集成学习voting Classifier在sklearn中的实现(投票机制)
文章目录
- Voting即投票机制
- 1)使用方式
- 2)思想
- Hard Voting
- Soft Voting
- Hard Voting 投票方式的弊端:
- 硬投票代码
- 软投票代码
机器学习的算法有很多,对于每一种机器学习算法,考虑问题的方式都略微有所不同,所以对于同一个问题,不同的算法可能会给出不同的结果,那么在这种情况下,我们选择哪个算法的结果作为最终结果呢?那么此时,我们完全可以把多种算法集中起来,让不同算法对同一种问题都进行预测,最终少数服从多数,这就是集成学习的思路。
接下来我们就来看看怎样用sklearn实现我们集成学习中的voting classifier
Voting即投票机制
Voting即投票机制,分为软投票和硬投票两种,其原理采用少数服从多数的思想。
1)使用方式
voting = ‘hard’:表示最终决策方式为 Hard Voting Classifier;
voting = ‘soft’:表示最终决策方式为 Soft Voting Classifier;
2)思想
Hard Voting Classifier:根据少数服从多数来定最终结果;
Soft Voting Classifier:将所有模型预测样本为某一类别的概率的平均值作为标准,概率最高的对应的类型为最终的预测结果;
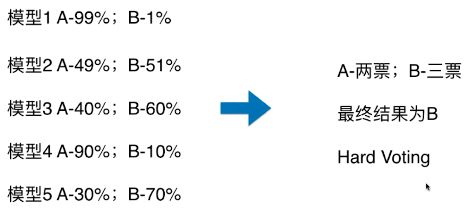
Hard Voting
模型 1:A - 99%、B - 1%,表示模型 1 认为该样本是 A 类型的概率为 99%,为 B 类型的概率为 1%;
Soft Voting
将所有模型预测样本为某一类别的概率的平均值作为标准;

Hard Voting 投票方式的弊端:
如上图,最终的分类结果不是由概率值更大的模型 1 和模型 4 决定,而是由概率值相对较低的模型 2/3/5 来决定的;
硬投票代码
'''
硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类。
'''
iris = datasets.load_iris()
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
clf1 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=3, min_child_weight=2, subsample=0.7,
colsample_bytree=0.6, objective='binary:logistic')
clf2 = RandomForestClassifier(n_estimators=50, max_depth=1, min_samples_split=4,
min_samples_leaf=63,oob_score=True)
clf3 = SVC(C=0.1)
# 硬投票
eclf = VotingClassifier(estimators=[('xgb', clf1), ('rf', clf2), ('svc', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['XGBBoosting', 'Random Forest', 'SVM', 'Ensemble']):
scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
Accuracy: 0.97 (+/- 0.02) [XGBBoosting]
Accuracy: 0.33 (+/- 0.00) [Random Forest]
Accuracy: 0.95 (+/- 0.03) [SVM]
Accuracy: 0.94 (+/- 0.04) [Ensemble]
软投票代码
'''
软投票:和硬投票原理相同,增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度。
'''
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
clf1 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=3, min_child_weight=2, subsample=0.8,
colsample_bytree=0.8, objective='binary:logistic')
clf2 = RandomForestClassifier(n_estimators=50, max_depth=1, min_samples_split=4,
min_samples_leaf=63,oob_score=True)
clf3 = SVC(C=0.1, probability=True)
# 软投票
eclf = VotingClassifier(estimators=[('xgb', clf1), ('rf', clf2), ('svc', clf3)], voting='soft', weights=[2, 1, 1])
clf1.fit(x_train, y_train)
for clf, label in zip([clf1, clf2, clf3, eclf], ['XGBBoosting', 'Random Forest', 'SVM', 'Ensemble']):
scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
Accuracy: 0.96 (+/- 0.02) [XGBBoosting]
Accuracy: 0.33 (+/- 0.00) [Random Forest]
Accuracy: 0.95 (+/- 0.03) [SVM]
Accuracy: 0.96 (+/- 0.02) [Ensemble]
个人微信公众号,专注于学习资源、笔记分享,欢迎关注。我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活,,如果觉得有点用的话,请不要吝啬你手中点赞的权力,谢谢我亲爱的读者朋友。

One day, in retrospect, the years of struggle will strike you as the most beautiful.
当你某天再回首时,你会发现那些奋斗的日子最美好。
2020年3月30日于重庆城口
好好学习,天天向上,终有所获