时序行为检测论文笔记(三):Temporal Context Network for Activity Localization in Videos
摘要:
1.提出了一种时间上下文网络(TCN),用于人类活动的预先定位。类似于Faster RCNN架构,proposal以等间隔放置在跨越多个时间尺度的视频中。
2.由于仅在一个段内部pooling功能并不足以预测活动边界,因此构造一个表示,该表示明确捕获用于对其排名的proposal的上下文,对于每一个时间片段,将特征在一对尺度上均匀采样并且输入到时间卷积神经网络用于分类。
(性能优于CDC)
1.介绍
行为被定义是短时间内的动作例如跳,扔,敲。相反,活动有一个由一个动作或事件(包含多种行为)组成的开始和结束,例如一个活动像“组装家具”可以以开箱子为开始,以将不同部分组装为持续,以家具完成为结束。由于视频可以是任意长,可能包含多种活动,因此需要时序定位。
应用:基于视频的网络搜索引擎视频检索,减少浏览冗长的视频所需的工作量,监控视频监控中的可疑活动等。
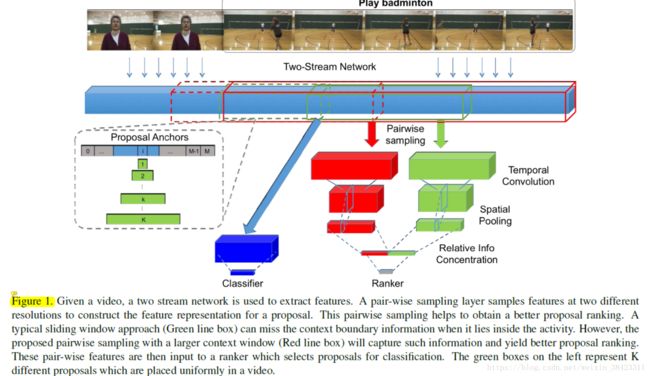
上图中,红色和绿色固体片段是两个完全包含在活动中的proposal,虽然红色部分是一个很好的候选人,但绿色不是。因此,尽管一个细分市场的单一尺度表征可捕获足够的识别信息,但不足以进行检测。为了捕获预测活动边界的信息,我们建议在proposal级别和高级别proposal中明确采样特征,同时对proposal进行排序。我们通过实验验证,在对时间活动proposal进行排序是对性能有显著影响。
通过以等时间间隔在跨越多个时间尺度的视频中放置proposal,本文构建了一组proposal,然后使用成对尺度采样的特征对proposal序。 对这些特征应用时间卷积网络来学习背景和前景概率。 然后将排名最高的proposal输入到分类网络,该分类网络将各个分类概率分配给每个分段proposal。
三、方法
给定由T帧组成的视频V,TCN生成分段S1,S2,...,SN的分级列表,每个分段与分数相关联。 每个段Sj是一个元组Tb,Te,其中Tb和Te表示段的开始和结束。 对于每一帧,我们计算一个使用深度神经网络生成的D维特征向量表示。我们的方法概述如图2所示。
3.1候选框生成
在这一步中的目标是使用少量proposal来获得高召回率。 首先,我们采用一个固定长度的L帧的时间滑动窗口,其中50%重叠。假设每个视频V具有M个窗口位置。 对于位置i(i 属于 [0,M])上的每个窗口,其持续时间被指定为元组(bi,ei),其中bi和ei表示段的开始和结束。 然后,我们在每个位置i生成K个proposal细分(以K不同比例)。 对于k 属于 [1,K],分段由(bki,eki)表示。 而且,每个段的持续时间Lk以2的幂增加,即![]() 。 这允许我们覆盖所有可能包含兴趣活动的候选活动位置,并且我们将它们称为活动proposal,
。 这允许我们覆盖所有可能包含兴趣活动的候选活动位置,并且我们将它们称为活动proposal,![]() 。 图1显示了时间proposal的生成。 当proposal片段符合视频的边界时,我们使用zero-padding。
。 图1显示了时间proposal的生成。 当proposal片段符合视频的边界时,我们使用zero-padding。
