SQL复习笔记总结
SQL( (Structured Query Language) )是用于访问和处理数据库的标准计算机语言。
1、SQL面向数据库执行查询
【1】SQL select:SELECT 语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)。
select 列名称 from 表名称
select 列名称1,列名称2 from 表名称
select * from 表名称【2】SQL distinct:关键词 DISTINCT 用于返回唯一不同的值,去除重复值。
select distinct 列名称 from 表名称【3】where:where子句用于规定选择的标准。若有条件地从表中选取数据,可将where子句添加到select语句。
select 列名称 from 表名称 where 列 运算符 值可使用的运算符:

注释:在某些版本的 SQL 中,操作符 <> 可以写为 !=。
like操作符:用于在where子句中搜索列中的指定模式。
select colunn_name
from table_name
where column_name like pattern
"%" 可用于定义通配符(模式中缺少的字母),替代一个或多个字符,_仅代替一个字符。
查找出名字以c开头的记录
select * from Person where name like 'c%'
查找出名字以g结尾的记录
select * from Person where name like '%g'
查找出名字包含john的记录
select * from Person where name like '%john%'
查找出名字不包含john的记录
select * from Person where name not like '%john%'in操作符:允许我们在where子句中规定多个值
select colunm_name(s)
from table_name
where colunm_name in (value1,value2,...)
between操作符:操作符 between... and会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
select column_name(s)
from table_name
where column_name
between value1 and value2
select column_name(s)
from table_name
where column_name
not between value1 and value2
【4】SQL and & or运算符:and和 or可在 WHERE 子语句中把两个或多个条件结合起来。
select * from 表名称 where 列名称1 运算符 值 and 列名称2 运算符 值
select * from 表名称 where 列名称1 运算符 值 or 列名称2 运算符 值【5】SQL order by:用于对结果集排序。默认按照升序对记录结果进行排序,降序可使用desc关键字指定。
select * from 表名称 order by 列名称
select * from 表名称 order by 列名称1,列名称2
select * from 表名称 order by 列名称 desc【6】SQL top:用于规定要返回的记录的数目。
select top number|percent column_name(s) from table_name
选取表中头5条记录
select top 5 from table_name
选取表中50%的记录
select top 50% * from table_name
在MYSQL中等价的语法是使用limit:
select column_name(s) from table_name limit number【7】SQL alias(别名):可以为列名称和表名称指定别名(Alias)。
select column_name(s)
from table_name
as alias_name
select column_name as alias_name
from table_name
【8】SQL join:根据两个或多个表中的列之间的关系,从这些表中查询数据。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
通过主键引用两个表获取数据
select Persons.LastName, Persons.FirstName, Orders.OrderNo
from Persons, Orders
where Persons.Id_P = Orders.Id_P (两个主键值一样)
通过使用join从两个表获取数据
select Persons.LastName, Persons.FirstName, Orders.OrderNo
from Persons
inner join Orders
on Persons.Id_P = Orders.Id_P
join: 如果表中有至少一个匹配,则返回行
inner join:内连接,在表中存在至少一个匹配时,返回行。inner join与join是相同的。
left join: 即使右表中没有匹配,也从左表返回所有的行。在某些数据库中,left join称为left outer join。
right join: 即使左表中没有匹配,也从右表返回所有的行。
full join: 只要其中一个表中存在匹配,就返回行。
【9】SQL union操作符:用于合并两个或多个select 语句的结果集。(union内部的 select语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 select语句中的列的顺序必须相同。)
默认地,UNION 操作符选取不同的值。如果允许重复的值,使用union all。
select column_name(s) from table_name1
union
select column_name(s) from table_name2
select column_name(s) from table_name1
union all
select column_name(s) from table_name2【10】SQL having子句:使你能够指定过滤条件,从而控制查询结果中哪些组可以出现在最终结果里面。where子句对被选择的列施加条件,而 having子句则对 group by子句所产生的组施加条件。
select column_name(s)
from table_name
where conditions
group by column_name(s)
having conditions
order by column_namehaving子句必须紧随group by 子句,并出现在order by子句(若有)之前。
2、SQL 可在数据库中插入新的记录
insert into语句:用于向表格中插入新的行。可指定所要插入数据的列进行插入。
insert into 表名称 values(值1,值2,...)
