机器学习应用-决策树二元分类算法
1、简介
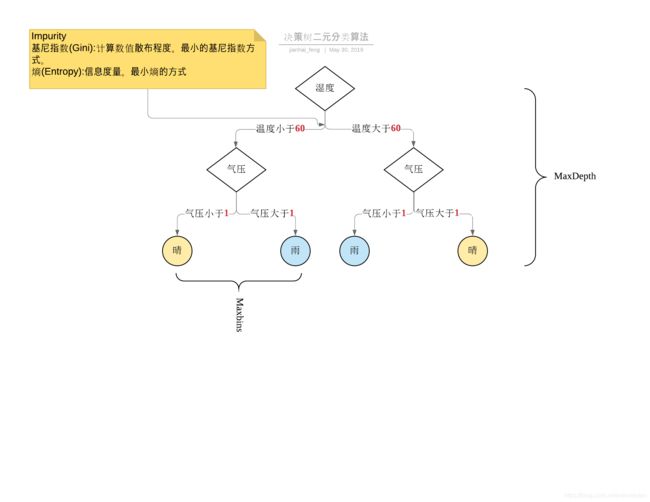
二、场景假设
暂时性(ephemeral.访问一段时间后就不访问了)网页和长青性(evergreen.有长久的兴趣)网页的分类
三、搜集数据
链接:https://pan.baidu.com/s/1UI5KnzpvgwD2zVTk1_o_Sw 密码:011k
下载完成后,在ubuntu desktop打开文件了解一下数据结构或https://www.kaggle.com/c/stumbleupon/data
四、上传文件至HDFS
cd /home/hduser/pythonwork/PythonProject/data
hadoop fs -mkdir /user/hduser/data
hadoop fs -mkdir /user/hduser/data
hadoop fs -copyFromLocal /home/hduser/pythonwork/PythonProject/data/*.tsv /user/hduser/data
四、IPython NoteBook实践
(1)local模式运行IPython NoteBook
cd /home/hduser/pythonwork/ipynotebook/
PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" MASTER=local[*] pyspark
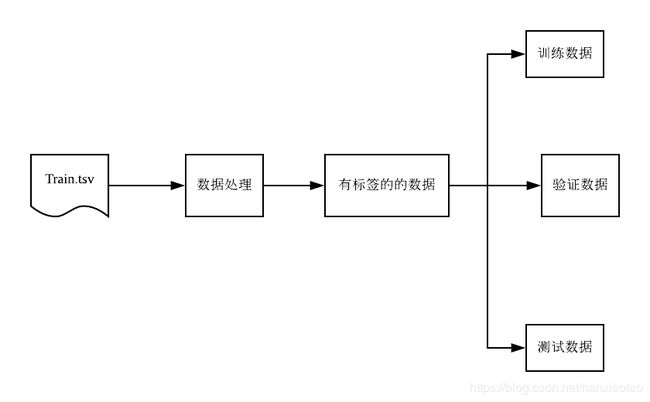
(2)数据准备
import numpy as np
from pyspark.mllib.regression import LabeledPoint
global Path
if sc.master[0:5]=="local" :
Path="file:/home/hduser/pythonwork/PythonProject/"
else:
Path="hdfs://master:9000/user/hduser/"
print("========start to import the data========")
rawDataWithHeader = sc.textFile(Path+"data/train.tsv")
#get the data of header
header = rawDataWithHeader.first()
#get the data of row
rawData = rawDataWithHeader.filter(lambda x:x !=header)
rData=rawData.map(lambda x: x.replace("\"", ""))
lines = rData.map(lambda x: x.split("\t"))
#get the data of categories
print("========get the data of categories========")
categoriesMap =lines.map(lambda fields: fields[3]) \
.distinct().zipWithIndex().collectAsMap()
#get the data of labelPoint format
print("========get the data of labelPoint format========")
labelpointRDD = lines.map( lambda r:
LabeledPoint(
extract_label(r),
extract_features(r,categoriesMap,len(r) - 1)))
#generate training,validation and test datasets at 8:1:1 scale
print("========generate training,validation and test datasets at 8:1:1 scale========")
(trainData, validationData, testData) = labelpointRDD.randomSplit([8, 1, 1])
print("trainData count:"+str(trainData.count())
+",validationData count:"+str(validationData.count())
+",testData count:"+str(testData.count()))
#extract the features
def extract_features(field,categoriesMap,featureEnd):
categoryIdx = categoriesMap[field[3]]
categoryFeatures = np.zeros(len(categoriesMap))
categoryFeatures[categoryIdx] = 1
numericalFeatures=[convert_float(field) for field in field[4: featureEnd]]
return np.concatenate(( categoryFeatures, numericalFeatures))
#convert the categories name to float
def convert_float(x):
return (0 if x=="?" else float(x))
#extract the value of label
def extract_label(field):
label=(field[-1])
return float(label)
(2)训练模型
DecisionTree.trainClassifier(input,numClasses,categoricalFeaturesInfo,impurity,maxDepth,maxBins)
| 参数 | 说明 |
|---|---|
| input | 训练数据 |
| numClasses | 分类数目 |
| categoricalFeaturesInfo | 分类特征字段信息 |
| impurity | 评估方式:gini/entropy |
| maxDepth | 决策树最大深度 |
| maxBins | 决策树每一个节点的最大分支数 |
import numpy as np
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.tree import DecisionTree
#extract the features
def extract_features(field,categoriesMap,featureEnd):
categoryIdx = categoriesMap[field[3]]
