erlang练习题
文章目录
- 资料
- erlong 中文手册
- 一些不同(keng)
- 1
- 1、将列表中的integer,float,atom转成字符串并合并成一个字个字符串:[1,a,4.9,"sdfds"] 结果:"1a4.9sdfds"(禁用++ -- append concat实现)
- erl文件
- 输入erlong shell测试
- 2、得到列表或元组中的指定位的元素 {a,g,c,e} 第1位a [a,g,c,e] 第1位a(禁用erlang lists API实现)
- erl文件
- 输入erlong shell测试
- 3、根据偶数奇数过淲列表或元组中的元素(禁用API实现)
- erl文件
- 输入erlong shell测试
- 4、便用匿名函数对列表奇数或偶数过淲
- erl文件
- 输入erlong shell测试
- 5、计算数字列表[1,2,3,4,5,6,7,8,9]索引N到M的和
- erl文件
- 输入erlong shell测试
- 6、查询List1是为List2的前缀(禁用string API实现)
- erl文件
- 输入erlong shell测试
- 7、逆转列表或元组(禁用lists API实现)
- erl文件
- 输入erlong shell测试
- 8、对列表进行排序
- erl文件
- 9、对数字列表进行求和再除以指定的参数,得到商余
- erl文件
- 输入erlong shell测试
- 10、获得当前的堆栈???
- 11、获得列表或元组中的最大最小值(禁用API实现)
- erl文件
- 输入erlong shell测试
- erl文件
- 输入erlong shell测试
- 12、查找元素在元组或列表中的位置
- erl文件
- 输入erlong shell测试
- 14、判断A列表([3,5,7,3])是否在B列表([8,3,5,3,5,7,3,9,3,5,6,3])中出现,出现则输出在B列表第几位开始
- erl文件
- 输入erlong shell测试
- 15、{8,5,2,9,6,4,3,7,1} 将此元组中的奇数进行求和后除3的商(得值A),并将偶数求和后剩3(得值B),然后求A+B结果
- erl文件
- 输入erlong shell测试
- 16、在shell中将unicode码显示为中文???
- 17、传入列表L1=[K|_]、L2=[V|_]、L3=[{K,V}|_],L1和L2一一对应,L1为键列表,L2为值列表,L3存在重复键,把L3对应键的值加到L2???
- erl文件
- 输入erlong shell测试
- 18、删除或查询元组中第N个位置的值等于Key的tuple(禁用lists API实现)
- erl文件
- 输入erlong shell测试
- 19、对一个字符串按指定符字劈分(禁用string API实现)
- erl文件
- 输入erlong shell测试
- 对字符串的理解
- 函数中字符串列表
- 20、合并多个列表或元组
- 21、{5,1,8,7,3,9,2,6,4} 将偶数剩以它在此元组中的偶数位数, 比如,8所在此元组中的偶数位数为1,2所在此元组中的偶数位数为2
- erl文件
- 输入erlong shell测试
- 22、排序[{"a",5},{"b",1},{"c",8},{"d",7},{"e",3},{"f",9},{"g",2},{"h",6},{"i",4}], 以元组的值进行降序 优先用API
- erl文件
- 输入erlong shell测试
- 23、{8,5,2,9,6,4,3,7,1} 将此元组中的奇数进行求和
- erl文件
- 输入erlong shell测试
- 24、传入任意I1、I2、D、Tuple四个参数,检查元组Tuple在索引I1、I2位置的值V1、V2,如果V1等于V2则删除V1,把D插入V2前面,返回新元组,如果V1不等于V2则把V2替换为V1,返回新元组。注意不能报异常,不能用try,不满足条件的,返回字符串提示
- erl文件
- 输入erlong shell测试
- 25、删除列表或元组中全部符合指定键的元素
- erl文件
- 输入erlong shell测试
- 26、替换列表或元组中第一个符合指定键的元素
- erl文件
- 输入erlong shell测试
- 27、将指定的元素插入到列表中指定的位置,列表中后面的元素依次向后挪动
- erl文件
- 输入erlong shell测试
- 28、对[6,4,5,7,1,8,2,3,9]进行排序(降序--冒泡排序)或API排序
- 选择排序
- erl文件
- 输入erlong shell测试
- 冒泡排序
- erl文件
- 30、移除元组或列表中指定位置的元素
- erl文件
- 输入erlong shell测试
- 31、指定列表第几位之后的数据进行反转。如:指定[2,3,5,6,7,2]第3位后进行反转(谢绝一切API(lists:concat,lists:reverse等)、++、--方法)
- erl文件
- 输入erlong shell测试
- 32、使用“匿名函数”检查列表的每个元素是否符合传入的最大最小值(都是闭区间)
- 1
- erl文件
- 输入erlong shell测试
- 2
- 3.原来阔以匿名函数传参进去(`・ω・´)
- erl文件
- 输入erlong shell测试
- 33、获得列表或元组的最大最小值
- erl文件
- 输入erlong shell测试
- 34、成生指定数量元组,每个元素为随机integer元素, 元素不能有相同的
- erl文件
- 输入erlong shell测试
- 35、对一个int进行位移操作,取出0到16位的数据,16到32位的数据,输出这两个数
- erl文件
- 输入erlong shell测试
- 36、输入A(元子列表),B(数值列表)两个相同长度的参数进行随机匹配(要求字母为Key,数值为Value),支持指定的Key和Value在一组
- erl文件
- 输入erlong shell测试
- 37、对相同类型的数据进行拼接,如binary(<<1,2>><<3,4>> =<<1,2,3,4>>) tuple({a,b},{c} ={a,b,c}) list([10],[20] =[10,20])
- erl文件
- 输入erlong shell测试
- 38、将列表中相同key的值进行合并,[{a,1},{b,2},{c,3},{b,4},{b,5},{c,6},{d,7},{d,8}]
- erl文件
- 输入erlong shell测试
- 39、Erlang程序设计(第2版)中5.3节的count_characters方法有错,自行修改证
- erl文件
- 输入erlong shell测试
资料
erlong 中文手册
阔以用来查找erlong的库函数的用法:erlong 中文手册
一些不同(keng)
1
好像if后面的判断条件(guard关卡)不能是函数,case后的就行
1、将列表中的integer,float,atom转成字符串并合并成一个字个字符串:[1,a,4.9,“sdfds”] 结果:“1a4.9sdfds”(禁用++ – append concat实现)
erl文件
-module(lpfmerge).