insert into table_name(列1,列2,...) values(值1,值2,...)slect into 语句:从一个表中选取数据,然后把数据插入另一个表中。可用于创建表的备份复件。
-- 把所有的列插入新表
select *
into new_table_name
from old_tablename
-- 插入需要的列到新表
select column_name(s)
into new_table_name
from lid_tablename3、SQL 可更新数据库中的数据
update语句:用于修改表中的数据。
更新某一行中的一个列
update 表名称 set 列名称 = 新值 where 列名称 = 某个值
更新某一行中的多个列
update 表名称 set 列名称1 = 新值1,列名称2 = 新值2 where 列名称 = 某个值4、可从数据库删除记录
delete语句:用于删除表中的行。
delete from 表名称 where 列名称 = 值
删除所有行,而不会删除表
delete from table_name/delete * from table_name5、SQL 可创建新数据库
create database语句:创建数据库
create database database_name6、SQL 可在数据库中创建新表
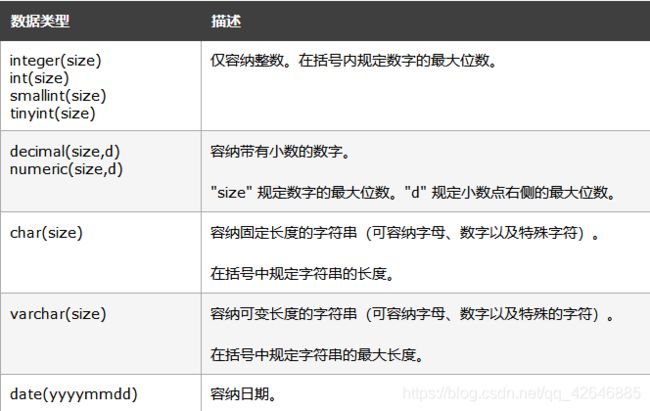
【1】create table语句:创建数据库中的表
create table table_name
(
column_name1 数据类型,
column_name2 数据类型,
column_name3 数据类型,
....
)
SQL约束(constraints):限制加入表的数据类型。
可以在创建表时规定约束(通过 create table语句),或者在表创建之后也可以(通过 alter table语句)。
not null:强制列不接受null值,字段必须始终包含值。
unique:唯一标识数据库中的每条记录。每个表可以有多个 unique约束,但是每个表只能有一个 primary key 约束。
primary key:唯一标识数据库表中的每条记录,主键必须包含唯一的值,主键列不能包含 NULL 值。每个表都应该有一个主键,并且每个表只能有一个主键。
foreign key:一个表中的foreign key 指向另一个表中的primary key。
check:限制列中的值的范围。对单个列定义 check约束,那么该列只允许特定的值。对一个表定义 check约束,那么此约束会在特定的列中对值进行限制。
default:用于向列中插入默认值。
create table Persons
(
id_P int not null primary key,
age int not null check (age>10),
lastName varchar(255) not null unique,
firstName varchar(255),
cddress varchar(255),
city varchar(255) default 'Sandnes'
id_0 int foreign key references Orders(id_p)
--mysql表示unique
unique(id_P)
--mysql 添加primary key
primary key(id_p)
--mysq表示外键
foreign key (id_0) references Order(id_0)
--mysql check
check(age>0)
--需要命名 UNIQUE 约束,以及为多个列定义 UNIQUE 约束
contraint uc_PersionID unique (id_p,lastName)
contraint uc_PersionID primary key(id_p)
)
--表已被创建时,如需在 "Id_P" 列创建 UNIQUE 约束
alter table Persons
add unique (id_p)
add primary key(id_p)
--需要添加命名 UNIQUE 约束,以及为多个列定义 UNIQUE 约束
alter table Persons
add constraint uc_PersonID unique(id_p,lastName)
--撤销nique约束
drop constraint uc_PersonID --sql server/oracle
drop index uc_PersonID -- mysql【2】drop table:删除表(表的结构、属性以及索引都会被删除)。
drop table table_name【3】truncate tale:删除表中数据。
truncate table table_name【4】alter table:在已有的表中添加、修改、删除列。
alter table table_name
-- 在表中添加列
add column_name datatype
-- 删除表中列
drop column column_name
-- 改变表中列的数据类型
alter column column_name datatype7、SQL 可在数据库中创建存储过程
存储过程 Procedure 是一组为了完成特定功能的 SQL 语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。
create procedure:创建存储过程
create proc | procedure pro_name
[{@参数数据类型} [=默认值] [output],
{@参数数据类型} [=默认值] [output],
....
]
as例子:创建了一个被称为 “latestTasks” 的存储过程。它接受一个参数名为 @Count. 当调用这个存储过程,通过 @count 参数,它决定你想要多少行返回。
create procedure latestTasks @Count int as
set rowcount@Count
select taskName as latestTasks, dateCreated
from tasks
order by dateCreated desc8、SQL 可在数据库中创建视图
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。(数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。)
create view:创建视图。
create view view_name as
select column_name(s)
from table_name
where condition
-- 更新视图
replace view view_name as
select column_name(s)
from table_name
where condition drop view:撤销视图。
drop view view_name9、SQL事务
事务是在数据库上按照一定的逻辑顺序执行的任务序列,既可以由用户手动执行,也可以由某种数据库程序自动执行。实际上就是对数据库的一个或者多个更改。实践中,通常会将很多 SQL 查询组合在一起,并将其作为某个事务一部分来执行。
事务的属性:ACID
- 原子性:保证任务中的所有操作都执行完毕;否则,事务会在出现错误时终止,并回滚之前所有操作到原始状态。
- 一致性:如果事务成功执行,则数据库的状态得到了进行了正确的转变。
- 隔离性:保证不同的事务相互独立、透明地执行。
- 持久性:即使出现系统故障,之前成功执行的事务的结果也会持久存在。
事务控制:
- commit:提交更改,保存事务对数据库所做的更改。
- rollback:回滚更改,用于撤销尚未保存到数据库中的事务。
- savepoint:在事务内部创建一系列可以rollback的还原点。
- set transaction:命名事务,初始化数据库事务,指定随后的事务的各种特征。