LeetcCode之图
1、什么是图:
图就是一堆顶点和边对象而已,可以用邻接表和邻接矩阵表示。
2、注意事项:
在 稀疏图的情况下,每一个顶点都只会和少数几个顶点相连,这种情况下相邻列表是最佳选择。如果这个图比较密集,每一个顶点都和大多数其他顶点相连,那么相邻矩阵更合适。
3、核心算法
(1) 深度优先搜索
(2) 广度优先搜索
(3) 并查集
(4) Kruskal算法
(5) Prim算法
(6) 拓扑排序
(7)迪杰斯特拉算法
搜索——终止——回溯——搜索——直到找到解/遍历全部节点。
(一)深度优先搜索(DFS)
适合有明确目标情况。
举例一(leetcode200)
给定一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
思路:定义一个寻找岛屿的函数move和一个visited二维数组判断是否访问过某个岛屿,
class Solution:
island = 0
def numIslands(self, grid: List[List[str]]) -> int:
if not grid: return 0 #图为空
def move(x, y):
visited[x][y] = True
for pos in positions:
if 0 <= x + pos[0] < row and 0 <= y + pos[1] < col and grid[x + pos[0]][y + pos[1]] == '1' and not visited[x + pos[0]][y + pos[1]]:
move(x + pos[0], y + pos[1])
positions = [(0, 1),(0,-1),(1,0),(-1,0)]
row, col = len(grid), len(grid[0])
visited = [[False for _ in range(col)] for _ in range(row)]
for i in range(row):
for j in range(col):
if grid[i][j] == '1' and not visited[i][j]:
move(i, j)
self.island += 1
return self.island

举例二 (leetcode130)
给定一个二维的矩阵,包含 ‘X’ 和 ‘O’(字母 O)。
找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。
思路:分别从矩阵的四个边缘上将没有被'X'围绕的区域用'B'覆盖,
最后将'B'覆盖的区域用'O'代替,'O'覆盖的区域用'X'代替
class Solution:
def solve(self, board: List[List[str]]) -> None:
"""
Do not return anything, modify board in-place instead.
"""
if not board: return
position = [(0,1),(0,-1),(1,0),(-1,0)]
def dfs(x, y):
board[x][y] = 'B'
for pos in position:
tem_x, tem_y =x + pos[0], y + pos[1]
if 1 <= tem_x < row - 1 and 1 <= tem_y < col - 1 and board[tem_x][tem_y] == 'O':
dfs(tem_x, tem_y)
row, col = len(board), len(board[0])
#左右两侧
for i in range(row):
if board[i][0] == 'O':
dfs(i, 0)
if board[i][col - 1] == 'O':
dfs(i, col - 1)
#上下两侧
for j in range(col):
if board[0][j] == 'O':
dfs(0, j)
if board[row - 1][j] == 'O':
dfs(row - 1, j)
for i in range(row):
for j in range(col):
if board[i][j] == 'O':
board[i][j] = 'X'
elif board[i][j] == 'B':
board[i][j] = 'O'
(二)广度优先搜索(BFS)
广度优先搜索BFS(Breadth First Search)也称为宽度优先搜索,它是一种先生成的结点先扩展的策略。适合寻找最优解情况
广度优先搜索算法的搜索步骤一般是:
(1)从队列头取出一个结点,检查它按照扩展规则是否能够扩展,
如果能则产生一个新结点。
(2)检查新生成的结点,看它是否已在队列中存在,如果新结点
已经在队列中出现过,就放弃这个结点,然后回到第(1)步。否
则,如果新结点未曾在队列中出现过,则将它加入到队列尾。
(3)检查新结点是否目标结点。如果新结点是目标结点,则搜索
成功,程序结束;若新结点不是目标结点,则回到第(1)步,再
从队列头取出结点进行扩展。
最终可能产生两种结果:找到目标结点,或扩展完所有结点而没有
找到目标结点。
举例一(leetcode200)
给定一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
class Solution:
island = 0
def numIslands(self, grid: List[List[str]]) -> int:
positions = [(0, 1), (0, -1), (-1, 0), (1, 0)]
def bfs(x, y):
grid[x][y] = '0'
for pos in positions:
tem_x, tem_y = x + pos[0], y + pos[1]
if 0<=tem_x<row and 0<=tem_y<col and grid[tem_x][tem_y] == '1':
queue.append((tem_x, tem_y))#新找到的点加入队列#新找到的点加入队列
if queue:
pos = queue.pop() #从队列头部开始遍历
bfs(pos[0], pos[1])
if not grid: return 0
row, col = len(grid), len(grid[0])
queue = []
for i in range(row):
for j in range(col):
if grid[i][j] == '1':
bfs(i, j)
self.island += 1
return self.island

举例二(leetcode529)
让我们一起来玩扫雷游戏!
