待持续更新...
selenium 刷新 前进 后退
java-刷新
1.driver.navigate().refresh();
2.driver.get(driver.getCurrentUrl());
3.driver.navigate().to(driver.getCurrentUrl());
4.driver.findElement(By.id("Contact-us")).sendKeys(Keys.F5);
5.driver.executeScript("history.go(0)");
python-刷新
driver.refresh()
driver.execute_script("location.reload()")
后退
driver.back()
前进
driver.forward()
Selenium2+python自动化45-18种定位方法(find_elements) https://www.cnblogs.com/yoyoketang/p/6557421.html
一、十八种定位方法
前八种是大家都熟悉的,经常会用到的
1.id定位:find_element_by_id(self, id_)
2.name定位:find_element_by_name(self, name)
3.class定位:find_element_by_class_name(self, name)
4.tag定位:find_element_by_tag_name(self, name)
5.link定位:find_element_by_link_text(self, link_text)
6.partial_link定位find_element_by_partial_link_text(self, link_text)
7.xpath定位:find_element_by_xpath(self, xpath)
8.css定位:find_element_by_css_selector(self, css_selector)
这八种是复数形式
9.id复数定位find_elements_by_id(self, id_)
10.name复数定位find_elements_by_name(self, name)
11.class复数定位find_elements_by_class_name(self, name)
12.tag复数定位find_elements_by_tag_name(self, name)
13.link复数定位find_elements_by_link_text(self, text)
14.partial_link复数定位find_elements_by_partial_link_text(self, link_text)
15.xpath复数定位find_elements_by_xpath(self, xpath)
16.css复数定位find_elements_by_css_selector(self, css_selector)
这两种就是快失传了的
find_element(self, by='id', value=None)
find_elements(self, by='id', value=None)
二、element和elements傻傻分不清
1.element方法定位到是是单数,是直接定位到元素
2.elements方法是复数,这个学过英文的都知道,定位到的是一组元素,返回的是list队列
3.可以用type()函数查看数据类型
4.打印这个返回的内容看看有什么不一样
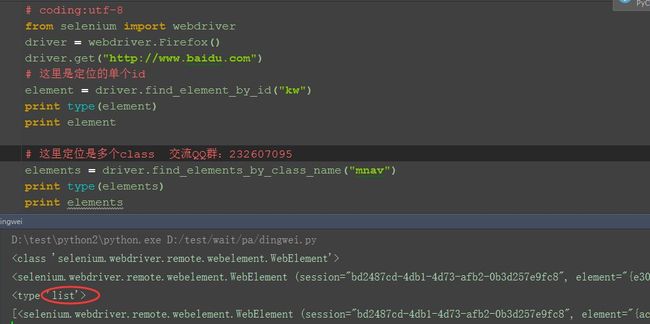
三、elements定位方法
1.前面一篇已经讲过find_element()的用法,看这里:
2.这里重点介绍下用elements方法如何定位元素,当一个页面上有多个属性相同的元素时,然后父元素的属性也比较模糊,不太好定位。
这个时候不用怕,换个思维,别老想着一次定位到,可以先把相同属性的元素找出来,取对应的第几个就可以了。
3.如下图,百度页面上有六个class一样的元素,我要定位“地图”这个元素

4.取对应下标即可定位了
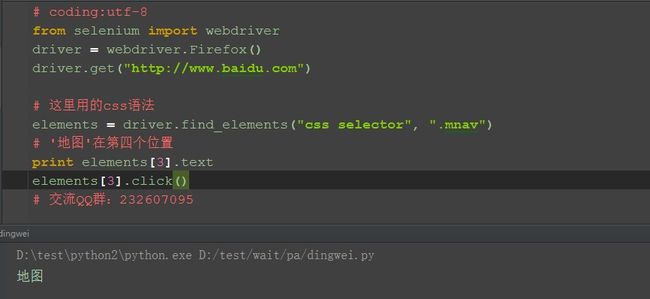
四、参考代码
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 这里是定位的单个id
element = driver.find_element_by_id("kw")
print type(element)
print element
# 这里定位是多个class
elements = driver.find_elements_by_class_name("mnav")
print type(elements)
print elements
# 这里用的css语法
s = driver.find_elements("css selector", ".mnav")
# '地图'在第四个位置
print s[3].text
s[3].click()
# 这个写法也是可以的
# driver.find_elements("css selector", ".mnav")[3].click()
selenium 层级定位
#在实际测试过程中,一个页面可能有多个属性基本相同的元素,如果要定位到其中的一个,这时候需要用到层级定位。先定位到父元素,然后再通过父元素定位子孙元素
# 用于多层frame的不方便定位或者frame通过id或者name定位不到的,可以用层级定位获取到frame元素,在获取到frame里的元素 PS:frameset不用切,frame需层层切
driver = webdriver.Firefox()
#checkbox.html 要和脚本文件放一个目录下,否则需要指定checkbox.html的路径
file_path = 'file:///'+os.path.abspath('level_locate.html')
driver.get(file_path)
#首先定位到Link1链接(弹出下拉列表)
driver.find_element_by_id('xx').click()
#在父元素下找到link为Action的子元素
sub_element = driver.find_element_by_id('xx').find_element_by_link_text('Another_action')
#将鼠标移动到子元素上
ActionChains(driver).move_to_element(sub_element).perform()
time.sleep()
eg2:
#先定位到父级元素searchBoxUl
searchboxUI = dr.find_element_by_id("searchBoxUl")
#再定位子元素
boxuis = searchboxUl.find_elements_by_tag_name("li")
#定位到旅游
boxuis[3].click()
python selenium 定位iframe(多层框架) https://blog.csdn.net/xm_csdn/article/details/53419133
