总结来说, Caffe 有以下优缺点:
✓ 适合前馈网络和图像处理; ✓ 适合微调已有的网络模型; ✓ 训练已有网络模型无需编写任何代码; ✓ 提供方便的 Python 和 MATLAB 接口;
✗ 可单机多卡,但不支持多机多卡; ✗ 需要用 C++/CUDA 编写新的 GPU 层; ✗ 不适合循环网络; ✗ 用于大型网络(如, GoogLeNet、 ResNet )时过于繁琐; ✗ 扩展性稍差,代码有些不够精简; ✗ 不提供商业支持; ✗ 框架更新缓慢,可能之后不再更新。
14.2.2 Deeplearning4j
Deeplearning4j 简称 DL4J,是基于JVM、聚焦行业应用且提供商业支持的分布式深度学习框架,其宗旨是在合理的时间内解决各类涉及大量数据的问题。 它与 Hadoop 和 Spark 集成,可使用任意数量的 GPU 或 CPU 运行。 DL4J 是一种适用于各类平台的便携式学习库。开发语言为 Java,可通过调整 JVM 的堆空间、垃圾回收算法、内存管理以及 DL4J 的 ETL 数据加工管道来优化 DL4J 的性能。其优缺点为:
✓ 适用于分布式集群,可高效处理海量数据; ✓ 在多种芯片上的运行已经被优化; ✓ 可跨平台运行,有多种语言接口; ✓ 支持单机多卡和多机多卡; ✓ 支持自动求导,方便编写新的网络层; ✓ 提供商业支持;
✗ 提供的预训练模型有限; ✗ 框架速度不够快。
14.2.3 Keras
Keras 由谷歌软件工程师 Francois Chollet 开发,是一个基于 Theano 和 TensorFlow 的深度学习库,具有一个受 Torch 启发、较为直观的 API。其优缺点如下: ✓ 受 Torch 启发的直观; ✓ 可使用 Theano、TensorFlow 和 Deeplearning4j 后端; ✓ 支持自动求导; ✓ 框架更新速度快。
14.2.4 MXNet
MXNet 是一个提供多种 API 的机器学习框架,主要面向 R、Python 和 Julia 等语言,目前已被亚马逊云服务采用。其优缺点为: ✓ 可跨平台使用; ✓ 支持多种语言接口;
✗ 不支持自动求导。
14.2.5 MatConvNet
MatConvNet 由英国牛津大学著名计算机视觉和机器学习研究组 VGG 负责开发,是主要基于 MATLAB 的深度学习工具包。其优缺点为: ✓ 基于 MATLAB,便于进行图像处理和深度特征后处理; ✓ 提供了丰富的预训练模型; ✓ 提供了充足的文档及教程;
✗ 不支持自动求导; ✗ 跨平台能力差。
14.2.6 TensorFlow
TensorFlow 是 Google 负责开发的用 Python API 编写,通过 C/C++ 引擎加速的深度学习框架,是目前受关注最多的深度学习框架。它使用数据流图集成 深度学习中最常见的单元,并支持许多最新的 CNN 网络结构以及不同设置的 RNN。其优缺点为: ✓ 具备不局限于深度学习的多种用途,还有支持强化学习和其他算法的工具; ✓ 跨平台运行能力强; ✓ 支持自动求导;
✗ 运行明显比其他框架慢; ✗ 不提供商业支持。
14.2.7 Theano
Theano 是深度学习框架中的元老,用 Python 编写,可与其他学习库配合使用,非常适合学术研究中的模型开发。现在已有大量基于 Theano 的开源深度学习库,包括 Keras、Lasagne 和 Blocks。这些学习库试着在 Theano 有时不够直观的接口之上添加一层便于使用的 API。关于 Theano,有如下特点: ✓ 支持 Python 和 Numpy; ✓ 支持自动求导; ✓ RNN 与计算图匹配良好; ✓ 高级的包装(Keras、Lasagne)可减少使用时的麻烦;
✗ 编译困难,错误信息可能没有帮助; ✗ 运行模型前需编译计算图,大型模型的编译时间较长; ✗ 仅支持单机单卡; ✗ 对预训练模型的支持不够完善。
14.2.8 Torch
Torch 是用 Lua 编写带 API 的科学计算框架,支持机器学习算法。Facebook 和 Twitter 等大型科技公司使用 Torch 的某些版本,由内部团队专门负责定制自己的深度学习平台。其优缺点如下: ✓ 大量模块化组件,容易组合; ✓ 易编写新的网络层; ✓ 支持丰富的预训练模型; ✓ PyTorch 为 Torch 提供了更便利的接口;
✗ 使用 Lua 语言需要学习成本; ✗ 文档质量参差不齐; ✗ 一般需要自己编写训练代码(即插即用相对较少)。
本文节选自电子工业出版社博文视点《解析深度学习——卷积神经网络原理与视觉实践》第14章,由作者本人和电子工业出版社博文视点授权。由于篇幅考虑,通过文后二维码访问各大网上商城购买。
本次活动我们采取文章留言送书的活动。在下周末之前,留言点赞数最高的前 3 名我们将免费赠送本书!图书由电子工业出版社博文视点提供。
《解析深度学习》全书内容概览






参考阅读:
老师木:有了Tensorflow,为什么我们还需要另外一个深度学习平台框架 | GIAC 访谈
格灵深瞳CTO邓亚峰:AI学习的三种路线
科大讯飞两代AI平台演进之路--讯飞云计算研究院副院长龙明康访谈
借助AI实现“学渣”到“学霸”逆袭,深度学习在学霸君的实践
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号