给定一个代表游戏板的二维字符矩阵。 ‘M’ 代表一个未挖出的地雷,‘E’ 代表一个未挖出的空方块,‘B’ 代表没有相邻(上,下,左,右,和所有4个对角线)地雷的已挖出的空白方块,数字(‘1’ 到 ‘8’)表示有多少地雷与这块已挖出的方块相邻,‘X’ 则表示一个已挖出的地雷。
现在给出在所有未挖出的方块中(‘M’或者’E’)的下一个点击位置(行和列索引),根据以下规则,返回相应位置被点击后对应的面板:
如果一个地雷(‘M’)被挖出,游戏就结束了- 把它改为 ‘X’。
如果一个没有相邻地雷的空方块(‘E’)被挖出,修改它为(‘B’),并且所有和其相邻的方块都应该被递归地揭露。
如果一个至少与一个地雷相邻的空方块(‘E’)被挖出,修改它为数字(‘1’到’8’),表示相邻地雷的数量。
如果在此次点击中,若无更多方块可被揭露,则返回面板。
思路:根据题目要求选择一个挖地雷的位置,会出现以下几种情况:
(1)空白:递归找到其它相连的空白格以及与空白格接触的边缘方块(可以是数字也可以是雷),返回面板
(2)数字:将当前格子修改成对应数字,返回面板
(3)雷: 将当前格子修改成'X',返回面板
class Solution:
def updateBoard(self, board: List[List[str]], click: List[int]) -> List[List[str]]:
positions = [(1, 0), (-1, 0), (0, 1), (0, -1), (1, -1), (1, 1), (-1, -1), (-1, 1)]
def scan(x, y):
count = 0
for pos in positions:
tem_x, tem_y = pos[0] + x, pos[1] + y
if not(0 <= tem_x < row and 0 <= tem_y < col): continue
#判断当前格子周围雷的数量
if board[tem_x][tem_y] == 'M' or board[tem_x][tem_y] == 'X': count += 1
#如果是空白格子,将其周围未判定的格子加入队列,广度优先搜索
if not count:
for pos in positions:
if not(0 <= x+pos[0]< row and 0 <= y+pos[1] < col): continue
if board[x+pos[0]][y+pos[1]] == 'E': queue.append((x+pos[0],y+ pos[1]))
board[x][y] = str(count) if count else 'B'
#每次递归从队列头部取出一个位置
if queue:
pos = queue.pop()
scan(pos[0], pos[1])
if not board: return board
row, col = len(board), len(board[0])
queue = []
#如果踩雷,直接结束游戏
if board[click[0]][click[1]] == 'M':
board[click[0]][click[1]] = 'X'
return board
scan(click[0], click[1])
return board
(三)并查集
(详解看这里)
python核心代码:
#寻找根节点
def find(x):
f.setdefault(x, x)
if f[x] != x:
f[x] = find(f[x])
return f[x]
#并查
def union(x, y):
f[find(x)] = find(y)
java核心代码:
public static class UnionFind {
int[] parent;
int[] rank;
public UnionFind(int total) {
parent = new int[total];
rank = new int[total];
for (int i = 0; i < total; i++) {
parent[i] = i;
rank[i] = 1;
}
}
public int find(int x) {
while (x != parent[x]) {
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[pRoot] > rank[qRoot]) {
parent[qRoot] = pRoot;
} else {
parent[pRoot] = qRoot;
rank[qRoot] += 1;
}
}
}
详解里说的很清楚,这里只补充一点:
Path compression:
将连通分量看作为一棵树,在循环的find操作中,将树中的每个结点都连接到parent结点,从而降低树的高度。降低树的高度就是能够降低查找的时间复杂度,从O(n) 降为了O(logn) 。
Union by rank:
另外一个问题就是进行Union操作时,需要将高度低的树连接到高度教高的树上,目的是减少union后的整棵树的高度。rank代表的就是树的高度。
举例一(leetcode200)
给定一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
使用并查集解决本问题的思想很简单:
1、如果当前是“陆地”,尝试与周围合并一下;
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
uf = {}
#模版--------------------------起始线
#寻找根节点
def find(x):
uf.setdefault(x, x)
if uf[x] != x:
uf[x] = find(uf[x])
return uf[x]
#合并集合
def union(x, y):
uf[find(x)] = find(y)
#模版---------------------------终止线
if not grid: return 0
row, col = len(grid), len(grid[0])
positions = [(0, 1), (1, 0)]
for i in range(row):
for j in range(col):
if grid[i][j] == '1':
for pos in positions:
new_i = i + pos[0]
new_j = j + pos[1]