-export([getstr/1,to_string/1]).
getstr([])->"";
getstr([H|T])->
if
is_atom(H)->[atom_to_list(H)|getstr(T)];
is_integer(H)->[integer_to_list(H)|getstr(T)];
is_float(H)->[float_to_list(H,[{decimals,1}])|getstr(T)]; %注意这里小数点保留一位
is_list(H)->[H|getstr(T)]
end.
to_string(L)->binary_to_list(list_to_binary(getstr(L))).
最后一句就是先转换成 二进制文件 然后再转换回list,不然就会成下面第四个运行代码那样是分开的
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\1> erl
Eshell V8.3 (abort with ^G)
1> c(lpfmerge).
{ok,lpfmerge}
2> L=[1,a,4.9,"sdfds"].
[1,a,4.9,"sdfds"]
3> lpfmerge:to_string(L).
"1a4.9sdfds"
4> lpfmerge:getstr(L).
["1","a","4.9","sdfds"]
5>
2、得到列表或元组中的指定位的元素 {a,g,c,e} 第1位a [a,g,c,e] 第1位a(禁用erlang lists API实现)
erl文件
先用2个参数的把元组都统一弄成列表 然后再处理
-module(q2).
-export([getPosVal/2]).
getPosVal([],Pos)->[]; %列表为空
getPosVal({},Pos)->{}; %元组为空
getPosVal(L,Pos)->
if
is_tuple(L)->
getPosVal(tuple_to_list(L),Pos); %如果是元组,就先转换成列表
true->
getPosVal(L,Pos,1)
end.
getPosVal([H|T],Pos,Index)when Pos==Index->H;
getPosVal([H|T],Pos,Index)->getPosVal(T,Pos,Index+1).
输入erlong shell测试
PS D:\lpf\lpf练习题\已完成\2> erl
Eshell V10.7 (abort with ^G)
1> c(q2).
q2.erl:4: Warning: variable 'Pos' is unused
q2.erl:5: Warning: variable 'Pos' is unused
q2.erl:14: Warning: variable 'T' is unused
q2.erl:15: Warning: variable 'H' is unused
{ok,q2}
2> L=[10,20,30,40,50,60].
[10,20,30,40,50,60]
3> q2:getPosVal(L,3).
30
4>
3、根据偶数奇数过淲列表或元组中的元素(禁用API实现)
erl文件
-module(lpffilter).
-export([filter/1]).
filter([])->[];
filter({})->{};
filter([H|T])->
if
is_tuple(H)
->filter(tuple_to_list(H)); %之前写成 ->filter([tuple_to_list(H)|T]);就不对,为啥喃?
(H rem 2)=:=0
->[H|filter(T)];
true
->filter(T)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\已完成\3> erl
Eshell V8.3 (abort with ^G)
1> c(lpffilter).
{ok,lpffilter}
2> L=[1,2,3,4,5,6,7,8,{9,10,11,12},13,14,15,16].
[1,2,3,4,5,6,7,8,{9,10,11,12},13,14,15,16]
3> lpffilter:filter(L).
[2,4,6,8,10,12]
4>
4、便用匿名函数对列表奇数或偶数过淲
erl文件
-module(q4).
-export([filter/2]).
filter(F,[H|T])->
case F(H) of
true->[H|filter(F,T)];
false->filter(F,T)
end;
filter(F,[])->[].
输入erlong shell测试
PS D:\lpf\lpf练习题\已完成\4> erl
Eshell V10.7 (abort with ^G)
1> c(q4).
q4.erl:16: Warning: variable 'F' is unused
{ok,q4}
2> L=[1,2,3,4,5,6,7,8].
[1,2,3,4,5,6,7,8]
3> F=fun(X)->(X rem 2) =:=0 end.
#Fun5、计算数字列表[1,2,3,4,5,6,7,8,9]索引N到M的和
erl文件
我是写的for循环来做的,计算的是 [ I , J ) [I,J) [I,J) 左闭右开区间的和
用if判断:
-module(lpffor).
-export([for/4]).
for(Index,I,J,[H|T])->
if
(Index>=I) and (Index<J)
->H+for(Index+1,I,J,T);
true
->for(Index+1,I,J,T)
end;
for(Index,I,J,[])->0.
用 when 判断:
-module(lpffor).
-export([for/4]).
for(Index,I,J,[H|T]) when (Index>=I) , (Index<J)
->H+for(Index+1,I,J,T);
for(Index,I,J,[H|T])
->for(Index+1,I,J,T);
for(Index,I,J,[])
->0.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\5> erl
Eshell V8.3 (abort with ^G)
1> c(lpffor).
lpffor.erl:11: Warning: variable 'I' is unused
lpffor.erl:11: Warning: variable 'Index' is unused
lpffor.erl:11: Warning: variable 'J' is unused
{ok,lpffor}
2> L=[10,20,30,40,50,60,70,80,90].
[10,20,30,40,50,60,70,80,90]
3> lpffor:for(1,2,7,L).
200
4>
6、查询List1是为List2的前缀(禁用string API实现)
erl文件
这是看的别人的代码,原来export中只写在外面调用的函数就行,里面用到的其他函数可以不写,比如这里用了is_prefix2
还有就是,要想对列表操作的话,参数就要写成,(H|T)这种,这样写的话又不能表示整体的这个列表了,所以这里要弄两个
-module(q6).
-export([is_prefix/2]).
is_prefix([], L2) -> false;
is_prefix([], []) -> false;
is_prefix(L1, L2) ->
if
length(L1) >= length(L2)
-> false;
true
-> is_prefix2(L1,L2)
end.
is_prefix2([H1|T1],[H2|T2]) ->
if
(H1 == H2 andalso T1 == [] )
-> true;
H1 == H2
-> is_prefix2(T1,T2);
H1 /= H2
-> false;
T1 == []
-> true
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\6> erl
Eshell V8.3 (abort with ^G)
1> c(q6).
q6.erl:4: Warning: variable 'L2' is unused
q6.erl:5: Warning: this clause cannot match because a previous clause at line 4 always matches
{ok,q6}
2> L1=[1,2,3].