3.2 文本特征表示
我们接下来构建排名proposal的功能表示。我们使用未修剪视频的所有特征F = {f1,f2,...,fm}作为视频的特征表示。对于窗口位置i(Pi,k)处的第k个proposal,我们对F进行均匀采样以获得D维特征表示Zi,k = {z1,z2,...,zn}。这里,n是从每个片段采样的特征的数量。为了捕获时间上下文,我们再次从F中一致地采样特征,但是这次,从(Pi,k + 1) - 下一个比例的proposal并以相同比例为中心。请注意,我们不执行平均或最大池化,而是取样固定数量的帧,而不管Pi,k的持续时间。从逻辑上讲,proposal可以分为四类:
•它与地面真实间隔不相交,因此下一个尺度的(更大的)标签是不相关的
•它包括一个地面真值间隔,下一个尺度与该地面真值间隔部分重叠。
•它包含在地面真值间隔中,下一个层次与背景有明显的重叠(即大于地面真值间隔)。
•它包含在地面真相间隔中,下一层也是如此。
仅考虑proposal内的特征的表示不会考虑最后两种情况。因此,只要proposal处于活动时间间隔内,就不可能仅通过考虑proposal内的功能来确定活动的结束位置。因此,使用基于上下文的表示对于活动的时间定位至关重要。此外,根据当前和下一个衡量标准覆盖的背景的多少,可以确定proposal是否是合适的候选者。
3.3 采样和时间卷积
为了训练proposal网络,根据以下式子作为指定标签:
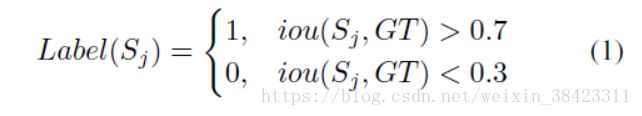
其中iou(·)是交叠重叠的交点,GT是地面真值间隔。 在训练期间,我们构建了一个有1024个proposal的最小批次,其正负比率为1:1。
给定一对来自两个连续尺度的特征![]() ,我们将时间卷积分别应用于每个时间尺度采样的特征,以获取尺度之间的上下文信息,如图2所示。时间卷积神经网络 [16]加强时间一致性,并获得静态图像检测一致的性能改进。 为了跨越尺度汇总信息,我们连接这两个特征以获得固定的三维表示。 最后,使用两个完全连接的层来捕获跨越尺度的上下文信息。 最后使用双向Softmax层,然后是交叉熵损失,将预测映射到标签(proposal与否)。
,我们将时间卷积分别应用于每个时间尺度采样的特征,以获取尺度之间的上下文信息,如图2所示。时间卷积神经网络 [16]加强时间一致性,并获得静态图像检测一致的性能改进。 为了跨越尺度汇总信息,我们连接这两个特征以获得固定的三维表示。 最后,使用两个完全连接的层来捕获跨越尺度的上下文信息。 最后使用双向Softmax层,然后是交叉熵损失,将预测映射到标签(proposal与否)。

3.4 分类
给出一个高分的proposal,我们需要预测它的行动类别。 我们通过使用双线性汇聚计算每个片段特征的外积,并将它们平均汇集以获得双线性矩阵双线性(·)。 给定特征Z = [z1,z2,... zl],我们进行如下的双线性汇聚:
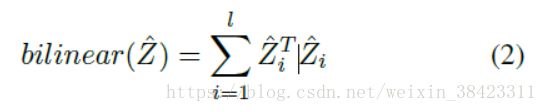
为了进行分类,我们汇集了片段内的所有特征并且不执行任何时间采样。 我们通过带符号平方根和l2归一化的映射函数传递这个向量化的双线性特征x =双线性(Z)[24]:

我们最后应用完全连接的层,并在末尾使用201维(200个动作类别加背景)Softmax层来预测类别标签。 我们再次使用交叉熵损失函数进行训练。 在训练期间,我们抽取了1024个proposal来构建一个小批量。 为了平衡训练,在每个小批次中选择64个样本作为背景。为了给视频片段分配标签,我们使用用于生成proposal的相同功能,

其中iou(·)是工会重叠的交点,GT是地面实况,lb是提案Sj中最主要的类别。 我们将这个分类器用于ActivityNet数据集,但也可以用其他分类器替换。
4.实验
4.1 实施细节
我们基于具有Python接口的定制Caffe存储库实现网络。所有的评估实验都是在Titan X(Maxwell)GPU的工作站上进行的。我们使用预先训练好的TSN模型[35]初始化我们的网络,并在动作标签和前景/背景标签上对它们进行微调以捕捉“动作”和“背景”。后来,我们将这些作为高级功能输入到我们的proposal排名和分类器中。对于proposal排序器,我们使用时间卷积,内核大小为5,步幅为1,随后是ReLU激活,并使用大小为3和步幅1的平均共享。然后将时间卷积响应连接并映射到完全连接的层,其中500个隐藏单位,用于预测proposal得分。为了评估我们的检测任务的方法,我们生成最高K个proposal(K设置为20,我们应用非最大抑制来过滤掉类似的proposal,使用NMS阈值设置为0.45)并将它们分开分类。在对proposal进行分类的同时,我们还使用ImageNet shuffle特性[19]和“动作”特性融合了两个全球视频级别的先验,以进一步提高分类性能,如[32]所示。我们还针对不同的分类组件进行消融研究。为了训练proposal网络,我们使用0.1的学习率。对于分类网络,我们将学习速率设置为0.001。对于这两种情况,我们使用0.9和5e-5重量衰减的动量。
4.2. ActivityNet Dataset
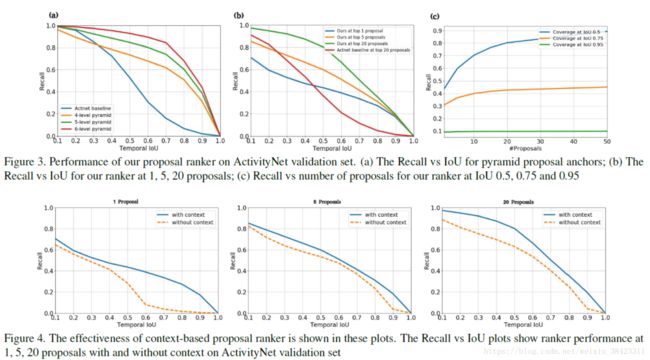
proposal锚点:我们在时间金字塔内采样成对建议。 在图3(a)中,我们展示了三种不同级别的ActivityNet验证集上金字塔提议锚点的召回情况。 该图显示了使用这种金字塔可以获得的理论最佳召回率。 请注意,即使是共有64个proposal的4级金字塔,覆盖范围也已经比挑战中提供的基准要好,该proposal使用了90个。 这确保我们的proposal排名表现很高,proposal数量较少。
排名器的表现:我们用不同数量的proposal评估我们的排名。 图3(b)显示了在各种重叠门槛下与前1名,前5名和前20名proposal的平均召回率。 即使在使用一个proposal时,当重叠阈值大于0.5时,我们的排名优于ActivityNet的proposal基准的显着幅度。 通过排名前20的proposal,我们的排名可以排除金字塔proposal锚点的大部分表现。我们还通过在proposal数量变化时测量召回率来评估排名的表现(如图3(c)所示)。 在20个proposal中,召回率在IoU 0.5增加到90%。 在较高的IoU中,增加proposal数量并不会显着提高召回率。
