第一篇:爬虫初体验
网络爬虫
理论学习都是枯燥的,我们学习了初步的网络编程后,再来了解一下爬虫吧,网络爬虫可以极大增强趣味性。
什么是网络爬虫?
网络爬虫又称为网络机器人,按照我个人的理解,网络爬虫就是通过编程手段,实现自动化访问网页,提取网页中我们感兴趣的信息的一种程序。
为什么用Python写爬虫?
- 足够简单。Python作为一种脚本语言,语法简洁;
- 由于网站的网页可能会定期的更新发生结构性的变化,因此爬虫程序需要经常修改,Python灵活的语法能充分发挥优势;
- Python爬虫相关库强大又使用简洁。
编写爬虫的基本步骤
- 明确目标
- 抓包分析(提取URL)
- 数据提取
- 数据持久化
- 数据分析
一些概念
什么是
URI、URL、URN?
URI(Uniform Resource Identifier) 统一资源标识符URL(Uniform Resource Location) 统一资源定位符URN(Uniform Resource Name) 统一资源名称
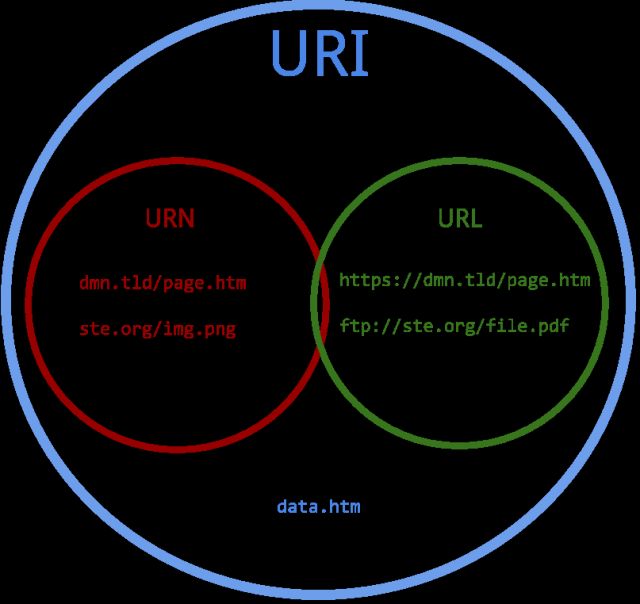
它们之间的关系如上图,大家主要关注的是URL,简单理解,URL就是网址。
第一个爬虫案例
爬虫需要实际演练,现在就让我们从一个最简单案例开始,我们爬一个妹子图网站,实现的功能就是使用Python代码全自动下载美女图片。
由于爬虫的实践性比较强,文末附本章录屏,请大家多多支持。
首先按照上述爬虫的编写步骤开始
1. 明确目标
https://www.mzitu.com 就是我们选取的目标网站
2. 抓包分析
网络抓包有一些专业的工具,但对于我们网页爬虫来说,Chrome谷歌浏览器已经足够用了。
打开谷歌浏览器,按F12打开开发者模式,然后使用谷歌浏览器打开目标网站,选择Network选项卡
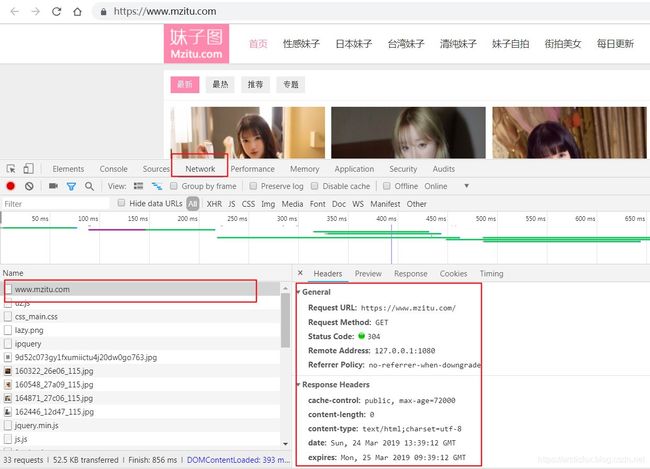
思路:
我们要使用Python脚本下载图片,首先要做的就是得到这些图片的URL链接,也就是网址,得到了图片网址后下载图片就是小意思了。
而我们使用谷歌浏览器开发者模式的目的,主要是两个
- 分析请求头,使用Python代码获取当前的网页的HTML源码
- 分析网页结构,寻找获取当前网页中图片地址的规律
先来实现第一个目标,获取网页源码
分析请求头
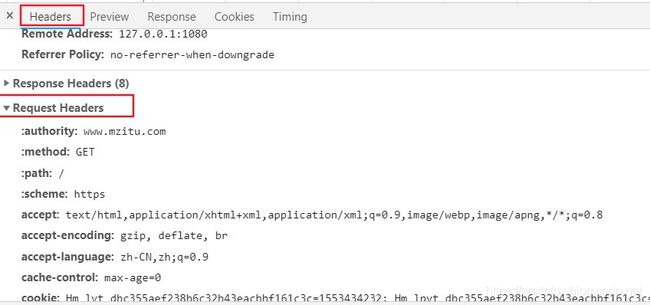
什么是请求头?
看到浏览器开发者模式的右边窗口,Request Headers下就是请求头的数据,它表示浏览器访问网站服务器时,携带的一些数据。我们爬虫的原理就是要伪装成浏览器去访问服务器,因此需要分析请求头,查看浏览器携带了什么特殊数据没有,浏览器携带了这些数据,我们爬虫也必须携带,否则不就露馅了吗,网站服务器很容易就发现我们不是浏览器在访问,它会拒绝为我们服务。
通常请求头中的user-agent字段是我们必须要关注的,它是表示当前浏览器内核信息的字段,简单说就是我们的浏览器是什么牌子的。关于请求头、字段这些都是HTTP协议中的内容,这里不深入讲解,要学会爬虫,必须学好HTTP协议,否则一切都是空中楼阁,这里推荐《图解HTTP》这本书,有趣又简单,在本公众号交流群中已上传该书电子版。
我们今天要做的案例,没有什么难度,请求头信息也没有什么特别之处,请求头的分析到此为止。
为了学习简单,我们先安装两个python中的爬虫神器———requests库和bs4库
打开命令行,输入以下指令安装
python -m pip install requests
python -m pip install Beautifulsoup4
编写以下代码
import requests
BASE_URL = "https://www.mzitu.com"