[1,2,3]
3> L2=[1,2,3,4,5].
[1,2,3,4,5]
4> L3=[2,3,4].
[2,3,4]
5> q6:is_prefix(L1,L2).
true
6>
7、逆转列表或元组(禁用lists API实现)
erl文件
-module(lpfReverse).
-export([lpfreverse/1,lpfreverse/2]).
lpfreverse(L)->lpfreverse(L,[]).
lpfreverse([H|T],Reversed)->lpfreverse(T,[H|Reversed]);
lpfreverse([],Reversed)->Reversed.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\7> erl
Eshell V8.3 (abort with ^G)
1> c(lpfReverse).
{ok,lpfReverse}
2> L=[1,3,5,7,9].
[1,3,5,7,9]
3> lpfReverse:lpfreverse(L).
[9,7,5,3,1]
4>
8、对列表进行排序
erl文件
书上的快排例子,erlong写快排好简洁呀ヽ( ̄▽ ̄)ノ
-module(lpfsort).
-export([sort/1]).
sort([])->[];
sort([Mid|T])
->sort([X||X<-T , X<Mid]) ++ [Mid] ++ sort([X||X<-T , X>=Mid]).
9、对数字列表进行求和再除以指定的参数,得到商余
erl文件
-module(q9).
-export([get_sum_rem/2]).
get_sum_rem(L,Num)
->{sum(L)/Num,sum(L) rem Num}.
sum([H|T])->H+sum(T);
sum([])->0.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\9> erl
Eshell V8.3 (abort with ^G)
1> c(q9).
q9.erl: no such file or directory
error
2> c(q9).
{ok,q9}
3> L=[10,20,30,40,50].
[10,20,30,40,50]
4> q9:get_sum_rem(L,7).
{21.428571428571427,3}
5> 150/7.
21.428571428571427
6>
10、获得当前的堆栈???
这个是直接在shell里写
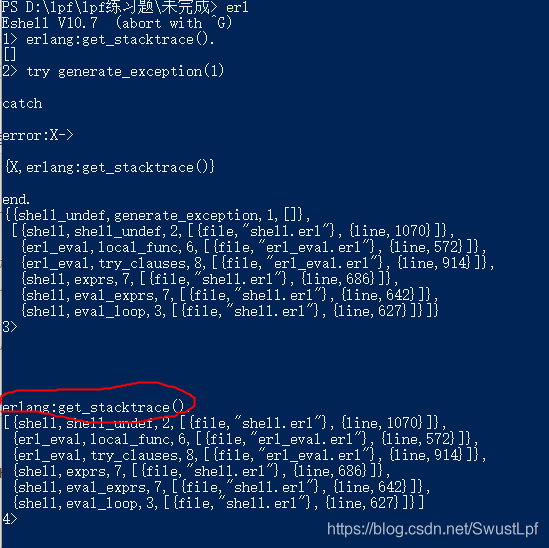
大概就是写一个会产生错误的函数,比如 generate_exception(1),因为看下面错误信息的第一行 shell_undef ,意思是没有定义这个函数
然后就会报错,调用get_stacktrace()就能得到栈的信息了
PS D:\lpf\lpf练习题\未完成\10> erl
Eshell V8.3 (abort with ^G)
1> try generate_exception(1)
catch
error:X->
{X,erlang:get_stacktrace()}
end.
{{shell_undef,generate_exception,1,[]},
[{shell,shell_undef,2,[{file,"shell.erl"},{line,1061}]},
{erl_eval,local_func,6,[{file,"erl_eval.erl"},{line,562}]},
{erl_eval,try_clauses,8,[{file,"erl_eval.erl"},{line,904}]},
{shell,exprs,7,[{file,"shell.erl"},{line,686}]},
{shell,eval_exprs,7,[{file,"shell.erl"},{line,641}]},
{shell,eval_loop,3,[{file,"shell.erl"},{line,626}]}]}
2>
好像是必须要error一哈才得行,直接用这个函数没得反应得
11、获得列表或元组中的最大最小值(禁用API实现)
这里是最大值最小值分开的:
erl文件
-module(lpfMaxMin).
-export([lpfmax/1,lpfmin/1]).
lpfmax([H|T])->lpfmax(T,H). %这里为啥要用. 因为是调用2个参数的lpfmax了,不属于原来的了
lpfmax([],Res)->Res; %只剩一个
lpfmax([H|T],Res)when H>Res->lpfmax(T,H); %比Res大就选他
lpfmax([H|T],Res)->lpfmax(T,Res). %不然不选
lpfmin([H|T])->lpfmin(T,H).
lpfmin([],Res)->Res;
lpfmin([H|T],Res)when H<Res->lpfmin(T,H);
lpfmin([H|T],Res)->lpfmin(T,Res).
输入erlong shell测试
PS D:\lpf\lpf练习题\已完成\11> erl
Eshell V8.3 (abort with ^G)
1> c(lpfMaxMin).
lpfMaxMin.erl:8: Warning: variable 'H' is unused
lpfMaxMin.erl:17: Warning: variable 'H' is unused
{ok,lpfMaxMin}
2> L=[5,9,8,7,25,3,2,1].
[5,9,8,7,25,3,2,1]
3> lpfMaxMin:lpfmax(L).
25
4> lpfMaxMin:lpfmin(L).
1
5>
然后是一起返回的写法:
erl文件
-module(q11).
-export([max_min/1]).
max_min([H|T])->max_min([H|T],H,H). %最开始写成max_min(L)->max_min(L,Max,Min) 会报错说 :variable 'Max' is unbound以及variable 'Min' is unbound
max_min([],Max,Min)->{Max,Min};
max_min([H|T],Max,Min)->
if
(H>Max) and (H<min)
->max_min(T,H,H);
(H>Max)
->max_min(T,H,Min);
(H<Min)
->max_min(T,Max,H);
true
->max_min(T,Max,Min)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\已完成\11> erl
Eshell V8.3 (abort with ^G)
1> c(q11).
q11.erl:4: variable 'Max' is unbound
q11.erl:4: variable 'Min' is unbound
error
2> c(q11).