if new_i < row and new_j < col and grid[new_i][new_j] == '1':
#新节点的上级节点是移动之前的节点
union(new_i * row + new_j, i * row + j)
ans = set()
for i in range(row):
for j in range(col):
if grid[i][j] == '1':
ans.add(find(i * row + j))
return len(ans)
举例三(leetcode721)
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该帐户的邮箱地址。
现在,我们想合并这些帐户。如果两个帐户都有一些共同的邮件地址,则两个帐户必定属于同一个人。请注意,即使两个帐户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的帐户,但其所有帐户都具有相同的名称。
合并帐户后,按以下格式返回帐户:每个帐户的第一个元素是名称,其余元素是按顺序排列的邮箱地址。accounts 本身可以以任意顺序返回。
class Solution:
def accountsMerge(self, accounts: List[List[str]]) -> List[List[str]]:
#模版--------------------------起始线
uf = {}
#寻找根节点
def find(x):
uf.setdefault(x, x)
if uf[x] != x:
uf[x] = find(uf[x])
return uf[x]
#合并集合
def union(x, y):
uf[find(x)] = find(y)
#模版---------------------------终止线
res = collections.defaultdict(list)
email_to_name = {} #存储邮箱与用户的映射
for account in accounts:
for i in range(1, len(account)):
email_to_name[account[i]] = account[0]
#相同用户邮箱合并
union(account[1],account[i])
for email in email_to_name:
res[find(email)].append(email)
return [[email_to_name[value[0]]] + sorted(value) for value in res.values()]
四、克鲁斯卡尔算法(Kruskal算法)
Kruskal算法是贪心算法(nlogn), 核心是并查集。
操作步骤
输入: 图G
输出: 图G的最小生成树
具体流程:
(1)将图G看做一个森林,每个顶点为一棵独立的树
(2)将所有的边加入集合S,即一开始S = E
(3)从S中拿出一条最短的边(u,v),如果(u,v)不在同一棵树内,则连接u,v合并这两棵树,同时将(u,v)加入生成树的边集E’
(4)重复(3)直到所有点属于同一棵树,边集E’就是一棵最小生成树
举例一 最低成本联通所有城市
想象一下你是个城市基建规划者,地图上有 N 座城市,它们按以 1 到 N 的次序编号。
给你一些可连接的选项 conections,其中每个选项 conections[i] = [city1, city2, cost] 表示将城市 city1 和城市 city2 连接所要的成本。(连接是双向的,也就是说城市 city1 和城市 city2 相连也同样意味着城市 city2 和城市 city1 相连)。返回使得每对城市间都存在将它们连接在一起的连通路径(可能长度为 1 的)最小成本。该最小成本应该是所用全部连接代价的综合。如果根据已知条件无法完成该项任务,则请你返回 -1。
------------------------简单并查集-----------------------
class UnionFind{
private int[] parents;
public UnionFind(int x){
parents = new int[x];
}
public int find(int x){
if(parents[x] == 0) parents[x] = x;
else{
parents[x] = find(parents[x]);
}
return parents[x];
}
public void union(int x, int y){
parents[find(x)] = find(y);
}
}
--------------------------------------------------------
class Solution {
public int getMST(int[][] connections) {
//int[][] connections = {{1,2,5}, {1,3,6}, {2,3,1}};
int ans = 0, size = connections.length;
UnionFind uf = new UnionFind(size + 1);
//最小生成树有size条边, size+1个节点
for(int j = 0; j<size - 1; j++){
int min = 10000, left = -1, right = -1;
for(int k = 0; k<size; k++){
//核心:最小边不位于同一棵树中
if(uf.find(connections[k][0]) != uf.find(connections[k][1]))
{
min = Math.min(min, connections[k][2]);
left = connections[k][0]; right = connections[k][1];
}
}
//构造MST失败
if(left == -1 || right == -1 || min == 10000) return 0;
//将left, right所在子树合并
uf.union(left, right);
ans += min;
}
return ans;
}
}
class Solution:
def minimumCost(self, N: int, connections: List[List[int]]) -> int:
if len(connections) < N - 1:
return -1
connections.sort(key=lambda a : a[2])
parent = [i for i in range(N)]
def find(x):
if x != parent[x]:
parent[x] = find(parent[x])
return parent[x]
res, e, k = 0, 0, 0
while e < N - 1:
u, v, w = connections[k]
k += 1
x, y = find(u-1), find(v-1)
if x != y:
e += 1
res += w
parent[x] = y
return res
举例二(leetcode684)
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
class Solution:
python代码
def findRedundantConnection(self, edges: List[List[int]]):
uf = {}
rank = {}
#寻找根节点
def find(x):
uf.setdefault(x, x)
if uf[x] != x:
uf[x] = find(uf[x])
return uf[x]
#合并集合
def union(x, y):
uf[find(x)] = find(y)
for edge in edges:
if find(edge[0]) != find(edge[1]):
union(edge[0], edge[1])
else:
return edge
java代码:
public int[] findRedundantConnection(int[][] edges) {
UnionFind uf = new UnionFind(edges.length + 1);
int[] res = new int[2];
for(int i = 0; i<edges.length; i++){
int root = edges[i][0], node = edges[i][1];
//左右子树不在同一棵树上
if(uf.find(root) != uf.find(node)){
uf.unionElements(root, node);
}
else {
res[0] = root; res[1] = node;
break;
}
}
return res;
}
}
举例三(leetcode685)
在此问题中,一棵根树是一个有向图,这样,正好有一个节点(根),所有其他节点都是该节点的后代,加上每个节点都只有一个父节点,但根节点没有父母。
给定的输入是一个有向图,开始于有N个节点(具有不同的值1、2,…,N)的根树,并添加了一个附加的有向边。所添加的边具有从1到N中选择的两个不同的顶点,并且不是已经存在的边。
所得图形以边的2D数组形式给出。边的每个元素都是一对[u,v],代表连接节点u和v的有向边,其中u是子v的父级。
返回可以删除的边,以使结果图成为N个节点的根树。如果有多个答案,请返回给定2D数组中最后出现的答案。
class Solution:
def findRedundantDirectedConnection(self, edges: List[List[int]]) -> List[int]:
def isloop(end):
cur=end
while cur in parents:
cur=parents[cur]
if cur==end:
return True
return False
uf={}
def find(x):
uf.setdefault(x,x)
if uf[x]!=x:
uf[x]=find(uf[x])
return uf[x]
def union(x,y):
uf[find(x)]=find(y)
parents={}
unionCandidate=[]
candidates=[]
for start,end in edges:
if end not in parents:
parents[end]=start
else:
candidates=[[parents[end],end],[start,end]]
if find(start)==find(end):
unionCandidate=[start,end]
else:
union(start,end)
if candidates:
if isloop(candidates[0][1]):
return candidates[0]
return candidates[1]
else:
return unionCandidate
五、普里姆算法(Prim算法)【参考此文】
理解:图论中的一种算法,可在加权连通图里搜索最小生成树。即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点(英语:Vertex (graph theory)),且其所有边的权值之和亦为最小。
步骤:
1、初始化加权连同图,顶点集合V,边集合E, 选择顶点集合Vnew, 边集合Enew;
2、将V中的任意一个节点加入到Vnew中,即Vnew = {v1} V = V - {v1}
3、重复下列操作,直到V = {}:
a.在集合E中选取权值最小的边
b.将v2加入集合Vnew中,将
4、输出:使用集合Enew来描述所得到的最小生成树。
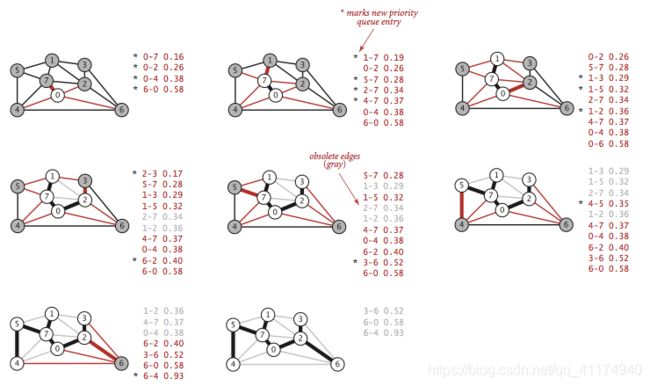
//Prim算法
#include 六、拓扑排序
在计算机科学领域,有向图的拓扑排序(Topological Sort)是其顶点的线性排序,使得对于从顶点 u 到顶点 vv的每个有向边 uv,u在排序中都在 v 之前。例如,图形的顶点可以表示要执行的任务,并且边可以表示一个任务必须在另一个任务之前执行的约束;在这个应用中,拓扑排序只是一个有效的任务顺序。
如果且仅当图形没有定向循环,即如果它是有向无环图(DAG),则拓扑排序是可能的。任何 DAG 具有至少一个拓扑排序,存在算法用于在线性时间内构建任何 DAG 的拓扑排序。
拓扑排序可以通过DFS和BFS实现。
举例一(leetcode207)
现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
给定课程总量以及它们的先决条件,判断是否可能完成所有课程的学习?