时间背景的有效性:在图4中,我们比较了排序器在没有时间上下文情况下的性能。 在没有上下文的情况下,仅使用最佳建议,在高IoU(IoU> 0.5)时召回率显着下降。 这表明为了精确定位边界,时间上下文是至关重要的。 使用排名前5位和前20位的proposal,没有上下文,召回会稍微恶化。 这是预料之中的,因为随着proposal数量的增加,与地面事实重叠的可能性更高。 因此,使用单一proposal召回结果的信息量最大。

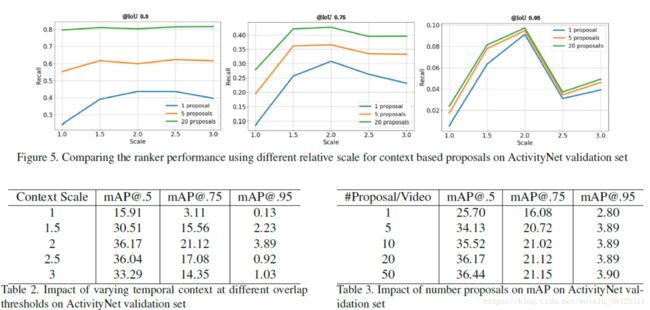

在图5中,我们观察到性能提高到了2级。我们在ActivityNet验证集上评估不同比例级别的性能。在表2中,我们展示了不同时间上下文在不同重叠阈值下的影响,这证实了我们声称添加更多时间上下文会损害性能,但根本不使用上下文会降低性能的幅度。例如,将标度从2改为3只会使性能下降3%,但将其从1.5降低为1会使mAP分别降低15%和12%。
proposal数量的影响我们还评估了proposal数量对检测性能的影响。 表3表明,我们的方法不需要大量的proposal来改善其最高的MAP。 消融研究我们进行了一系列消融研究,以评估在我们的分类模型中使用的每个组分的重要性。 表4考虑三个部分:“B”代表“使用双线性汇集”; “F”代表“使用流量”,“G”代表“使用全球先期”。 从表格中我们可以看到,每个组件在提高性能方面起着重要作用。
我们将我们的方法与CVPR 2016挑战期间提交的最新方法[36,20,32,32]进行了比较。 我们在评估服务器上提交结果以测量测试集的性能。 在0.5重叠的情况下,我们的方法只比5789更差[36]。 但是,此方法针对0.5重叠进行了优化,并且在测量0.75或0.95重叠处的mAP时,其性能显着降低(至2%)。 尽管在[31]中使用了使用双向LSTM的帧级预测,但当以0.75重叠测量mAP时,我们的性能会更好。 这是因为[31]仅执行在多个检测阈值处获得的连续分段的简单分组,而不是基于提议的方法。 因此,它可能在较长的行动部分表现更差。
4.3. The THUMOS14 Dataset
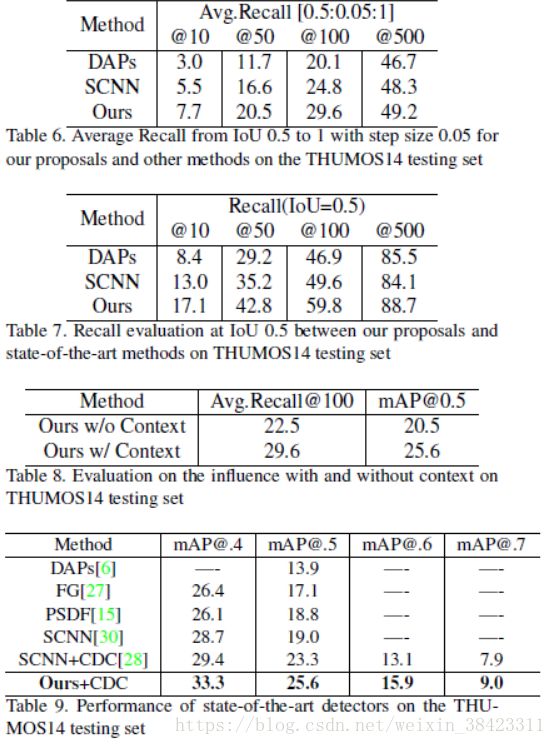
在表8中,很明显,当使用一对上下文窗口作为输入时,提议排名器性能显着提高。因此,在视频中使用上下文特征进行本地化非常重要,这在以前的最先进的活动检测方法中基本上被忽略了。与最先进的技术进行比较使用现成的分类器和我们的建议,我们还在THUMOS14上展现了显着的检测性能改进。
在这里,我们比较我们的时间背景网络与DAP [6],PSDF [15],FG [27] SCNN [30]和CDC [28]。我们将CDC最初使用的S-CNN提案替换为我们的提案。为了对CDC的检测结果进行评分,我们将我们的提案分数与CDC的分类评分相乘。我们表明,我们的提议进一步惠及CDC,并在不同的重叠阈值下始终提高检测性能。
5.相关工作

我们展示了TCN的一些定性结果,有和没有上下文。 请注意,只显示前5个提案。 地面事实以蓝色显示,而预测以绿色显示。 很明显,当不使用上下文时,多个提议存在于地面真实间隔的边界内或者仅存在于地面真实间隔的边界处。 因此,尽管位置接近实际间隔(当不使用上下文时),但边界不准确。 因此,当计算检测指标时,这些附近的检测结果被标记为误报,导致平均精度下降。 但是,当使用上下文时,与未使用上下文的情况相比,提议边界显着更准确