{ok,q11}
3> L=[5,9,8,7,25,3,2,1].
[5,9,8,7,25,3,2,1]
4> q11:max_min(L).
{25,1}
5>
12、查找元素在元组或列表中的位置
erl文件
-module(q12).
-export([get_index/2]).
get_index(L, Tofind) ->get_index(L, Tofind, 1). %调用3个参数的get_index
get_index([],Tofind,Index)->null; %递归边界
get_index([H|T],Tofind,Index)->
if H==Tofind
->Index;
true
->get_index(T,Tofind,Index+1)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\12> erl
Eshell V8.3 (abort with ^G)
1> c(q12).
q12.erl:6: Warning: variable 'Index' is unused
q12.erl:6: Warning: variable 'Tofind' is unused
{ok,q12}
2> L=[10,20,{33,34,35},40,50].
[10,20,{33,34,35},40,50]
3> q12:get_index(L,{33,34,35}).
3
4>
q12:get_index(L,40).
4
5>
14、判断A列表([3,5,7,3])是否在B列表([8,3,5,3,5,7,3,9,3,5,6,3])中出现,出现则输出在B列表第几位开始
erl文件
-module(q14).
-export([is_in/2]).
is_in(L1,L2)->is_in(L1,L2,1,1).
is_in([],L2,Index1,Index2)->false;
is_in(L1,[],Index1,Index2)->false;
is_in([H1|T1],[H2|T2],Index1,Index2)->
if
(H1==H2) and (T1==[])
->{true,Index2-Index1+1}; %完全匹配成功
H1==H2
->is_in(T1,T2,Index1+1,Index2+1); %部分匹配成功
true
->is_in([H1|T1],T2,Index1,Index2+1) %没有匹配成功
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\14> erl
Eshell V8.3 (abort with ^G)
1>
c(q14).
q14.erl:6: Warning: variable 'Index1' is unused
q14.erl:6: Warning: variable 'Index2' is unused
q14.erl:6: Warning: variable 'L2' is unused
q14.erl:7: Warning: variable 'Index1' is unused
q14.erl:7: Warning: variable 'Index2' is unused
q14.erl:7: Warning: variable 'L1' is unused
{ok,q14}
2> L1=[3,5,7,3].
[3,5,7,3]
3> L2=[8,3,5,3,5,7,3,9,3,5,6,3].
[8,3,5,3,5,7,3,9,3,5,6,3]
4> q14:is_in(L1,L2).
{true,4}
5> q14:is_in(L2,L1).
false
6>
15、{8,5,2,9,6,4,3,7,1} 将此元组中的奇数进行求和后除3的商(得值A),并将偶数求和后剩3(得值B),然后求A+B结果
erl文件
-module(q15).
-export([lpfsum/1]).
lpfsum(L)->lpfsum(tuple_to_list(L),0,0). %注意输入进来的是元组,还要转换成列表
lpfsum([],Odd,Even)->(Odd/3+Even*3);
lpfsum([H|T],Odd,Even)->
if
(H rem 2)==1
->lpfsum(T,Odd+H,Even);
true
->lpfsum(T,Odd,Even+H)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\15> erl
Eshell V8.3 (abort with ^G)
1> c(q15).
{ok,q15}
2> L={8,5,2,9,6,4,3,7,1}.
{8,5,2,9,6,4,3,7,1}
3> q15:lpfsum(L).
68.33333333333333
4>
16、在shell中将unicode码显示为中文???
17、传入列表L1=[K|]、L2=[V|]、L3=[{K,V}|_],L1和L2一一对应,L1为键列表,L2为值列表,L3存在重复键,把L3对应键的值加到L2???
思路还是用的库函数 proplists:append_values 来从L3中找重复的键值
erl文件
-module(q17).
-export([key_val/3]).
key_val(L1,L2,L3)->key_val(L1,L2,L3,[]).
key_val([],[],L3,Res)->io:format("Res=~w~n",[Res]),Res; %这里不懂为什么,都已经得到最后的答案Res了,但是为啥返回的Res是个奇怪的东西"<61"
key_val([H1|T1],[H2|T2],L3,Res)->
TP1=proplists:append_values(H1,L3), %用库函数从L3中查找这个key并且得到所有的值
TP2=lists:sum(TP1), %返回的是列表,所以要求和
%io:format("TP2=~w~n",[TP2]), %试着打印出来看对不对
key_val(T1,T2,L3,lists:append(Res,[H2+TP2])). %加上L2中的值
输入erlong shell测试
不知道为啥会有个奇怪的返回值 “<61”
PS D:\lpf\lpf练习题\未完成\17> erl
Eshell V10.7 (abort with ^G)
1> c(q17).
q17.erl:8: Warning: variable 'L3' is unused
{ok,q17}
2> L1=[a,b,c].
[a,b,c]
3> L2=[10,20,30].
[10,20,30]
4> L3=[{a,23},{b,34},{a,27},{c,78}].
[{a,23},{b,34},{a,27},{c,78}]
5> q17:key_val(L1,L2,L3).
Res=[60,54,108]
"<6l"
6>
哦原来是因为[60,54,108]本身就代表"<6l",可能是某个编码,不信输入进shell试试
PS D:\lpf> erl
Eshell V10.7 (abort with ^G)
1> L=[60,54,108].
"<6l"
2> L.
"<6l"
3>
18、删除或查询元组中第N个位置的值等于Key的tuple(禁用lists API实现)
erl文件
-module(q18).
-export([select/3,delete/3]).
select(L,N,Key)->select(L,N,Key,1).
select([{K,V}|T],N,Key,Index)->
if
(K==Key) and (Index==N)->
{K,V};
(K==Key)->
select(T,N,Key,Index+1);
true->
select(T,N,Key,Index)
end.
delete(L,N,Key)->delete(L,N,Key,1).
delete([{K,V}|T],N,Key,Index)->
if
(K==Key) and (Index==N)->
T; %找到就返回后面的列表,当前的数不要了
(K==Key)->
[{K,V}|delete(T,N,Key,Index+1)];
true->
[{K,V}|delete(T,N,Key,Index)]
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\18> erl
Eshell V10.7 (abort with ^G)
1> c(q18).