# 将之前分析得到的User-Agent信息复制出来,组装成一个如下字典
HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0',
"Referer": "https://www.mzitu.com"}
resp = requests.get(BASE_URL, headers=HEADERS)
print(resp.text)
运行代码,成功输出网页HTML源代码,则表示我们成功实现第一个目标,获取网页源码。
分析网页结构
鼠标右键选择网页中的一张图片,弹出菜单中选择【检查】
可以发现规律,所有图片都是HTML中的img标签,而图片的地址则是该标签中的data-original属性的值,换句话说,只要获取网页中的所有包含data-original属性的img标签,就能获取图片地址。
要完成这个目标,就涉及到解析HTML源码,而我们刚刚安装的Beautifulsoup4库就是用来解析HTML源码的。
3.数据提取
import requests
# 导入BeautifulSoup
from bs4 import BeautifulSoup
# 目标网址
BASE_URL = "https://www.mzitu.com"
# 将之前分析得到的User-Agent信息复制出来,组装成一个如下字典
HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0',
"Referer": "https://www.mzitu.com"}
resp = requests.get(BASE_URL, headers=HEADERS)
# 创建BeautifulSoup对象,第一个参数传入网页源码,第二个指定解析器名字
bs = BeautifulSoup(resp.text, "html.parser")
# 提取网页中所有的包含data-original属性的img标签
for src in bs.select("img[data-original]"):
# 获取每个img标签的data-original属性值,这个值就是图片地址
print(src.attrs.get("data-original"))
运行以上代码,成功获取当前网页的所有图片地址
下载图片
由于我们只是一个简单爬虫,就不需要数据持久化和数据分析了,下面说一说得到了图片地址,如何自动下载图片
下载实际上也是一种数据访问,仍然使用requests库就可以了
# 定义一个下载函数,参数就是图片的地址
def download(url):
resp = requests.get(url, headers=HEADERS)
# 文件操作第一个参数是文件名,第二个参数是模式,这里wb是二进制写模式
with open(url.split("/")[-1], "wb") as file:
# 我们下载网页时使用resp.text,因为网页源码是字符串
# 图片则是二进制数据,所有使用resp.content,将该数据写入一个二进制文件即可
file.write(resp.content)
完整代码如下:
import requests
# 导入BeautifulSoup
from bs4 import BeautifulSoup
# 目标网址
BASE_URL = "https://www.mzitu.com"
# 将之前分析得到的User-Agent信息复制出来,组装成一个如下字典
HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0',
"Referer": "https://www.mzitu.com"}
# 定义一个下载函数,参数就是图片的地址
def download(url):
resp = requests.get(url, headers=HEADERS)