本题分别通过BFS和DFS来实现拓扑排序
(一)BFS
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
indegree = [0 for _ in range(numCourses)]
pre_node = [[] for _ in range(numCourses)]
if not prerequisites: return True
#计算所有点的入度以及以它为前置点的节点
for cur, pre in prerequisites:
indegree[cur] += 1
pre_node[pre].append(cur)
queue = []
#将入度为0的点加入队列
for i in range(len(indegree)):
if indegree[i] == 0:
queue.append(i)
#BFS
while queue:
pre = queue.pop()
numCourses -= 1
#删除节点后,其邻接节点入度减一
for i in pre_node[pre]:
indegree[i] -= 1
#将入度为0的节点加入队列
if indegree[i] == 0: queue.append(i)
#判断是否有环,如果没有环所有节点都应弹出
return not numCourses
(二)DFS
思路:
对于拓扑排序经过节点赋值分为以下三种情况,分别是:
-1:此课程及其子课程均判断过
1:此课程判断过,但是子课程没有全部判断
0:此课程未经判断
本算法从未判断课程进入,若dfs过程中遇到标1的课程,说明有回路
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
#记录课程状态(-1,1,0)
visited = [0 for _ in range(numCourses)]
pre_node = [[] for _ in range(numCourses)]
#计算所有点的后置节点
for cur, pre in prerequisites:
pre_node[pre].append(cur)
def dfs(num):
#有环
if visited[num] == 1:
return False
visited[num] = 1
#判断后续课程是否构成环
for cur in pre_node[num]:
if not dfs(cur): return False
#说明当前访问节点已被其他节点启动的 DFS 访问,无需再重复搜索
visited[num] = -1
return True
for i in range(numCourses):
if visited[i] == 0:
if not dfs(i): return False
return True
七、迪杰斯特拉算法(Dijkstra算法)
理解:Dijkstra是从一个顶点到其余各顶点的最短路径算法,解决的是有权图中最短路径问题。迪杰斯特拉算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。
//迪杰斯特拉
#include 743. 网络延迟时间
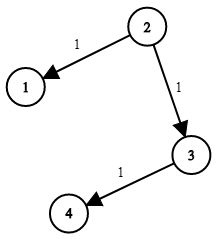
有 N 个网络节点,标记为 1 到 N。
给定一个列表 times,表示信号经过有向边的传递时间。 times[i] = (u, v, w),其中 u 是源节点,v 是目标节点, w 是一个信号从源节点传递到目标节点的时间。
现在,我们从某个节点 K 发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 -1.
示例:
class Solution {
public int networkDelayTime(int[][] times, int N, int K) {
//由题意设置二维矩阵
int[][] map = new int[N + 1][N+1];
//当前状态下远点到其余各点的最短距离
int[] len = new int[N+1];
//此点是否为最佳状态
int[] pass = new int[N+1];
//数据初始化
for(int i = 1; i<=N; i++){
len[i] = 10000;
pass[i] = 0;
for(int j = 1; j<=N; j++){
if(i == j) {map[i][j] = 0;continue;}
map[i][j] = 10000;
}
}
//初始点到自身距离为0, 初始点已经是最佳状态
len[K] = 0; pass[K] = 1;
//数据初始化
for(int i = 0; i<times.length; i++)
{
int[] temp = times[i];
map[temp[0]][temp[1]] = temp[2];
}
//核心部分
int min = 10000, index = K, target = K, count = N, max = 0;
while(count > 0){
for(int i = 1; i<=N; i++){
//判断所有未达最佳状态的点
if(pass[i] == 0){
//从最佳状态点 index 到i点的距离与之前状态下到i点距离较小值
//即当前状态下初始点到其余各点的最短距离状态
len[i] = Math.min(map[index][i] + len[index], len[i]);
//寻找当前状态下初始点到其余点中的最短距离target,在
//之后各状态下,其余点到该target距离一定大于当前值
if(len[i]<min) {min = len[i]; target=i;}
}
}
//target已经达到最佳状态
pass[target] = 1; min = 10000;
index = target; count -= 1;
}
for(int i = 1;i<=N; i++){
if(len[i] >= 10000) return -1;
max = Math.max(len[i], max);
}
return max;
}
}