{ok,q18}
2> L=[{a,10},{b,21},{a,10},{b,22},{b,23},{c,30}].
[{a,10},{b,21},{a,10},{b,22},{b,23},{c,30}]
3> q18:select(L,3,b).
{b,23}
4> q18:delete(L,3,b).
[{a,10},{b,21},{a,10},{b,22},{c,30}]
5>
19、对一个字符串按指定符字劈分(禁用string API实现)
erl文件
-module(q19).
-export([string_div/2]).
string_div(Str,[X])->string_div(Str,[X],[],[]).
%假如调用函数的时候是:
%string_div("abcabcabc","b")
%此时"abcabcabc"=[97,98,99,97,98,99,97,98,99]
%"b"=[98]
%所以H和X才是同样类型的才能比较
string_div([H|T],[X],Res1,Res2)-> %Res1是保存最后的答案,Res2是保存没有逗号连着的字符串
if H/=X->
string_div(T,[X],Res1,Res2++[H]);
true->
string_div(T,[X],Res1++[Res2],[])
end;
string_div([],[X],Res1,Res2)-> %递归边界
Res1++[Res2].
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\19> erl
Eshell V10.7 (abort with ^G)
1> c(q19).
q19.erl:20: Warning: variable 'X' is unused
{ok,q19}
2> q19:string_div("abcabcabc","b").
["a","ca","ca","c"]
3>
对字符串的理解
PS D:\lpf\lpf练习题\未完成\19> erl
Eshell V10.7 (abort with ^G)
1>
L1=["ab","c"].
["ab","c"]
2> L2=["de"].
["de"]
3>
[L3]=L2. %把列表L2里的元素取出来,放到L3中
["de"]
4> L3. %L3就不是列表了
"de"
5>
L1++L2. %列表与列表相++,直接会用逗号相隔开
["ab","c","de"]
6>
L1++L3. %由于L3不是列表了,所以看成列表与单个的元素相++
["ab","c",100,101]
7>
看一个列表++不同的数的效果
L1++100
L1++[100]
L1++[[100]]
L1++[[[100]]]
L1=["ab","c"].
["ab","c"]
14>
L1++100.
["ab","c"|100] %++的不是列表,只是单个的元素
15>
L1++[100].
["ab","c",100] %++的是列表,正常操作
16>
L1++[[100]].
["ab","c","d"] %诶~多弄一层括号就变成字符串了
17>
L1++[[[100]]].
["ab","c",["d"]] %再多弄一层就没效果了
20> L1++[100,101].
["ab","c",100,101]
21> L1++[[100,101]]. %这样"d","e"就能连起了
["ab","c","de"]
22> L1++[[100],[101]]. %这样"d","e"就不会连起
["ab","c","d","e"]
函数中字符串列表
在函数中好像又不一样了
Res++H
Res++[H]
Res++[[H]]
这三者的不同之处:
-module(strtest).
-export([str1/1,str2/1,str3/1]).
str1(Str)->str1(Str,[]).
str1([],Res)->Res;
str1([H|T],Res)->
str1(T,Res++H). %H是个元素,不能直接与列表++
%输出结果:
% ** exception error: bad argument
% in operator ++/2
% called as 97 ++ 98
% in call from strtest:str1/2 (strtest.erl, line 7)
str2(Str)->str2(Str,[]).
str2([],Res)->Res;
str2([H|T],Res)->
str2(T,Res++[H]). %[H]就变成了单元素的列表,可以++
%输出结果:"abcde"
str3(Str)->str3(Str,[]).
str3([],Res)->Res;
str3([H|T],Res)->
str3(T,Res++[[H]]). %这。。。。。
%输出结果:["a","b","c","d","e"]
PS D:\lpf\lpf练习题\未完成\19> erl
Eshell V10.7 (abort with ^G)
1> c(strtest).
{ok,strtest}
2> Str="abcde".
"abcde"
3>
strtest:str1(Str).
** exception error: bad argument
in operator ++/2
called as 97 ++ 98
in call from strtest:str1/2 (strtest.erl, line 7)
4>
strtest:str2(Str).
"abcde"
5>
strtest:str3(Str).
["a","b","c","d","e"]
6>
20、合并多个列表或元组
21、{5,1,8,7,3,9,2,6,4} 将偶数剩以它在此元组中的偶数位数, 比如,8所在此元组中的偶数位数为1,2所在此元组中的偶数位数为2
erl文件
-module(q21).
-export([multiEven/1]).
multiEven(L)->binary_to_list(list_to_binary(multiEven(L,1))). %不转成二进制再转回来的话就会有很多中括号,我也不知道该怎么办
multiEven([],Index)->[];
multiEven([H|T],Index)->
if
(H rem 2)==0
->[H*Index,multiEven(T,Index+1)];
true
->multiEven(T,Index)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\21> erl
Eshell V8.3 (abort with ^G)
1> c(q21).
q21.erl:6: Warning: variable 'Index' is unused
{ok,q21}
2> L=[5,1,8,7,3,9,2,6,4].
[5,1,8,7,3,9,2,6,4]
3> q21:multiEven(L).
[8,4,18,16]
4>
22、排序[{“a”,5},{“b”,1},{“c”,8},{“d”,7},{“e”,3},{“f”,9},{“g”,2},{“h”,6},{“i”,4}], 以元组的值进行降序 优先用API
erl文件
-module(q22).
-export([sort/1]).
sort(L)->lists:keysort(2,L). %用lists里面的keysort,好像只能升序
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\22> erl
Eshell V8.3 (abort with ^G)
1>
c(q22).
{ok,q22}
2> L=[{"a",5},{"b",1},{"c",8},{"d",7},{"e",3},{"f",9},{"g",2},{"h",6},{"i",4}].
[{"a",5},
{"b",1},
{"c",8},
{"d",7},
{"e",3},
{"f",9},
{"g",2},
{"h",6},
{"i",4}]
3> q22:sort(L).
[{"b",1},
{"g",2},
{"e",3},
{"i",4},
{"a",5},
{"h",6},
{"d",7},
{"c",8},
{"f",9}]
4>
23、{8,5,2,9,6,4,3,7,1} 将此元组中的奇数进行求和
erl文件
-module(q23).
