最近项目组需要对老的搜索项目进行迁移和改造,刚入职2个星期的我光荣的接受了这份工作,这也是我第一次接触Haystack和Elasticsearch,以下是记录下工作中的一些需求解决,具体haystack的玩法大家可以看查看官方文档:https://django-haystack.readthedocs.io/en/master/,查看本文默认你已经基本了解了haystack的使用,包括基本的配置和使用
在开始之前,我还是有必要灌输几个概念:什么是ES,什么是Haystack,两者关系。
1.什么是ES?
在本文你只需要知道它是一个搜索服务器,存放着我们需要被搜索的数据,存储结构类似于我们的数据库,也可以对其记录进行curd的操作,重要的是能够进行‘分词’,同样是建立索引,数据库则需要把整个一句话作为索引,然后才能通过查询这一句话才能使用索引找到该记录,而ES通过‘分词’建立索引,可以建立多个单词索引指向同一记录,我们可以简单的键入一两个关键字就能调用索引弹出相关的信息,当然如果数据量少,就没必要使用ES了,毕竟这种情况下使用模糊查询也慢不了多少。
2.什么是Haystack?
Haystack 是以django的一个应用库,主要用来整合市场是的几大搜索后端作为django对它们操作的统一入口。
3.两者关系?
Haystack通过封装了各大搜索后端在python的操作库,如ES就是elasticsearch,让我们更专注于业务代码,不需要关注ES和python,django的对接。
实战需求一: 当我在表中更新了数据,我需要手动更新ES的索引
Haystack提供了 rebuild_index 和 update_index 两种方法 在你安装了haystack后 类似于这样使用: python manager.py rebuild_index(你必须配置好了haystack在django) ,分别是重建和更新。两者都是从数据库表中同步到ES服务器,中间人就是django-Haystack,所以这两者性能用起来非常差,并不是说update比rebuild一定要快很多,更新的原理就是删除原记录将新的记录再插入一边到ES中,所以在更新索引时因为ES中索引数目大时,更新无异于rebuild。庆幸的是update_index 可以传入参数 age=x ,以某个时间字段的距离现在x小时内的记录进行更新.search_index.py文件具体设置见下图
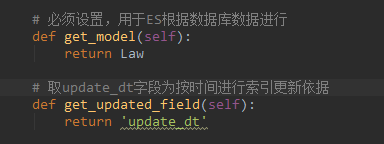
设置好后,我们需要实现一个手动执行update_index的方法,这里使用django的call_command
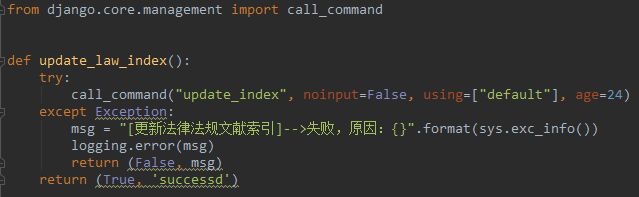
实战需求二: 我手动更新是增量的时候上述是没什么问题的,现在我要做已有内容的变更
这个需求到我手上时,有过两种方案:
方案一: 找到进行差异更新的那条索引记录,使用最新的数据覆盖。
这个方案在我翻遍了Haystack的文档后,四处找资料后,我放弃了,Haystack并没有提供这样的方法来更新某一条数据,更新并插入的动作。
方案二: 删掉旧数据,新增新数据。
这个方案最终拿上了台面,原因,新增新数据这一步其实在上面已经完成,我们只需要找到旧数据的删掉就行。
就如何找到旧数据这点事最头疼的,对于刚学会Haystack应用层使用的我来说,我知道Haystack使用 elasticsearch库莱操作ES服务器,那具体如何操作,其实还是不清楚,我能知道的就是,在search_index里我们指定了model和检索字段名,然后一顿配置后,为我们在ES中配置了和数据库相同记录数的记录 ,但这些索引记录和数据库具体记录是如何对应得我们不得而知,于是开始翻找源码查看。
几经搜索,我们在每次更新索引的方法下面找到了这行代码:
这就是Haystack操作 python-elasticsearch进行批量插入记录的方法
![]()
分析一下每个参数: self.conn 可以猜到是一个ES的操作对象,index 则是我们建立的索引库 类似于数据库,doc_type则是类似于表的存在,默认全是modelresult request_timeout=30,这个应该是没有的,我在往ES服务器重建4万条数据是发现总是会在3万多条报request timeout 所以我在这里改了默认值为30。
主要就是prepped_docs,这个参数,你可以这么理解,这就是我们要插入的数据,但是有点不同的是,但是她包括了表的列名,也就是每一条记录都有相同的一部分,就是key值,这就类似于我们的json格式 在python-elasticsearch 是这么玩的:
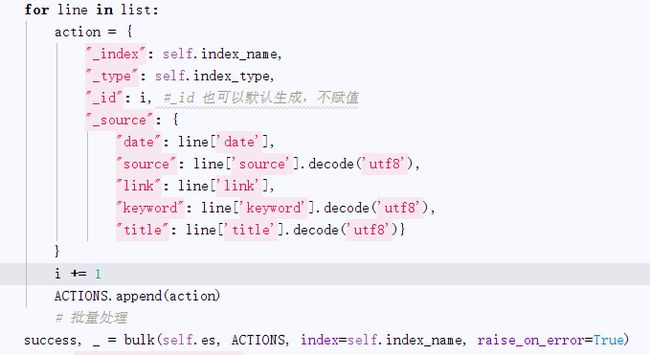
一定包含的四个字段是 “_index,_type,_id,_source”
现在我们已经找到了索引在ES保存的数据结构,我们只要找到每一条记录的唯一值,然后删除就行了,目前看起来 唯一值就是_id,确实就是。
这个id的定义方式经过一番寻找:
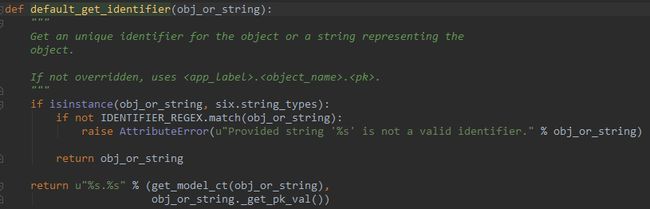
注释非常明了,如果没有被覆盖,使用: app名字.model名字.pk(也就是model里的id) 到此我们已经知道了这个id的定义方式,接下来我们就找到一个删除方法删除这条记录就行了
但是很遗憾,Haystack并没有这种单独的删除方法,所以我们只能通过操作最底层的 python-elasticsearch的删除方法:
![]()
到此,整个流程算是完了,
综上删除索引的代码就是以下两行,主要是找到这个id
es = Elasticsearch([host])
es.delete(index='设置的index_name', doc_type='modelresult', id=id)
纯原创,转载注明来源