经分析,网易云音乐分为以下三类:免费音乐、会员下载,付费收听。
前两类音乐包含了绝大多数音乐,付费收听仅仅是极少数。
本篇爬虫目的--> 实现需要会员下载的音乐能够免费下载
核心:网易云提供了一个音乐下载接口 http://music.163.com/song/media/outer/url?id=音乐ID.MP3 将音乐ID替换为相应的音乐ID就行,然后请求该链接获得MP3文件
方式一(适用小白)
在在网易云客户端找到复制链接
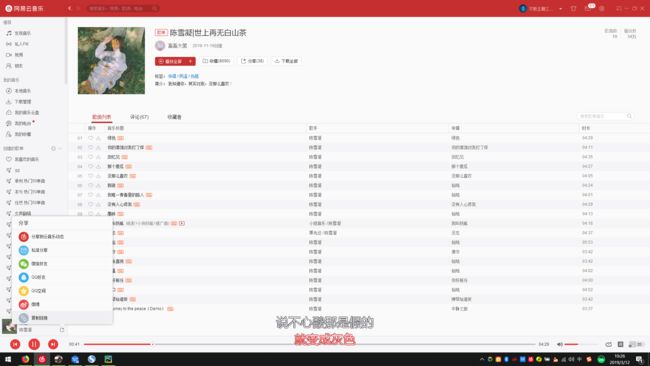
然后将复制到的链接粘贴出来 类似于这种 https://music.163.com/song?id=1345848098&userid=315893058 1345848098 即为音乐ID 然后对接口进行替换得到 下载链接 绿色-陈雪凝(会员下载音乐)http://music.163.com/song/media/outer/url?id=1345848098.MP3
方式二(爬虫):
该方式不是对方式一的代码实现,而是实现歌单下载
第一步,找到歌单链接(在歌单的分享里面的 复制链接)
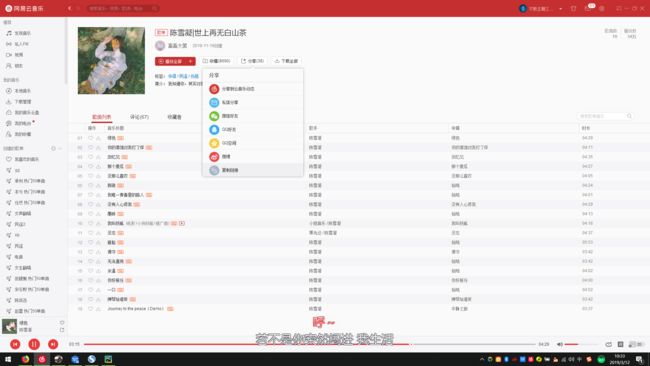
链接类似于 https://music.163.com/playlist?id=2520126575&userid=315893058
第二步,在浏览器访问该链接
F12 打开调试模式
点击箭头所指图标,然后点击任意音乐名字
可以看出下面的html源码中出现了蓝色标志;
该代码区域为该音乐的标签代码,因为这是一个列表,所以所有音乐都是这个格式。
爬取核心,直接提取该页面所有a标签,并进行判断里面是否存在b标签和a标签的 href 是否以 /song?id=开头,因为b标签里面含有音乐名,有的a标签和音乐标签类似,但是没有b标签,也不是我们要的音乐,所以要进行排除
代码:
传入列表链接 解析列表,获取歌单所有音乐 ID,并生成下载链接
def ParsingPlayList(self, url): response=requests.get(url=url, headers=CloudMusic.header) soup=BeautifulSoup(response.text, "html.parser") alist=soup.select("a") Songs=[] for music in alist: if music.has_attr("href"): if str(music.attrs["href"]).startswith("/song?id="): id=str(music.attrs["href"]).replace("/song?id=", "") try: Songs.append({ "id": id, "url": "http://music.163.com/song/media/outer/url?id=" + id + ".mp3", "name": music.text }) except: pass return Songs


import requests from bs4 import BeautifulSoup import os STATUS_OK,STATUS_ERROR,STATUS_EXITS=1,-1,0 class CloudMusic: header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0' } def Down(self, down_url, filePath, NowIndex, TotalCount, FileDir): if not os.path.isdir(FileDir): os.makedirs(FileDir) if os.path.isfile(FileDir + "/" + filePath + ".mp3"): print(filePath+",本地已存在") return STATUS_EXITS response = requests.get(down_url, headers=CloudMusic.header, allow_redirects=False) try: r = requests.get(response.headers['Location'], stream=True) size=int(r.headers['content-length']) print('\033[0;31m'+str(NowIndex) + "/" + str(TotalCount) + " 当前下载-" + filePath + " 文件大小:" + str(size) + "字节"+"\033[0m") CurTotal=0 with open(FileDir + "/" + filePath + ".mp3", "wb") as f: for chunk in r.iter_content(chunk_size=512*1024): if chunk: f.write(chunk) CurTotal += len(chunk) print("\r" + filePath + "--下载进度:" + '%3s' % (str(CurTotal*100//size)) + "%", end='') print() r.close() return STATUS_OK except Exception as e: print(filePath + " 下载出错!" + " 错误信息" + str(e.args)) if os.path.isfile(FileDir + "/" + filePath + ".mp3"): os.remove(FileDir + "/" + filePath + ".mp3") return STATUS_ERROR def ParsingPlayList(self, url): response=requests.get(url=url, headers=CloudMusic.header) soup=BeautifulSoup(response.text, "html.parser") alist=soup.select("a") Songs=[] for music in alist: if music.has_attr("href"): if str(music.attrs["href"]).startswith("/song?id="): id=str(music.attrs["href"]).replace("/song?id=", "") try: Songs.append({ "id": id, "url": "http://music.163.com/song/media/outer/url?id=" + id + ".mp3", "name": music.text }) except: pass return Songs def Start(self, MusicList, Dd): total=len(MusicList) CurIndex=OkCount=FalseCount=ExitCount=0 print("歌单共计:" + str(len(MusicList)) + "首") for data in MusicList: CurIndex+=1 status=self.Down(data["url"],data["name"].replace("/",""),CurIndex,total,Dd) if status==1: OkCount+=1 elif status==0: ExitCount+=1 else: FalseCount+=1 print("下载成功"+str(OkCount)+"首"+"\n下载失败"+str(FalseCount)+"首"+"\n本地已存在"+str(ExitCount)+"首") if __name__=="__main__": CrawlerClient= CloudMusic() # CrawlerClient.Start(CrawlerClient.ParsingPlayList("https://music.163.com/playlist?id=1992662269&userid=315893058"), "广场舞") # CrawlerClient.Start(CrawlerClient.ParsingPlayList("https://music.163.com/playlist?id=2584781662"),"治愈") CrawlerClient.Start(CrawlerClient.ParsingPlayList("https://music.163.com/playlist?id=2243470689&userid=315893058"),"mp3")