-export([sumT/1]).
sumT(L)->sum(tuple_to_list(L)). %元组换成列表
sum([])->0;
sum([H|T])->
if
(H rem 2)==1
->H+sum(T);
true
->sum(T)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\23> erl
Eshell V8.3 (abort with ^G)
1> c(q23).
{ok,q23}
2> L={8,5,2,9,6,4,3,7,1}.
{8,5,2,9,6,4,3,7,1}
3> q23:sumT(L).
25
4>
24、传入任意I1、I2、D、Tuple四个参数,检查元组Tuple在索引I1、I2位置的值V1、V2,如果V1等于V2则删除V1,把D插入V2前面,返回新元组,如果V1不等于V2则把V2替换为V1,返回新元组。注意不能报异常,不能用try,不满足条件的,返回字符串提示
erl文件
-module(q24).
-export([find/2,solve1/4,solve2/3,solve3/4,solve/4]).
find(L,Pos)->find(L,Pos,1).
find([H|T],Pos,Index)->
if Pos==Index->
H;
true->
find(T,Pos,Index+1)
end.
solve1(I1,I2,D,L)->solve1(I1,I2,D,L,1). %相等时候的操作
solve1(I1,I2,D,[],Index)->[];
solve1(I1,I2,D,[H|T],Index)->
if Index==I1->
solve1(I1,I2,D,T,Index+1); %把I1位置的删了
Index==I2->
[D,H|solve1(I1,I2,D,T,Index+1)]; %再把D添加到I2位置前面
true->
[H|solve1(I1,I2,D,T,Index+1)]
end.
solve2(V1,I2,L)->solve2(V1,I2,L,1). %不相等时候的操作
solve2(V1,I2,[H|T],Index)->
if Index==I2->
[V1|T];
true->
[H|solve2(V1,I2,T,Index+1)]
end.
solve3(I1,I2,D,L)-> %两个操作合并
V1=find(L,I1),
V2=find(L,I2),
if V1==V2->
solve1(I1,I2,D,L);
true->
solve2(V1,I2,L)
end.
solve(I1,I2,D,L)->list_to_tuple(solve3(I1,I2,D,tuple_to_list(L))). %因为题目要求是元组,所以转换哈
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\24> erl
Eshell V10.7 (abort with ^G)
1> c(q24).
q24.erl:18: Warning: variable 'D' is unused
q24.erl:18: Warning: variable 'I1' is unused
q24.erl:18: Warning: variable 'I2' is unused
q24.erl:18: Warning: variable 'Index' is unused
{ok,q24}
2> L={10,20,30,20,50,60}.
{10,20,30,20,50,60}
3> q24:solve(2,3,7,L).
{10,20,20,20,50,60}
4> q24:solve(2,4,7,L).
{10,30,7,20,50,60}
5>
25、删除列表或元组中全部符合指定键的元素
erl文件
%lists:keydelete 是删除某一个,这个函数是删除所有的,就是遍历一哈嘛
-module(q25).
-export([key_delete_all/2]).
key_delete_all(L,Key)->key_delete_all(L,Key,L).
key_delete_all([],Key,L)->L;
key_delete_all([{K,V}|T],Key,L)->
if
K==Key->
key_delete_all(T,Key,lists:keydelete(Key,1,L));
true->
key_delete_all(T,Key,L)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\25> erl
Eshell V10.7 (abort with ^G)
1> c(q25).
q25.erl:6: Warning: variable 'Key' is unused
q25.erl:7: Warning: variable 'V' is unused
{ok,q25}
2> T = [{a, 1}, {b, 2},{b,2}, {c, 3}, {d, 4}].
[{a,1},{b,2},{b,2},{c,3},{d,4}]
3> q25:key_delete_all(T,b).
[{a,1},{c,3},{d,4}]
4>
26、替换列表或元组中第一个符合指定键的元素
erl文件
%这个难道不是直接用库函数 lists:keyreplace 嘛???
-module(q26).
-export([replace_one/2]).
replace_one(L,{K,V})->lists:keyreplace(K,1,L,{K,V}).
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\26> erl
Eshell V10.7 (abort with ^G)
1> c(q26).
{ok,q26}
2> T = [{a, 1}, {b, 2},{b,2}, {c, 3}, {d, 4}].
[{a,1},{b,2},{b,2},{c,3},{d,4}]
3> q26:replace_one(T,{b,99}).
[{a,1},{b,99},{b,2},{c,3},{d,4}]
4>
27、将指定的元素插入到列表中指定的位置,列表中后面的元素依次向后挪动
erl文件
-module(q27).
-export([insert/3]).
insert(L,Pos,Val)->insert(1,[],L,Pos,Val).
insert(Index,Pre,[H|T],Pos,Val)->
if
Pos==0->
[Val]++[H]++T; %加在最前面
Index==Pos->
Pre++[H]++[Val]++T; %这里H和Val都是一个元素,所以要加中括号表示列表才能使用++操作
true->
insert(Index+1,Pre++[H],T,Pos,Val) %这里的H同样
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\27> erl
Eshell V10.7 (abort with ^G)
1> c(q27).
{ok,q27}
2> L=[1,2,3,4,5].
[1,2,3,4,5]
3> q27:insert(L,0,99).
[99,1,2,3,4,5]
4> q27:insert(L,3,99).
[1,2,3,99,4,5]
5>
28、对[6,4,5,7,1,8,2,3,9]进行排序(降序–冒泡排序)或API排序
选择排序
erl文件
-module(q28).
-export([sort/1]).
sort(L) ->sort([], L).
sort(NewList,[]) ->NewList;
sort(NewList, L) ->sort(NewList ++ [lists:min(L)], lists:delete(lists:min(L), L)).%选择最小的放在前面
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\28> erl
Eshell V10.7 (abort with ^G)
1> c(q28).
{ok,q28}
2> L=[6,4,5,7,1,8,2,3,9].
[6,4,5,7,1,8,2,3,9]
3> q28:sort(L).
[1,2,3,4,5,6,7,8,9]
4>
冒泡排序
erl文件
-module(q28).
-export([sort/1]).
sort(L)->for1(L,length(L)).
for1(L,0)->L;
for1(L,N)->for1(for2(L),N-1). %调用N次for2,相当于第一层循环
for2([L])->[L]; %这句就是只有一个元素的时候哇
for2([H1,H2|T])->
if
H1>H2->
[H2|for2([H1|T])];
true->
[H1|for2([H2|T])]
end.