在 web 应用中经常会出现 iframe 嵌套的应用,假设页面上有 A、B 两个 iframe,其中 B 在 A 内,那么定位 B 中的内容则需要先到 A,然后再到 B。
iframe 中实际上是嵌入了另一个页面,而 webdriver 每次只能在一个页面识别,因此需要用 switch_to.frame 方法去获取 iframe 中嵌入的页面,对那个页面里的元素进行定位。
如果iframe里有id或者name,使用switch_to_frame()可以很方便的定位到,如
例1:
# 先找到到 ifrome1(id = f1)
driver.switch_to_frame("f1")
# 再找到其下面的 ifrome2(id =f2)
driver.switch_to_frame("f2")
# 下面就可以正常的操作元素了
driver.find_element_by_id("xx").click()
注:切到frame中之后,我们便不能继续操作主框架的元素,这时如果想操作主框架内容,则需切回主文档(最上级文档);若使用后需要再次对iframe定位需要重新从初始化的frame进行定位。
br.switch_to.default_content()
但有时会碰到iframe里没有id或者那么的情况,这就需要其他办法去定位了,如:
例2
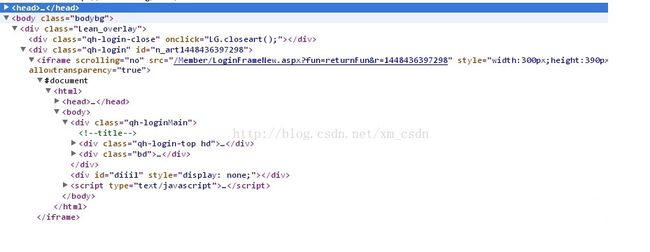
方法一:从顶层开始定位,相对比较费劲。
text1 = browser.find_element_by_class_name("bodybg")
text2 = text1.find_element_by_xpath("div[@class='Lean_overlay']/div[2]")
# 输入iframe里的src内容,确认已经定位到iframe
# text3 = text2.find_element_by_tag_name("iframe").get_attribute("src")
# print text3
text = text2.find_element_by_tag_name("iframe")
browser.switch_to.frame(text)
方法二:定位到上一次,然后再定位到iframe。
#找出所有class_name=qh-login的上一层元素
text1 = browser.find_elements_by_class_name("qh-login")
for text in text1:
if text.get_attribute("id") == "idname":
print text.get_attribute("class")
text2 = text.find_element_by_tag_name("iframe").get_attribute("src")
else:
text2 = str("定位失败了")
---------------------------------------------------------------------------------------------------------------------------------
有可能嵌套的不是框架,而是窗口,还有针对窗口的方法:switch_to_window
用法与switch_to_frame 相同:
driver.switch_to_window("windowName")
有的页面镶嵌的是frame:
用法与switch_to_frame相同:
driver.switch_to.frame("id||name")
selenium 日期控件等或者无法自动触发的,可以通过js处理
调用 js 方法
· execute_script(script, *args)
在当前窗口/框架 同步执行 javaScript
script:JavaScript 的执行。
*args:适用任何 JavaScript 脚本。
使用:
driver.execute_script(‘document.title’)
js 解释:
q=document.getElementById(\"user_name\")
元素 q 的 id 为 user_name
q.style.border=\"1px solid red\
元素 q 的样式,边框为1个像素红色
日期控件赋值代码处理:
def js_update_date(self,selector, new_value):
if selector.startswith('#'):
selector=selector[1:]
js = "document.getElementById('%s').value='%s'" % (selector, new_value)
elif "name" in selector:
selector = selector.split("'")[1]
js = "document.getElementsByName('%s')[0].value='%s'" % (selector, new_value)
self.execute_script(js)
def execute_script(self, script):
return self.driver.execute_script(script)
控制滚动条处理:
#滚动某个id元素
js="var q=document.getElementById('id').scrollTop=10000"
driver.execute_script(js)
#将页面滚动条拖到底部
js="var q=document.documentElement.scrollTop=10000"driver.execute_script(js)
#将滚动条移动到页面的顶部
js="var q=document.documentElement.scrollTop=0"driver.execute_script(js)
XPATH相关方法
1、id 获取id 的属性值
2、starts-with 顾名思义,匹配一个属性开始位置的关键字 -- 模糊定位
3、contains 匹配一个属性值中包含的字符串 -- 模糊定位
4、text() 函数文本定位
5、last() 函数位置定位
EG:
//*[@id='su'] 获取id 的属性为'su' 的值
或
//input[contains(@class,'bg s_btn')]
//a[starts-with(@name,'tj_lo')] 属性模糊定位
//a[contains(@name,'tj_lo')] 属性模糊定位
//a[text()='百度搜索']
或
//a[contains(text(),"搜索")] --文本模糊定位
//a[text()='把百度设为主页']
6.父节点
方式:/.. 或者 /parent::
EG:
# 1.xpath: `.`代表当前节点; '..'代表父节点
print driver.find_element_by_xpath("//div[@id='C']/../..").text
# 2.xpath轴 parent
print driver.find_element_by_xpath("//div[@id='C']/parent::*/parent::div").text