categoryFeatures = np.zeros(len(categoriesMap))
categoryFeatures[categoryIdx] = 1
numericalFeatures=[convert_float(field) for field in field[4: featureEnd]]
return np.concatenate(( categoryFeatures, numericalFeatures))
#convert the categories name to float
def convert_float(x):
return (0 if x=="?" else float(x))
#extract the value of label
def extract_label(field):
label=(field[-1])
return float(label)
def PrepareData(sc):
global Path
if sc.master[0:5]=="local" :
Path="file:/home/hduser/pythonwork/PythonProject/"
else:
Path="hdfs://master:9000/user/hduser/"
print("========start to import the data========")
rawDataWithHeader = sc.textFile(Path+"data/train.tsv")
#get the data of header
header = rawDataWithHeader.first()
#get the data of row
rawData = rawDataWithHeader.filter(lambda x:x !=header)
rData=rawData.map(lambda x: x.replace("\"", ""))
lines = rData.map(lambda x: x.split("\t"))
#get the data of categories
print("========get the data of categories========")
categoriesMap =lines.map(lambda fields: fields[3]) \
.distinct().zipWithIndex().collectAsMap()
#get the data of labelPoint format
print("========get the data of labelPoint format========")
labelpointRDD = lines.map( lambda r:
LabeledPoint(
extract_label(r),
extract_features(r,categoriesMap,len(r) - 1)))
#generate training,validation and test datasets at 8:1:1 scale
print("========generate training,validation and test datasets at 8:1:1 scale========")
(trainData, validationData, testData) = labelpointRDD.randomSplit([8, 1, 1])
print("trainData count:"+str(trainData.count())
+",validationData count:"+str(validationData.count())
+",testData count:"+str(testData.count()))
return (trainData, validationData, testData)
#get the train dataset,validation dataset,teest dataset
(trainData, validationData, testData)=PrepareData(sc)
#persist the dataset
print("========persist the datasete========")
trainData.persist()
validationData.persist()
testData.persist()
#training
print("========training========")
model=DecisionTree.trainClassifier( \
trainData, numClasses=2, categoricalFeaturesInfo={}, \
impurity="entropy", maxDepth=5, maxBins=5)
print("========saving the model========")
model.save(sc,Path+"MODEL_DecisionTree")(3)预测

def PredictData(sc,model,categoriesMap):
print("========start to import the data========")
rawDataWithHeader = sc.textFile(Path+"data/test.tsv")
header = rawDataWithHeader.first()
rawData = rawDataWithHeader.filter(lambda x:x !=header)
rData=rawData.map(lambda x: x.replace("\"", ""))
lines = rData.map(lambda x: x.split("\t"))
print("count:" + str(lines.count()) + "items")
dataRDD = lines.map(lambda r: ( r[0] ,
extract_features(r,categoriesMap,len(r) )))
DescDict = {
0: "ephemeral",
1: "evergreen"
}
for data in dataRDD.take(10):
predictResult = model.predict(data[1])
print " url: " +str(data[0])+"\n" +\
" ==>forcast:"+ str(predictResult)+ \
" desc:"+DescDict[predictResult] +"\n"
print("========get the data of categories========")
print("========load the model========")
print("========predict========")
PredictData(sc,model,categoriesMap)