30、移除元组或列表中指定位置的元素
erl文件
-module(q30).
-export([delete/2]).
delete(L,Pos)->delete(L,Pos,1).
delete([H|T],Pos,Index)->
if
Pos==Index->
T; %这里的T是个列表,如果写成[T],答案就变成[1,2,[4,5,6]],就会多中括号
true->
[H|delete(T,Pos,Index+1)]
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\30> erl
Eshell V10.7 (abort with ^G)
1> c(q30).
{ok,q30}
2> L=[1,2,3,4,5,6].
[1,2,3,4,5,6]
3> q30:delete(L,3).
[1,2,4,5,6]
4>
31、指定列表第几位之后的数据进行反转。如:指定[2,3,5,6,7,2]第3位后进行反转(谢绝一切API(lists:concat,lists:reverse等)、++、–方法)
erl文件
-module(q31).
-export([reverse/2]).
reverse(L,N)->reverse(L,N,1,[]).
reverse([H|T],N,Index,Res)->
if
Index<N->
[H|reverse(T,N,Index+1,[Res|H])]; %要用中括号括起来,不然前面一节就没了
true->
[H|reverse_all(T)]
end.
reverse_all(L)->reverse_all(L,[]). %这一段是全部翻转的代码
reverse_all([],Res)->Res;
reverse_all([H|T],Res)->
reverse_all(T,[H|Res]).
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\31> erl
Eshell V10.7 (abort with ^G)
1> c(q31).
{ok,q31}
2> L=[1,2,3,4,5,6].
[1,2,3,4,5,6]
3> q31:reverse(L,3).
[1,2,3,6,5,4]
4>
32、使用“匿名函数”检查列表的每个元素是否符合传入的最大最小值(都是闭区间)
1
我还以为是匿名函数作为参数传进去呢,原来就说用匿名函数判断一哈而已
话说怎么把匿名函数作为参数传进去呢?只知道lists:map()这个函数阔以接受匿名函数,但是那是库函数啊
erl文件
-module(q32).
-export([valid_max_min/3]).
valid_max_min([],Min,Max)->true;
valid_max_min([H|T],Min,Max)->
F=fun(X,Min,Max)->(X>=Min) andalso (X=<Max)end,
case F(H,Min,Max) of
false->
false;
true->
valid_max_min(T,Min,Max)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\32> erl
Eshell V10.7 (abort with ^G)
1> c(q32).
q32.erl:4: Warning: variable 'Max' is unused
q32.erl:4: Warning: variable 'Min' is unused
q32.erl:6: Warning: variable 'Max' shadowed in 'fun'
q32.erl:6: Warning: variable 'Min' shadowed in 'fun'
{ok,q32}
2> L=[1,2,3,4,5,6].
[1,2,3,4,5,6]
3> q32:valid_max_min(L,1,6).
true
4>
q32:valid_max_min(L,2,6).
false
5>
q32:valid_max_min(L,1,5).
false
6>
q32:valid_max_min(L,0,7).
true
7>
为什么case of 换成 if 就说 illegal guard expression
难道是 if 后面不能判断函数???
2
这个是不用匿名函数的
-module(q32).
-export([valid_max_min/3]).
valid_max_min([],Min,Max)->true;
valid_max_min([H|T],Min,Max)->
if
H<Min->
false;
H>Max->
false;
true->
valid_max_min(T,Min,Max)
end.
3.原来阔以匿名函数传参进去(`・ω・´)
erl文件
%匿名函数为:F=fun(X,Min,Max)->(X>=Min) andalso (X=<Max)end,
-module(qqq32).
-export([valid_max_min/4]).
valid_max_min([],Min,Max,F)->true;
valid_max_min([H|T],Min,Max,F)->
case F(H,Min,Max) of
false->
false;
true->
valid_max_min(T,Min,Max,F)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\已完成\32> erl
Eshell V10.7 (abort with ^G)
1> c(qqq32).
qqq32.erl:4: Warning: variable 'F' is unused
qqq32.erl:4: Warning: variable 'Max' is unused
qqq32.erl:4: Warning: variable 'Min' is unused
{ok,qqq32}
2> L=[1,2,3,4,5,6].
[1,2,3,4,5,6]
3> F=fun(X,Min,Max)->(X>=Min) andalso (X=)end.
#Fun 33、获得列表或元组的最大最小值
用库函数
erl文件
-module(q33).
-export([max_min/1]).
max_min(L)->[lists:max(L),lists:min(L)].
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\33> erl
Eshell V10.7 (abort with ^G)
1> c(q33).
{ok,q33}
2> q33:max_min([1,2,3,4,5,33,44,55]).
[55,1]
3>
34、成生指定数量元组,每个元素为随机integer元素, 元素不能有相同的
erl文件
-module(q34).
-export([lpfrand/1]).
lpfrand(N)->lpfrand(N,[]).
lpfrand(0,L)->L;
lpfrand(N,L)->
X=rand:uniform(100),
A=lists:member(X,L),
if
(A==false)
->lpfrand(N-1,lists:append(L,[X])); %如果X不在列表里,就把这个元素加进去
true
->lpfrand(N,L)
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\34> erl
Eshell V10.7 (abort with ^G)
1> c(q34).
{ok,q34}
2> q34:lpfrand(10).
[48,3,98,72,60,33,73,52,44,17]
3>
不重复的随机数有个不好理解的算法:这里是相关博客
35、对一个int进行位移操作,取出0到16位的数据,16到32位的数据,输出这两个数
erl文件
-module(q35).
-export([bin/1]).
bin(Number)->{(Number band 16#ffff0000) bsr 16,Number band 16#0000ffff}.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\35> erl
Eshell V8.3 (abort with ^G)
1> c(q35).
{ok,q35}
2> q35:bin(123456789).
{1883,52501}
3>
36、输入A(元子列表),B(数值列表)两个相同长度的参数进行随机匹配(要求字母为Key,数值为Value),支持指定的Key和Value在一组
erl文件
-module(q36).