# 文件操作第一个参数是文件名,第二个参数是模式,这里wb是二进制写模式
with open(url.split("/")[-1], "wb") as file:
# 我们下载网页时使用resp.text,因为网页源码是字符串
# 图片则是二进制数据,所有使用resp.content,将该数据写入一个二进制文件即可
file.write(resp.content)
resp = requests.get(BASE_URL, headers=HEADERS)
# 创建BeautifulSoup对象,第一个参数传入网页源码,第二个指定解析器名字
bs = BeautifulSoup(resp.text, "html.parser")
# 提取网页中所有的包含data-original属性的img标签
for src in bs.select("img[data-original]"):
# 获取每个img标签的data-original属性值,这个值就是图片地址
pic_url = src.attrs.get("data-original")
print(pic_url)
download(pic_url)
运行代码,即可在脚本的当前目录下载妹子图。大家可能发现,该脚本只能下载当前网页第一页的图片,不能自动翻页下,关于翻页下载,见视频内容,是可以轻松做到想下几页就下几页。
视频地址:
链接:https://pan.baidu.com/s/1zZd1B3flM7zGjuiRGdDbFg
提取码:qzyq
最终代码
import requests
# 导入BeautifulSoup
from bs4 import BeautifulSoup
# 目标网址
BASE_URL = "https://www.mzitu.com/page/%d/"
# 将之前分析得到的User-Agent信息复制出来,组装成一个如下字典
HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0',
"Referer": "https://www.mzitu.com"}
# 定义一个下载函数,参数就是图片的地址
def download(url):
resp = requests.get(url, headers=HEADERS)
# 文件操作第一个参数是文件名,第二个参数是模式,这里wb是二进制写模式
with open(url.split("/")[-1], "wb") as file:
# 我们下载网页时使用resp.text,因为网页源码是字符串
# 图片则是二进制数据,所有使用resp.content,将该数据写入一个二进制文件即可
file.write(resp.content)
# 提取每张妹子图的URL
def get_img_url(url):
resp = requests.get(url, headers=HEADERS)
img_src = []
if resp.status_code == 200:
bs = BeautifulSoup(resp.text, "lxml")
for src in bs.select("img[data-original]"):
img_src.append(src.attrs.get("data-original"))
else:
print(resp.status_code)
return img_src
# 生成网页每一页的URL,并开始爬取,参数为指定爬取多少页
def start(page):
for i in range(1, page+1):
url = BASE_URL % (i)
imgs = get_img_url(url)
for pic_url in imgs:
download(pic_url)
start(3)
关注我的公众号:编程之路从0到1