-export([match/2]).
match(L1,L2)->match(L1,L2,1).
match(L1,L2,Index)when Index=<length(L1)->
Len=length(L1),
Pos1=rand:uniform(Len), %产生随机数
X1=lists:nth(Pos1,L1), %从L1中选
Pos2=rand:uniform(Len),
X2=lists:nth(Pos2,L2),
[{X1,X2}|match(L1,L2,Index+1)];
match(L1,L2,Index)->[]. %这句话用来递归结束,必须要,因为上面条件不满足的话就不会返回东西
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\36> erl
Eshell V10.7 (abort with ^G)
1> c(q36).
q36.erl:14: Warning: variable 'Index' is unused
q36.erl:14: Warning: variable 'L1' is unused
q36.erl:14: Warning: variable 'L2' is unused
{ok,q36}
2> L1=[a,b,c].
[a,b,c]
3> L2=[10,20,30].
[10,20,30]
4> q36:match(L1,L2).
[{c,10},{b,20},{c,10}]
5> q36:match(L1,L2).
[{a,10},{c,30},{a,20}]
6> q36:match(L1,L2).
[{c,30},{a,30},{c,10}]
7> q36:match(L1,L2).
[{b,30},{b,10},{c,10}]
8> q36:match(L1,L2).
[{c,10},{b,20},{a,10}]
9>
37、对相同类型的数据进行拼接,如binary(<<1,2>><<3,4>> =<<1,2,3,4>>) tuple({a,b},{c} ={a,b,c}) list([10],[20] =[10,20])
erl文件
%思路就是都转换成列表来加
-module(q37).
-export([lpfjoin/1]).
lpfjoin(L)->lpfjoin(L,[],[],[]).
lpfjoin([],Binary,[],[])->list_to_binary(Binary);
lpfjoin([],[],Tuple,[])->list_to_tuple(Tuple);
lpfjoin([],[],[],List)->List;
lpfjoin([H|T],Binary,Tuple,List)->
if
is_binary(H)->
Hb=binary_to_list(H), %转换成list
lpfjoin(T,Binary++[Hb],Tuple,List);
(is_tuple(H))->
Ht=tuple_to_list(H), %转换成list
lpfjoin(T,Binary,Tuple++Ht,List);
true
->lpfjoin(T,Binary,Tuple,List++H) %这里的H以及上面的Hb,Ht都已经是列表了,所以++的时候不用再加中括号
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\37> erl
Eshell V10.7 (abort with ^G)
1> c(q37).
{ok,q37}
2>
B=[<<1,2>>,<<3,4>>].
[<<1,2>>,<<3,4>>]
3> q37:lpfjoin(B).
<<1,2,3,4>>
4>
T=[{a,b},{c}].
[{a,b},{c}]
5> q37:lpfjoin(T).
{a,b,c}
6>
L=[[10],[20]].
["\n",[20]]
7> q37:lpfjoin(L).
[10,20]
8>
38、将列表中相同key的值进行合并,[{a,1},{b,2},{c,3},{b,4},{b,5},{c,6},{d,7},{d,8}]
erl文件
%思路就是把key和val分别装入KeyList,ValList,然后再合并
-module(q38).
-export([lpfmix/1]).
lpfmix(L)->lpfmix(L,[],[]).
mix([],[],Res)->Res;
mix([Hk|Tk],[Hv|Tv],Res)->
mix(Tk,Tv,Res++[{Hk,Hv}]). %合并到Res中
lpfmix([],KeyList,ValList)->mix(KeyList,ValList,[]);
lpfmix([{K,V}|T],KeyList,ValList)->
X=lists:member(K,KeyList),
if
X==true->
lpfmix(T,KeyList,ValList); %如果K在KeyList列表里面,就不管
true->
TP1=proplists:append_values(K,T), %KeyList里没有的话,就把所以键值为K的提取出来,返回是个列表
TP2=lists:sum(TP1)+V, %把返回的这个列表求和,并且加上当前K的键值V
lpfmix(T,KeyList++[K],ValList++[TP2]) %然后分别加进去
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\38> erl
Eshell V10.7 (abort with ^G)
1> c(q38).
{ok,q38}
2> L=[{a,1},{b,2},{c,3},{b,4},{b,5},{c,6},{d,7},{d,8}].
[{a,1},{b,2},{c,3},{b,4},{b,5},{c,6},{d,7},{d,8}]
3> q38:lpfmix(L).
[{a,1},{b,11},{c,9},{d,15}]
4>
39、Erlang程序设计(第2版)中5.3节的count_characters方法有错,自行修改证

erl文件
按道理来说这样应该是对的,
-module(q39).
-export([count_characters/1]).
count_characters(Str)->count_characters(Str,#{}).
count_characters([], X) ->X;
count_characters([H|T], #{H=>N}=X) ->
count_characters(T,X#{H:=N+1}); %如果匹配上了,就说明有,就要把N更新成N+1
count_characters([H|T],X)->
count_characters(T,X#{H=>1}). %不然就增加这个映射
但是我的映射不能模式匹配,也就是说会出现下面这种情况,说不合法的匹配 (illegal pattern)
PS D:\lpf\lpf练习题\未完成\39> erl
Eshell V10.7 (abort with ^G)
1> M1=#{a=>10,b=>20}.
#{a => 10,b => 20}
2> #{a=>X}=M1.
* 1: illegal pattern
3>
然后看其他童鞋写的并没有用模式匹配这种方法,用的是maps里的函数
-module(q39).
-export([count_characters/1]).
count_characters(Str)->count_characters(Str,#{}).
count_characters([], M) ->M;
count_characters([H|T], M) ->
case maps:is_key(H,M)of %看H是不是M中的key
false ->
count_characters(T, maps:put(H,1,M)); %如果不是,就在M中增加 H=>1 一个映射
true ->
Count = maps:get(H,M), %获得当前的映射的val
count_characters(T, maps:update(H,Count+1,M)) % H=>Count 这个 映射更新成 H=>Count+1
end.
输入erlong shell测试
PS D:\lpf\lpf练习题\未完成\39> erl
Eshell V10.7 (abort with ^G)
1> c(q39).
{ok,q39}
2> q39:count_characters("hello").
#{101 => 1,104 => 1,108 => 2,111 => 1}
3>